Download as PDF, PPTX













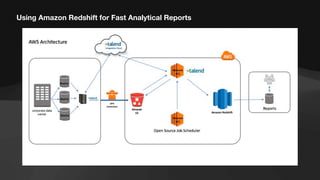


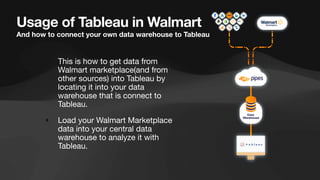
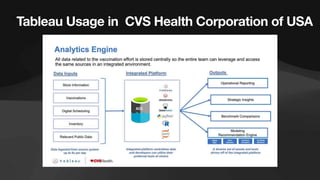

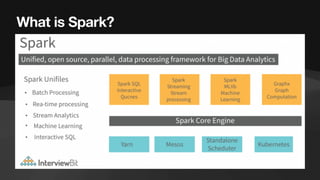




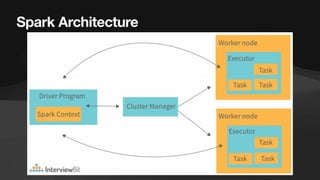
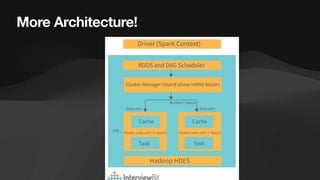
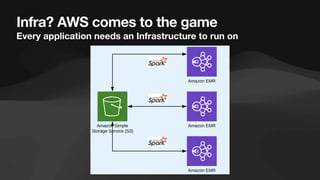
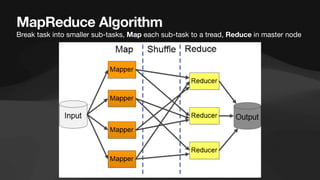
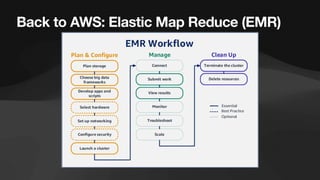




The document discusses the role of data engineers, their responsibilities, and the skills required to succeed in this in-demand field. It also covers the significance of cloud computing platforms, specifically Amazon Web Services (AWS), and introduces AWS Glue as a serverless data integration service. Additionally, it highlights key data engineering tools and technologies such as Amazon Redshift and Tableau, emphasizing their importance in data analysis and business intelligence.



































































