Download as PDF, PPTX






![Batch Processing
Data Lake
Batch
Processing
Pageviews
[url, timestamp]
[url, timestamp]
[url, timestamp]
[url, timestamp]
DBRollups
[url, hour,
count]
[url, hour,
count]
[url, hour,
count]
{url+hour :
count}
{url+hour :
count}
{url+hour :
count}
mapreduce mapreduce Data Analysis](https://image.slidesharecdn.com/dataintegration-170424084417/75/Data-Integration-19-2048.jpg)
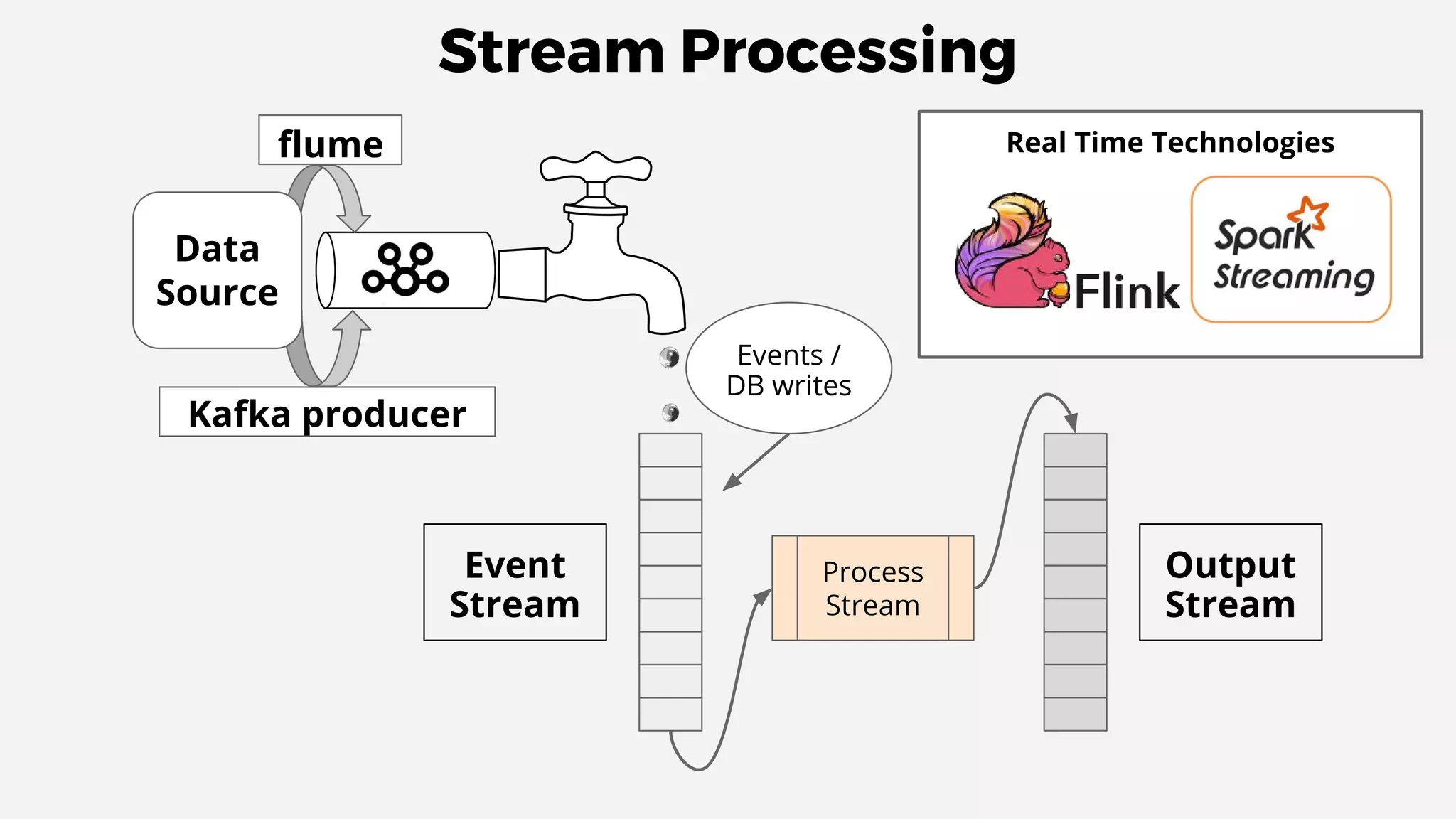

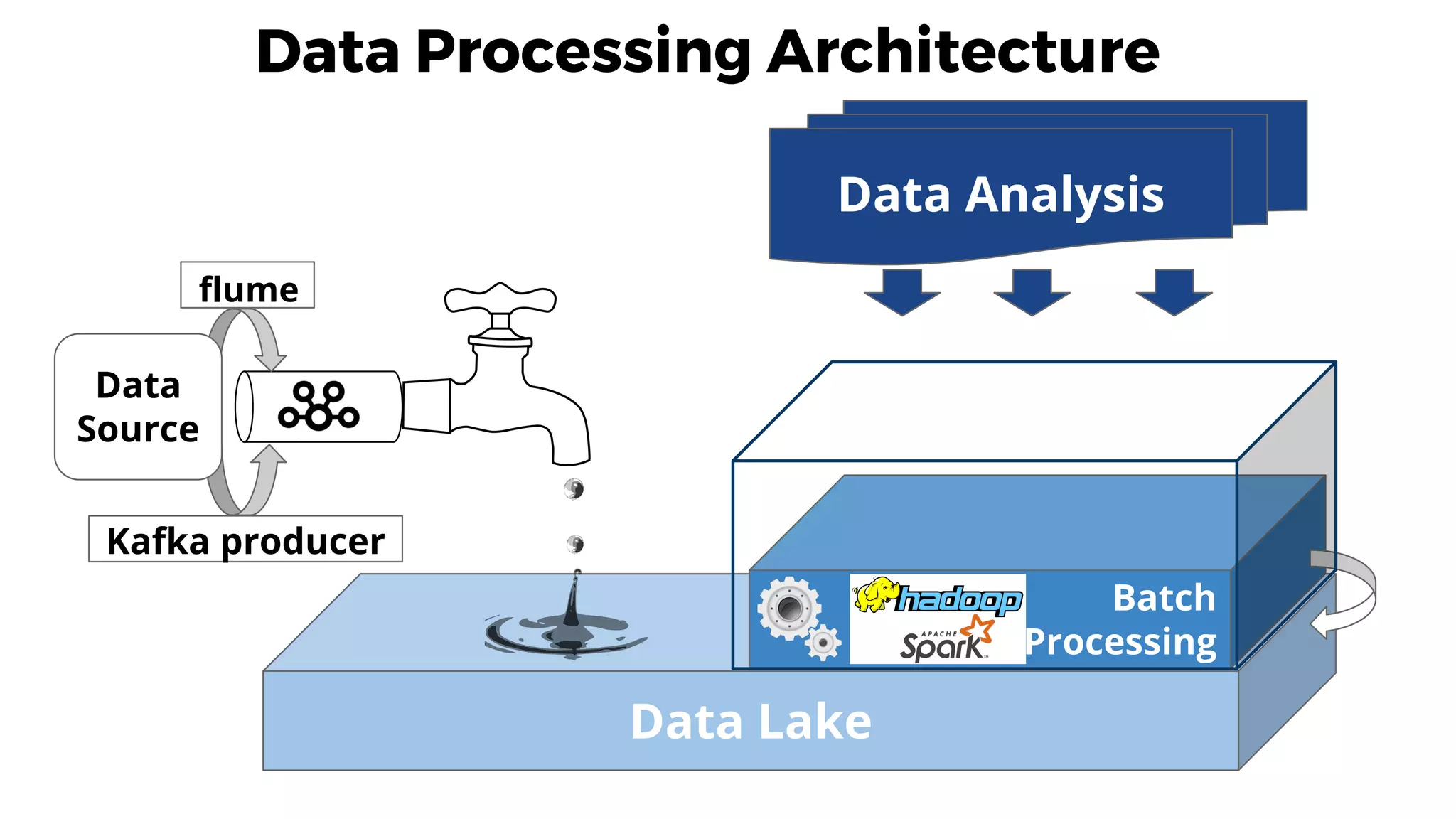
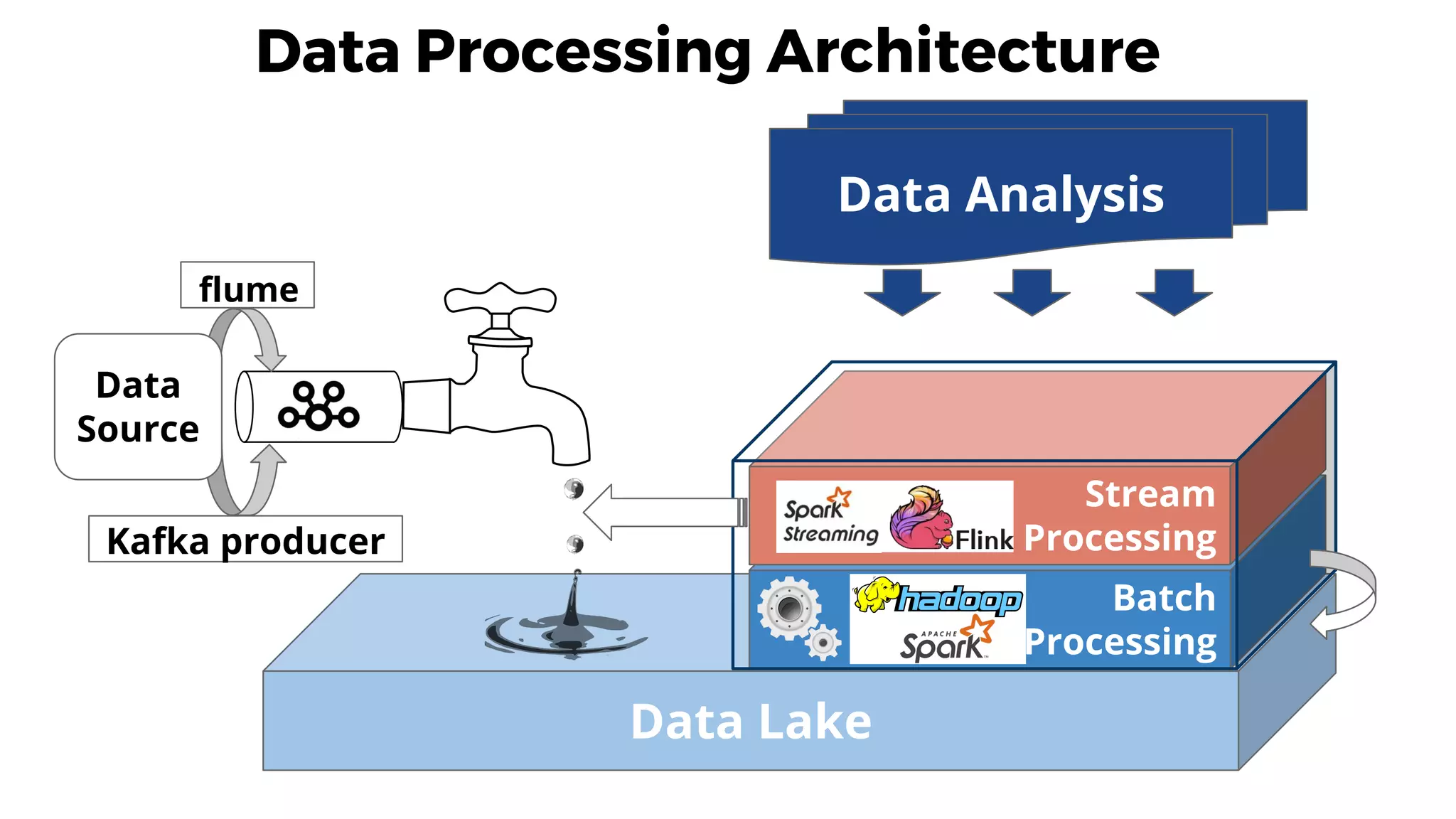
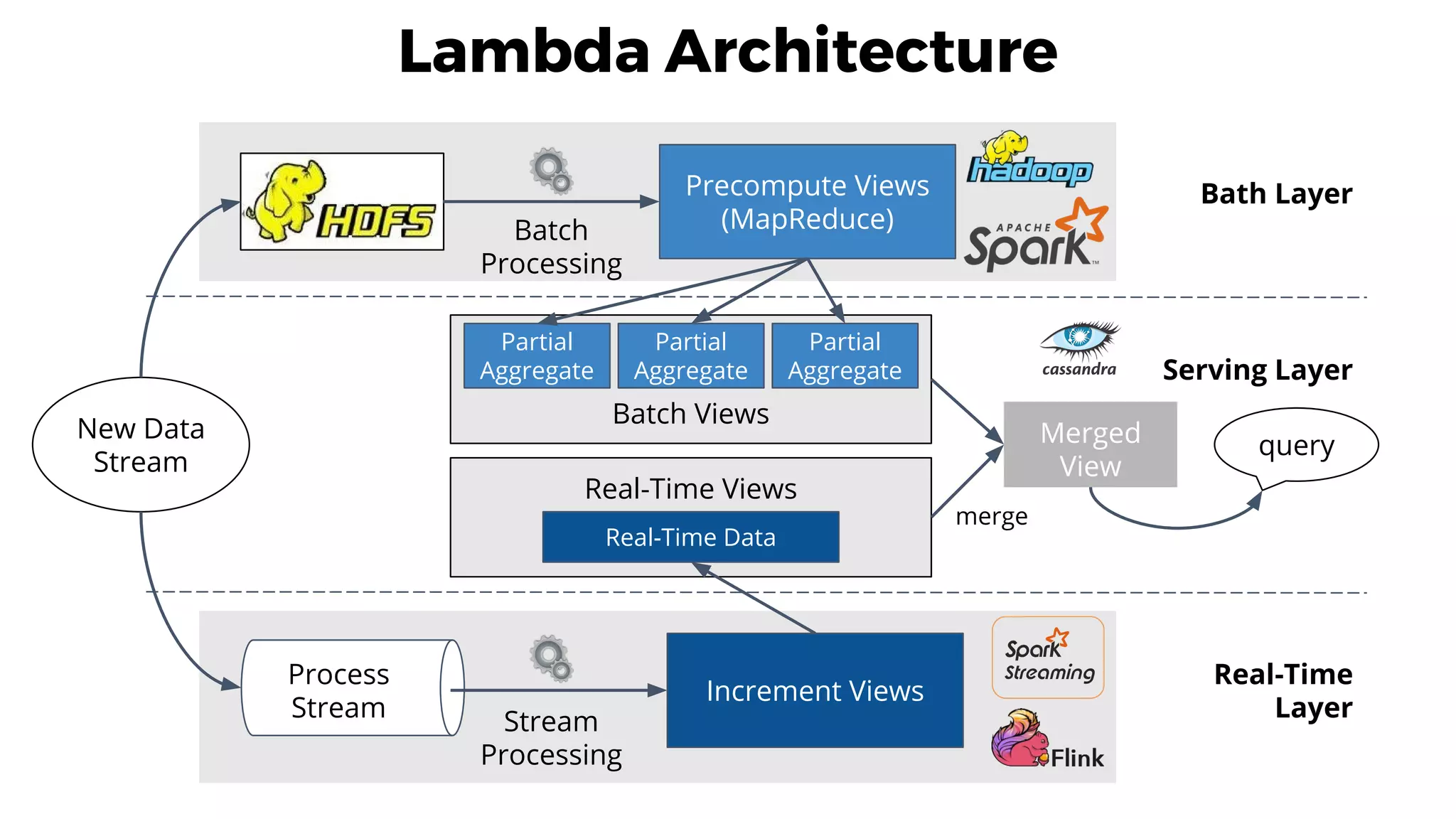

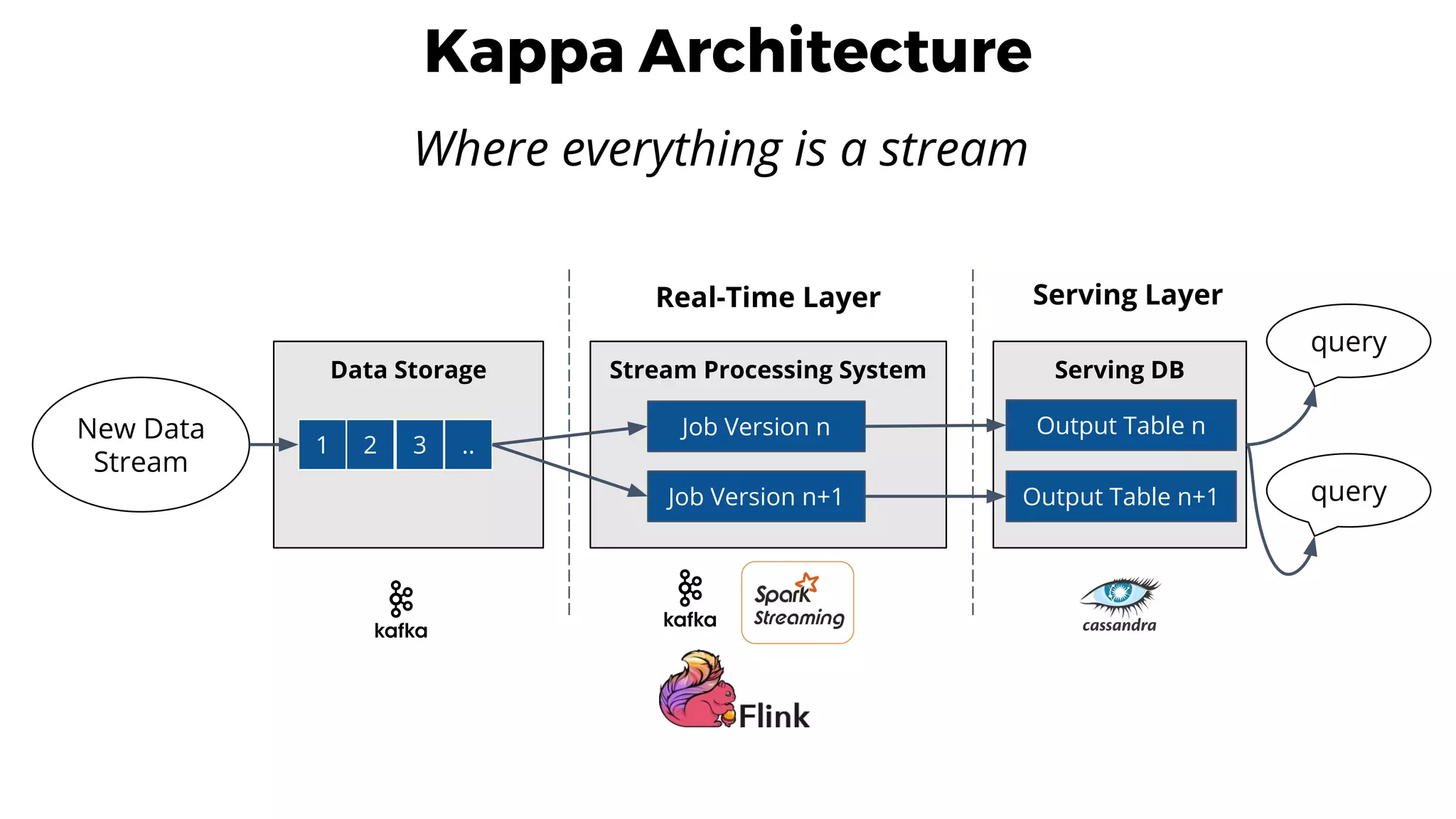



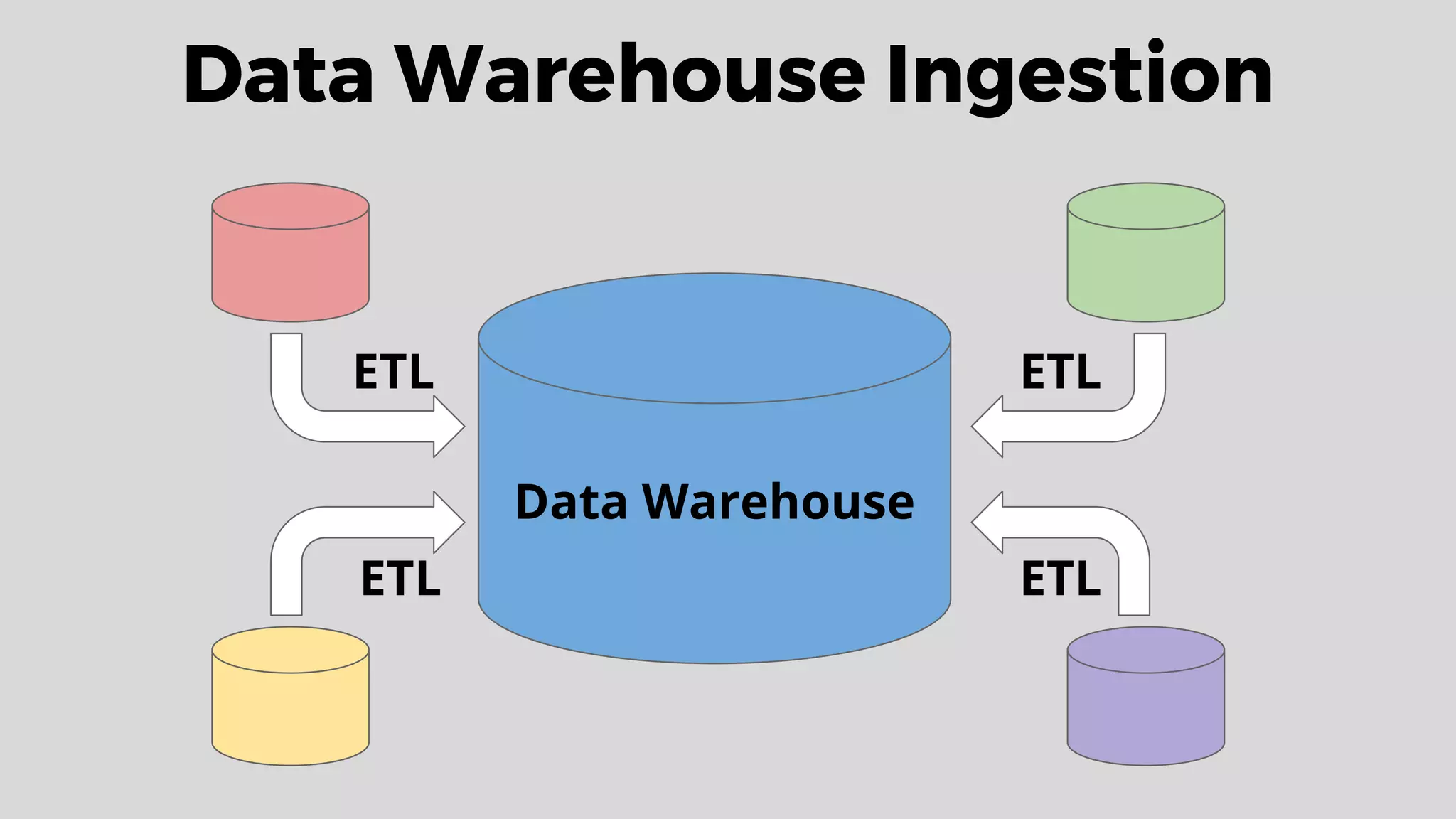
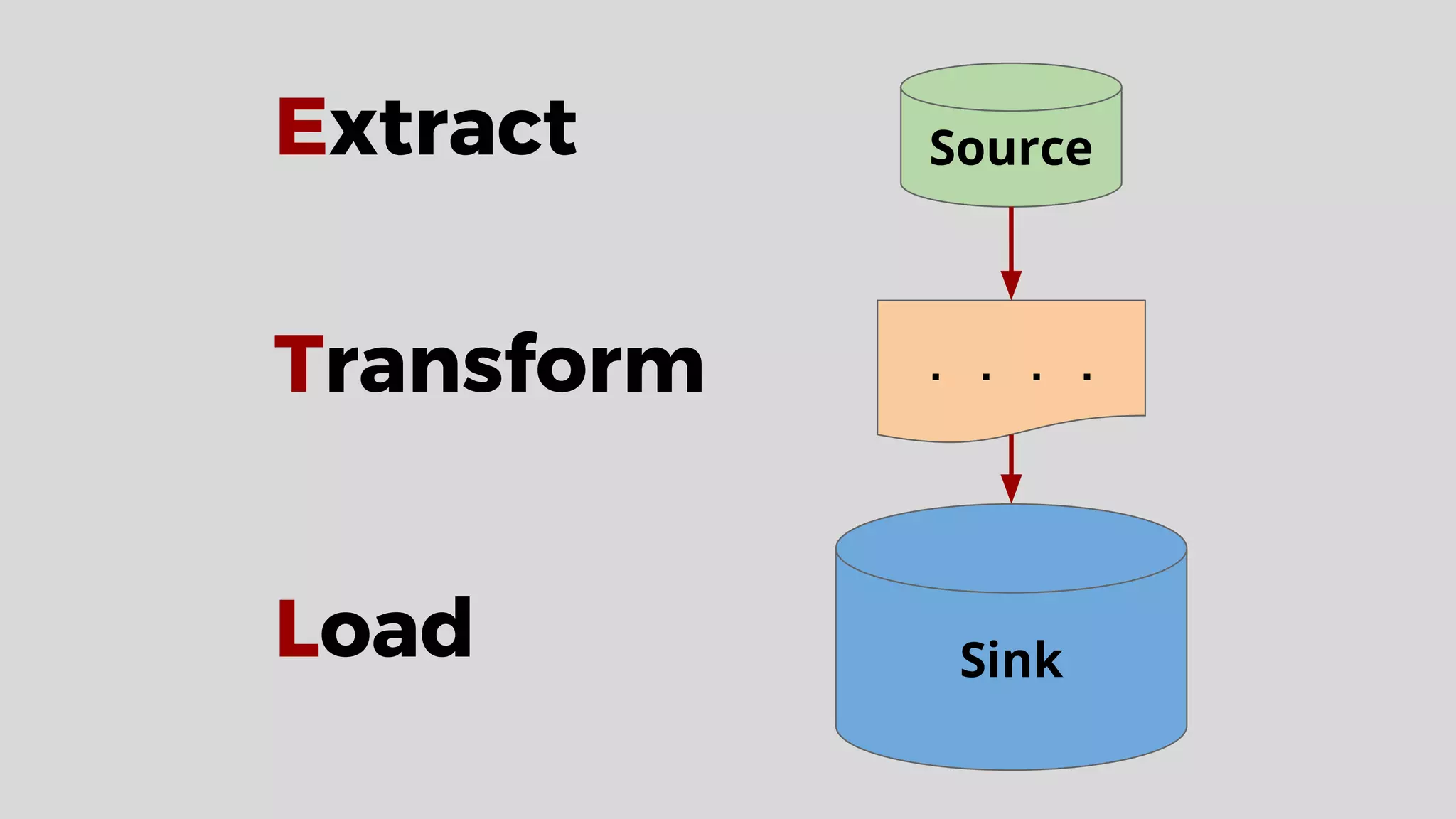
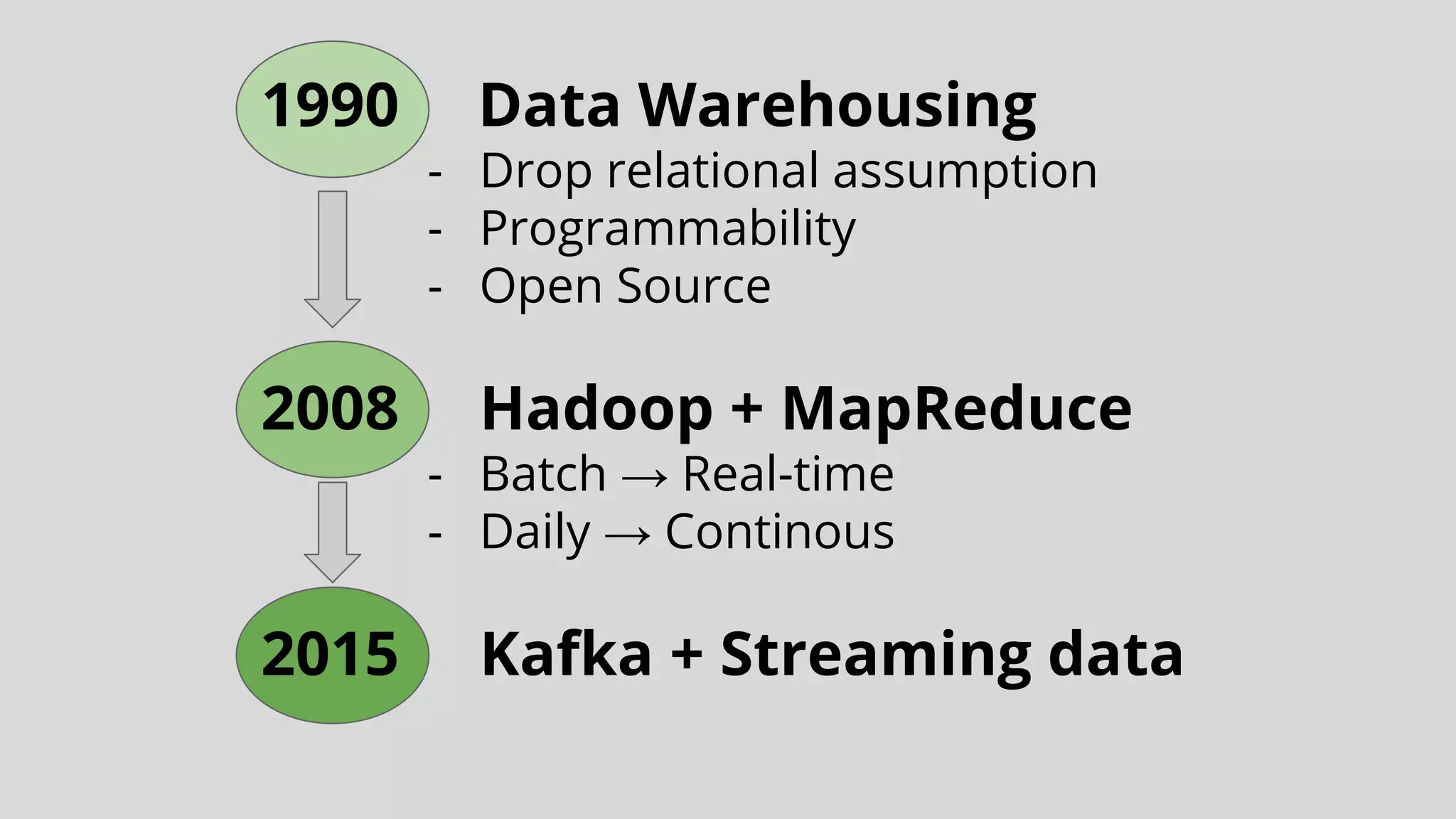
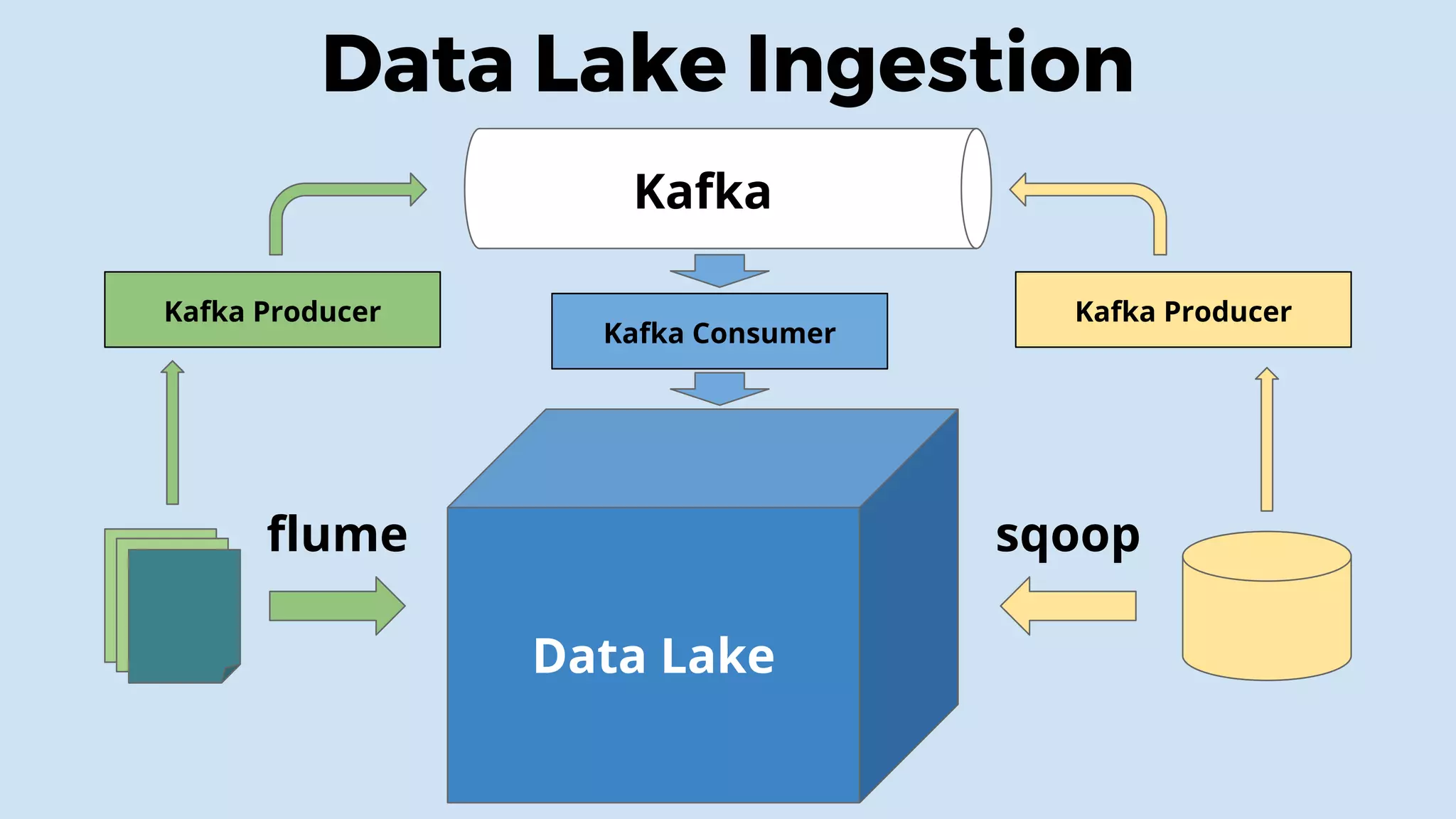
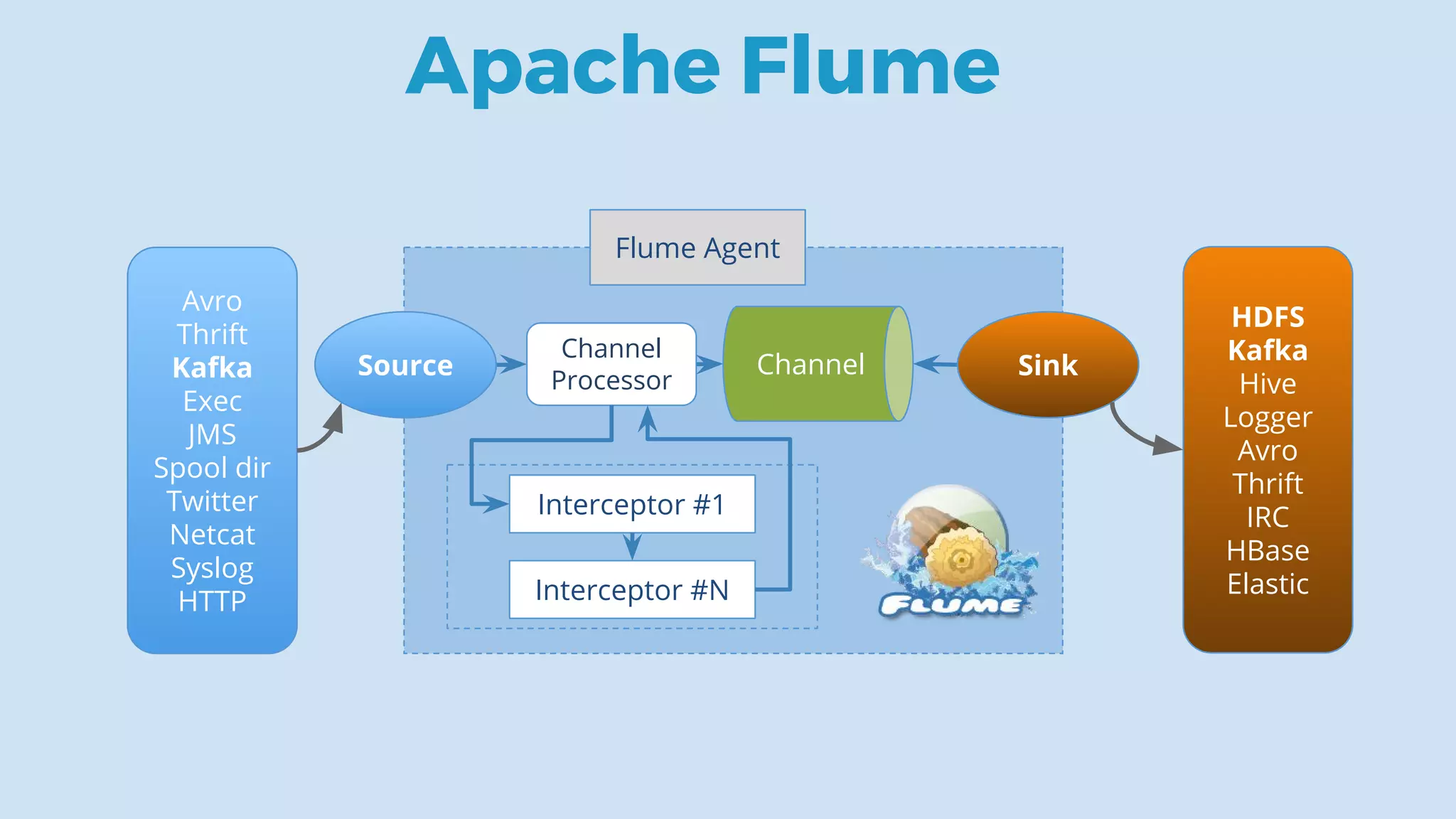
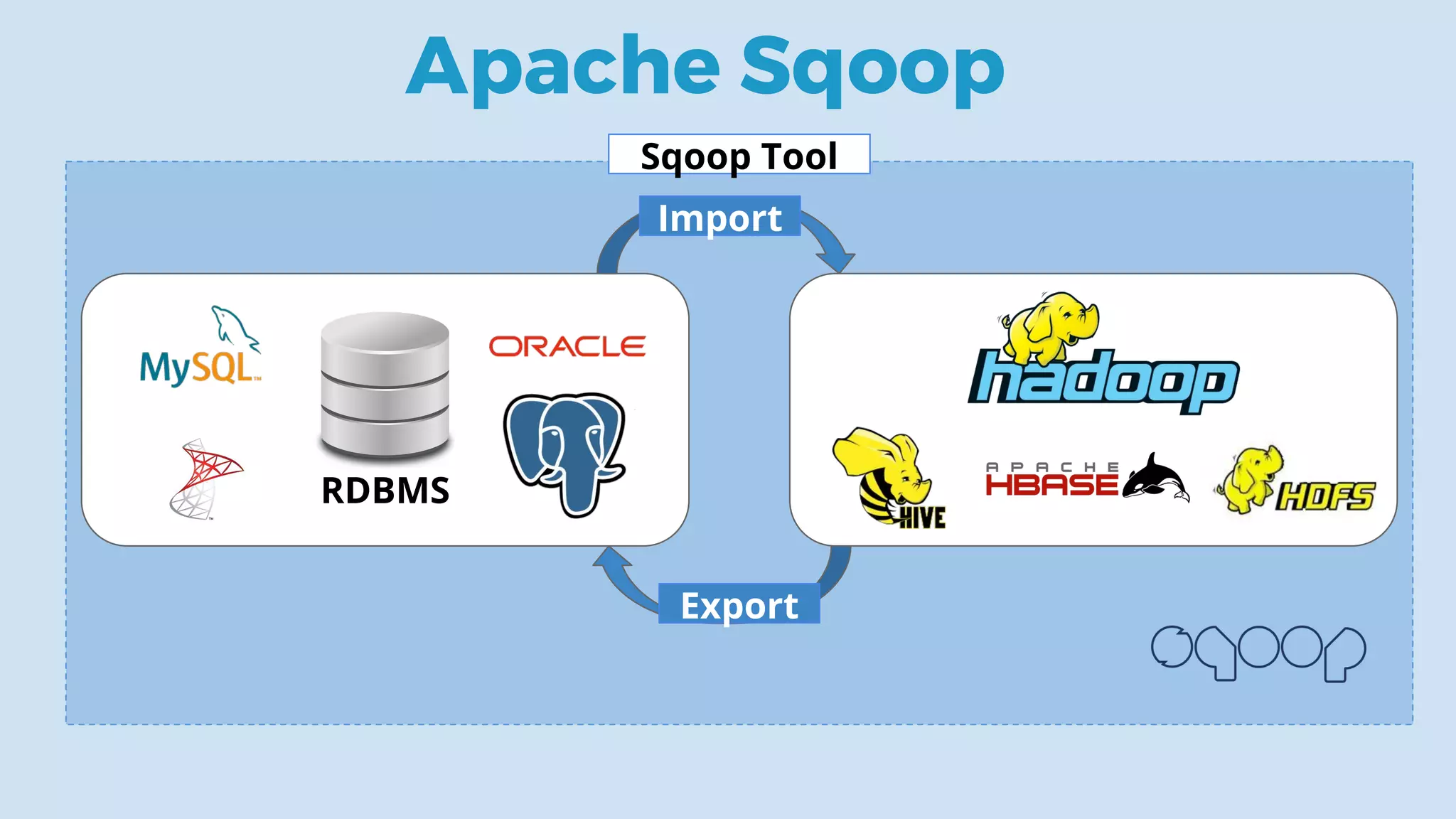
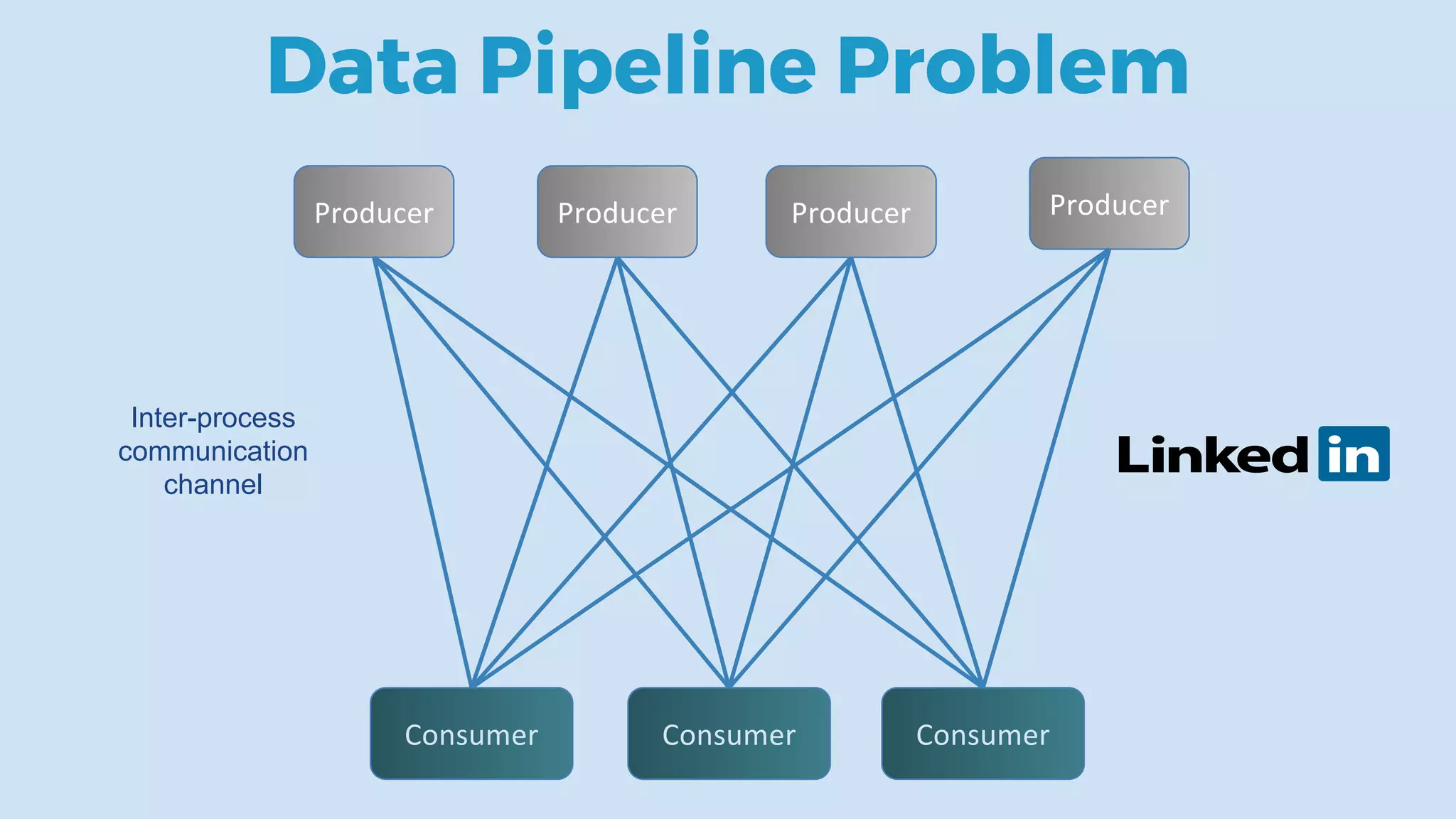
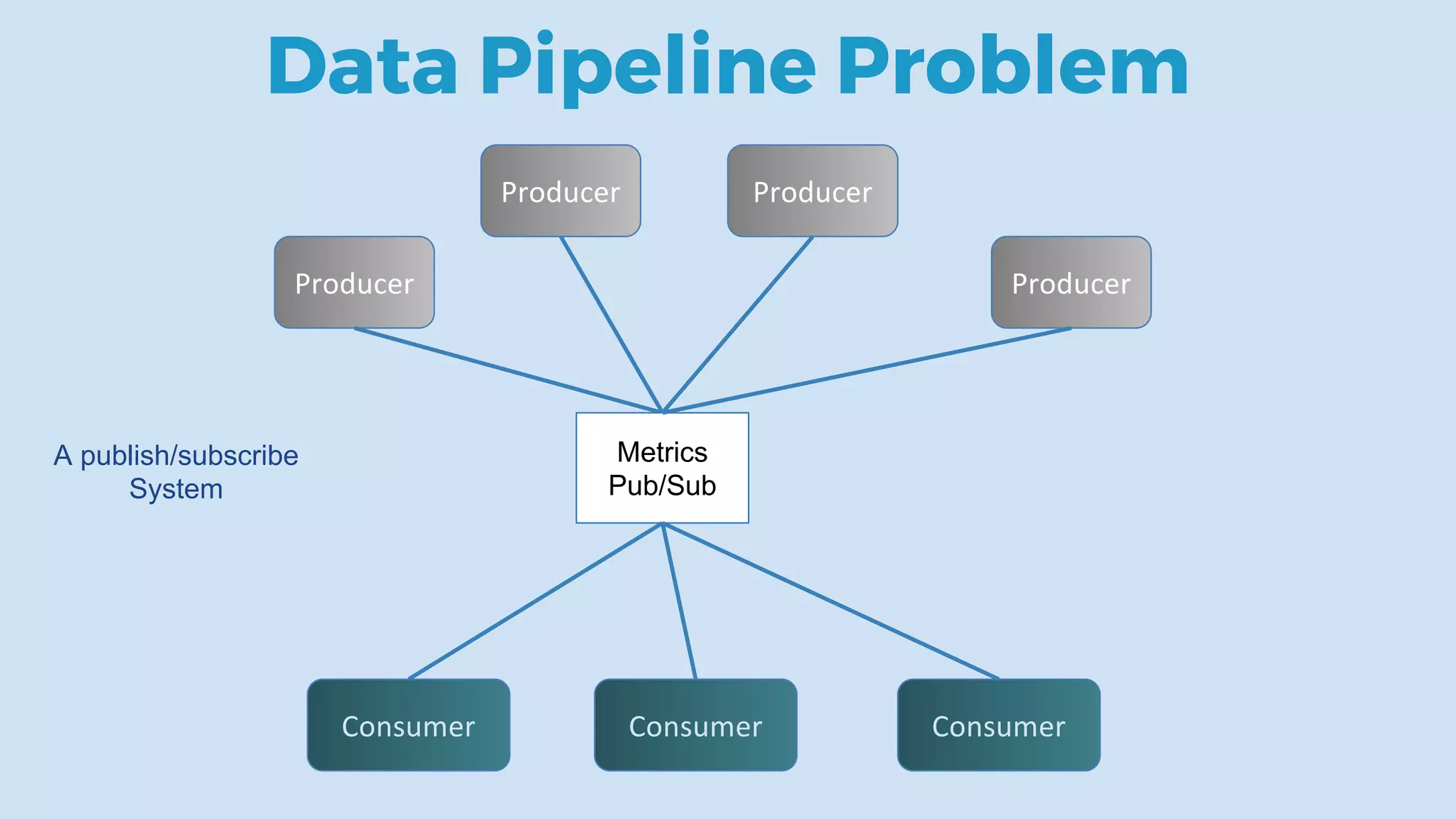
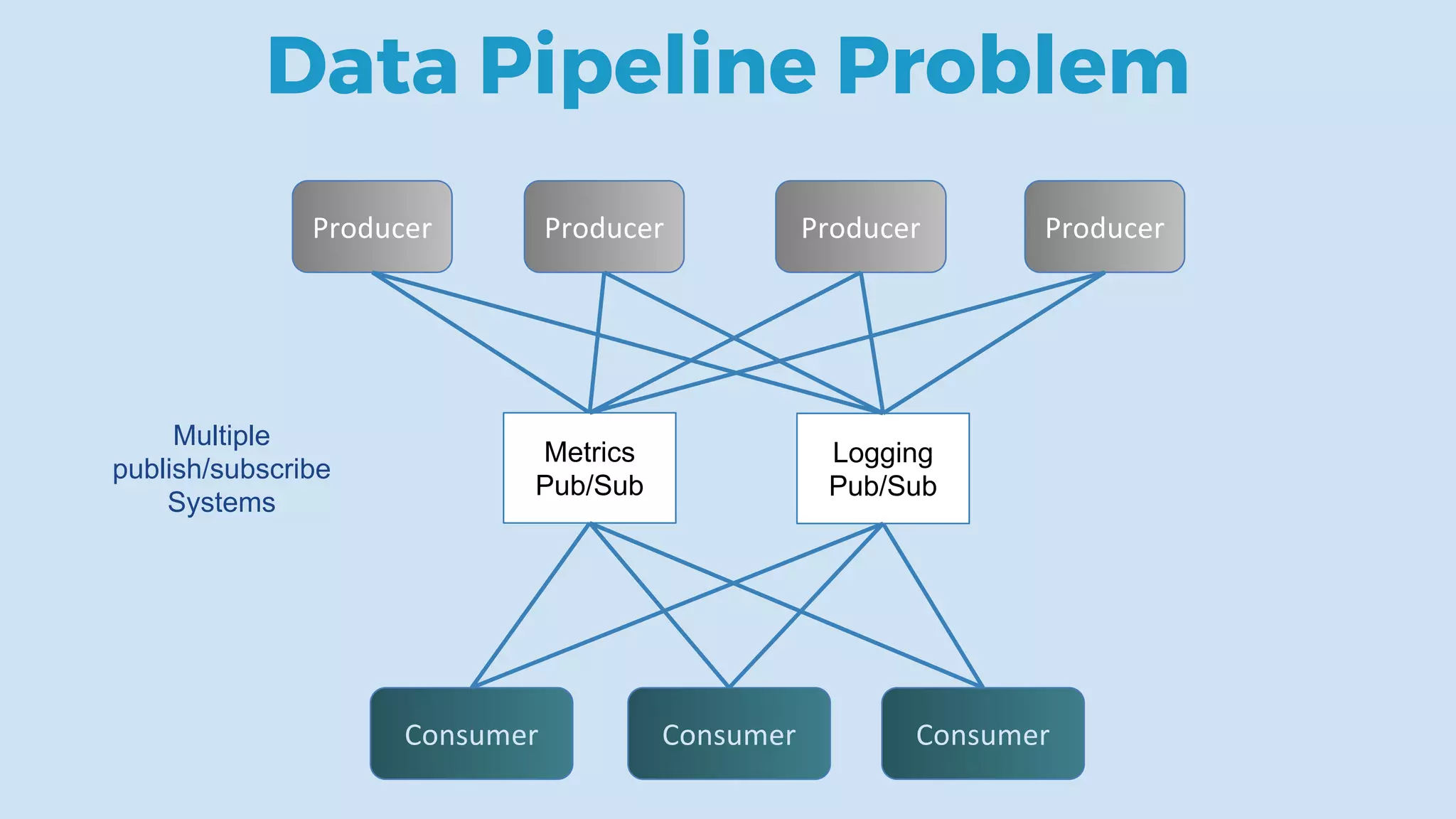
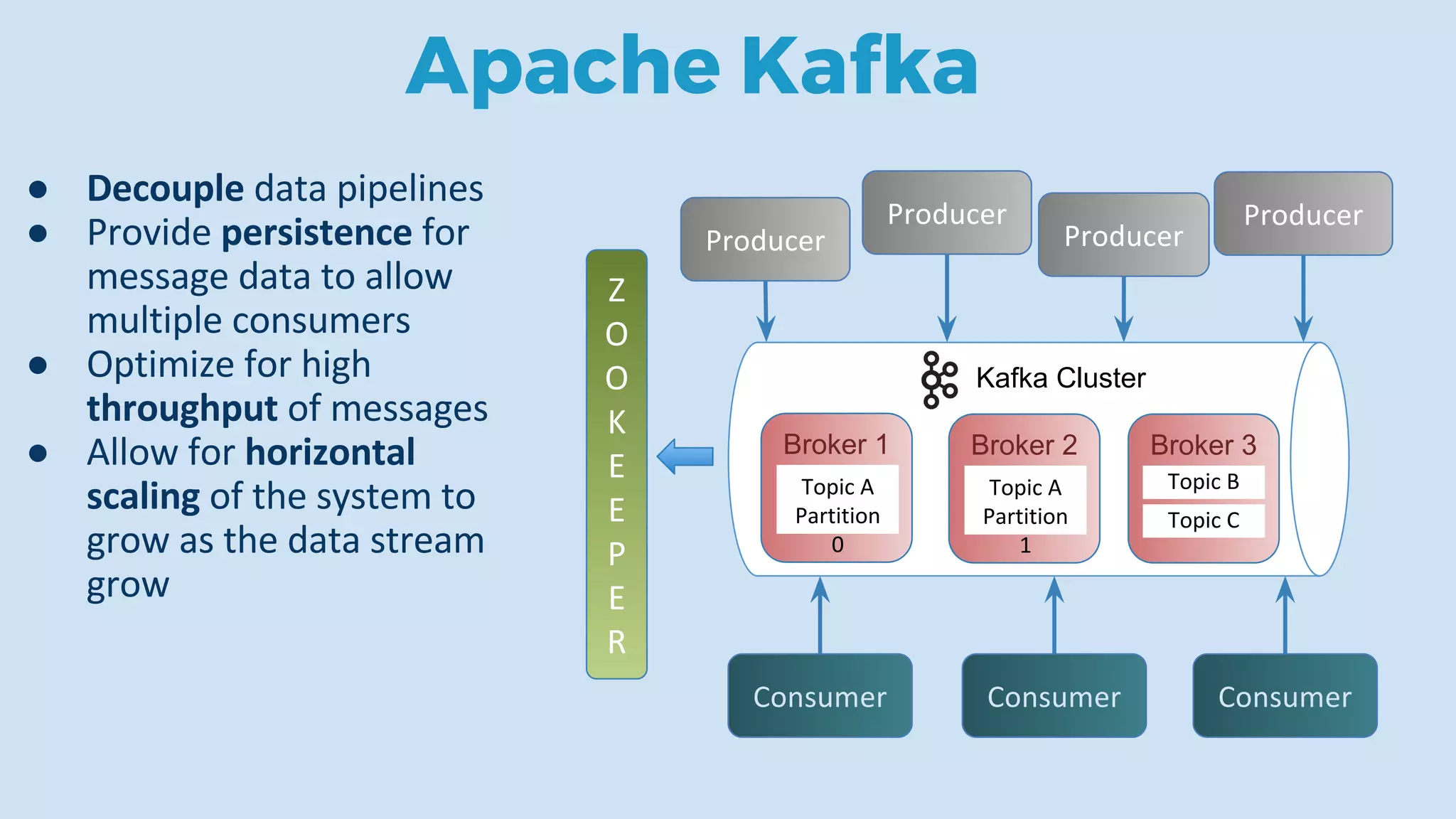
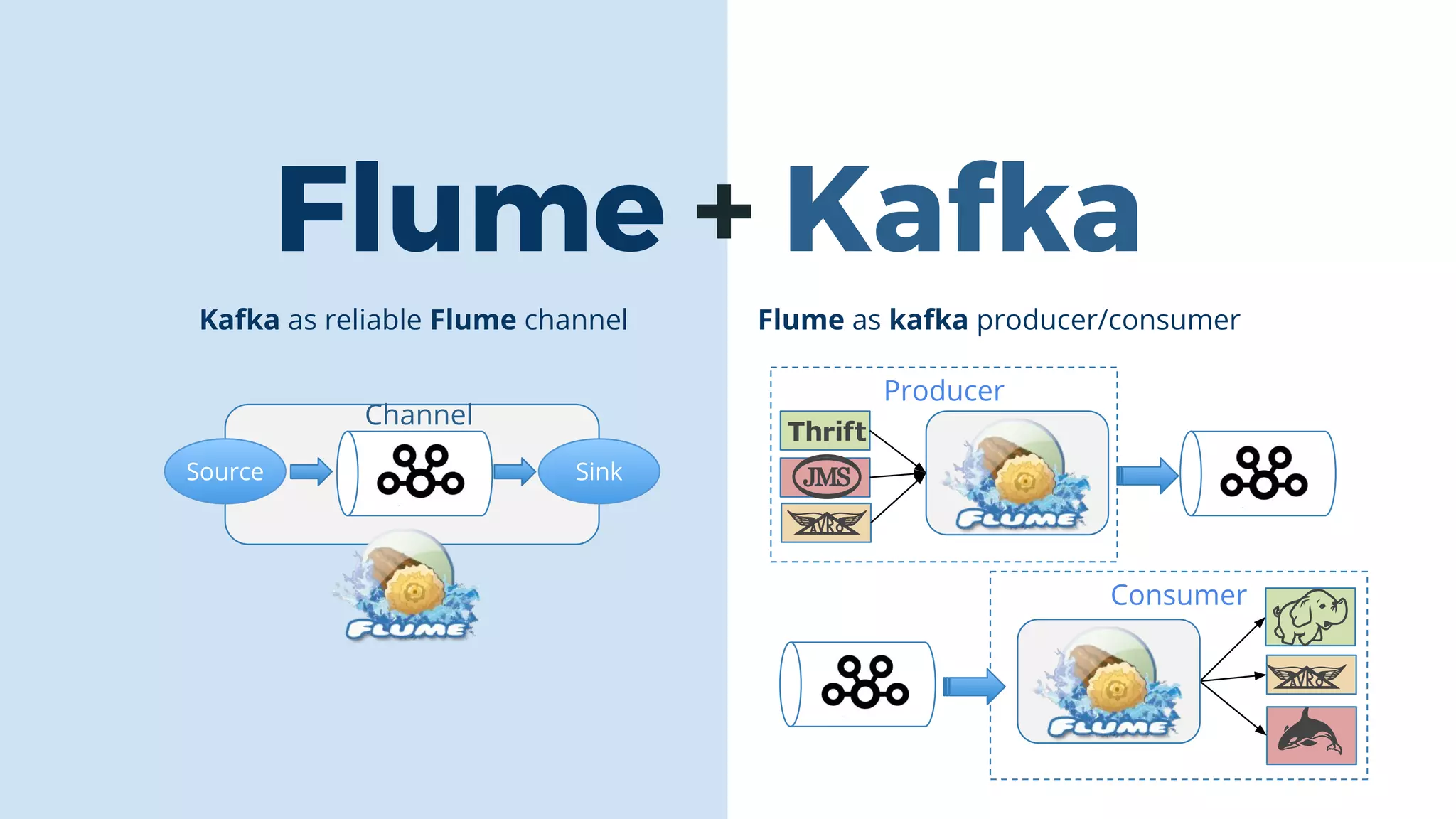
This document discusses data integration and architectures for processing both batch and streaming data. It covers topics like data ingestion using tools like Flume, Sqoop and Kafka to move data into data lakes and warehouses. It also discusses batch processing using MapReduce on Hadoop and stream processing using real-time technologies like Kafka and architectures like lambda and kappa for serving queries on both real-time and batch-processed views of the data.























































































