


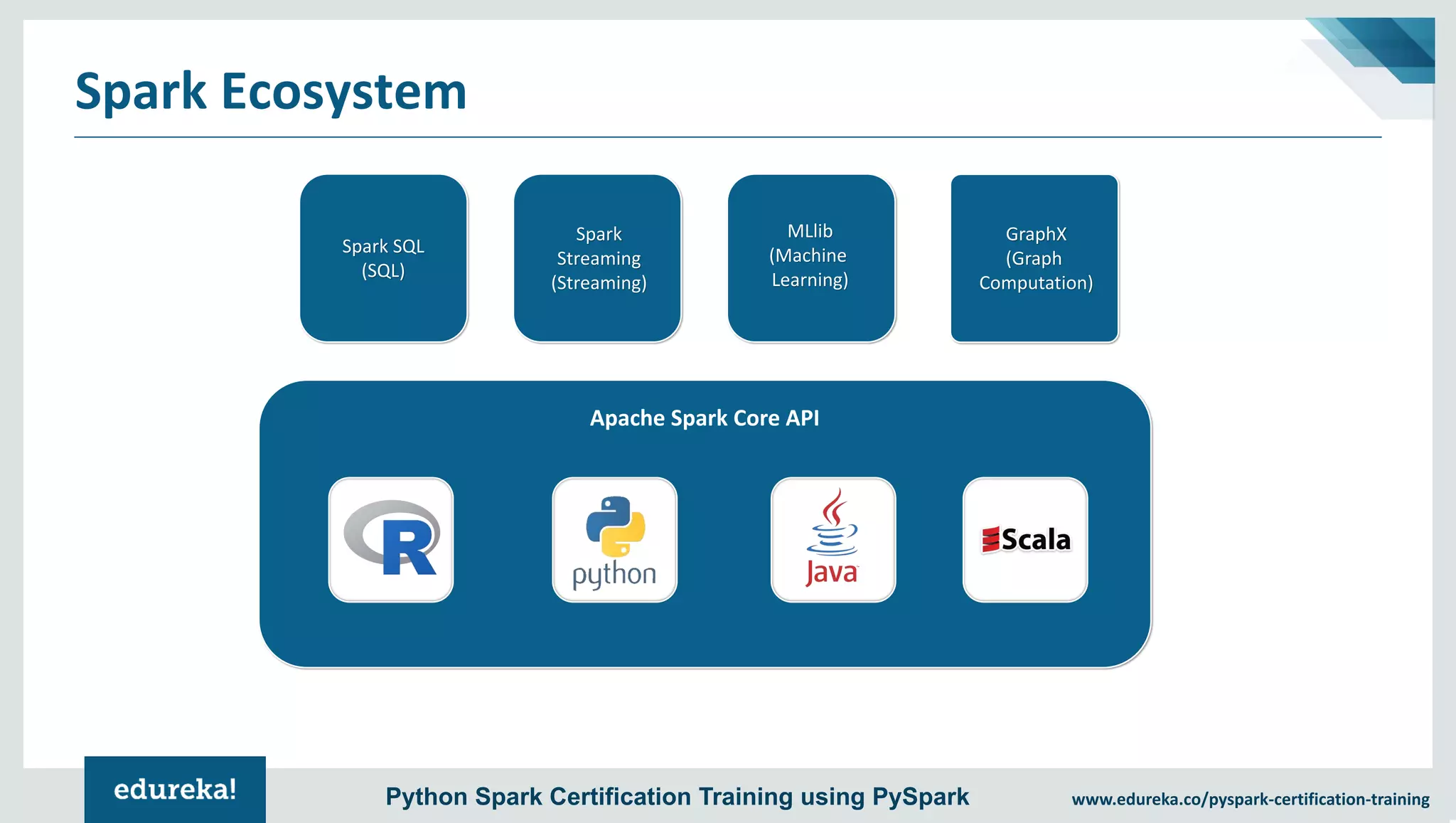
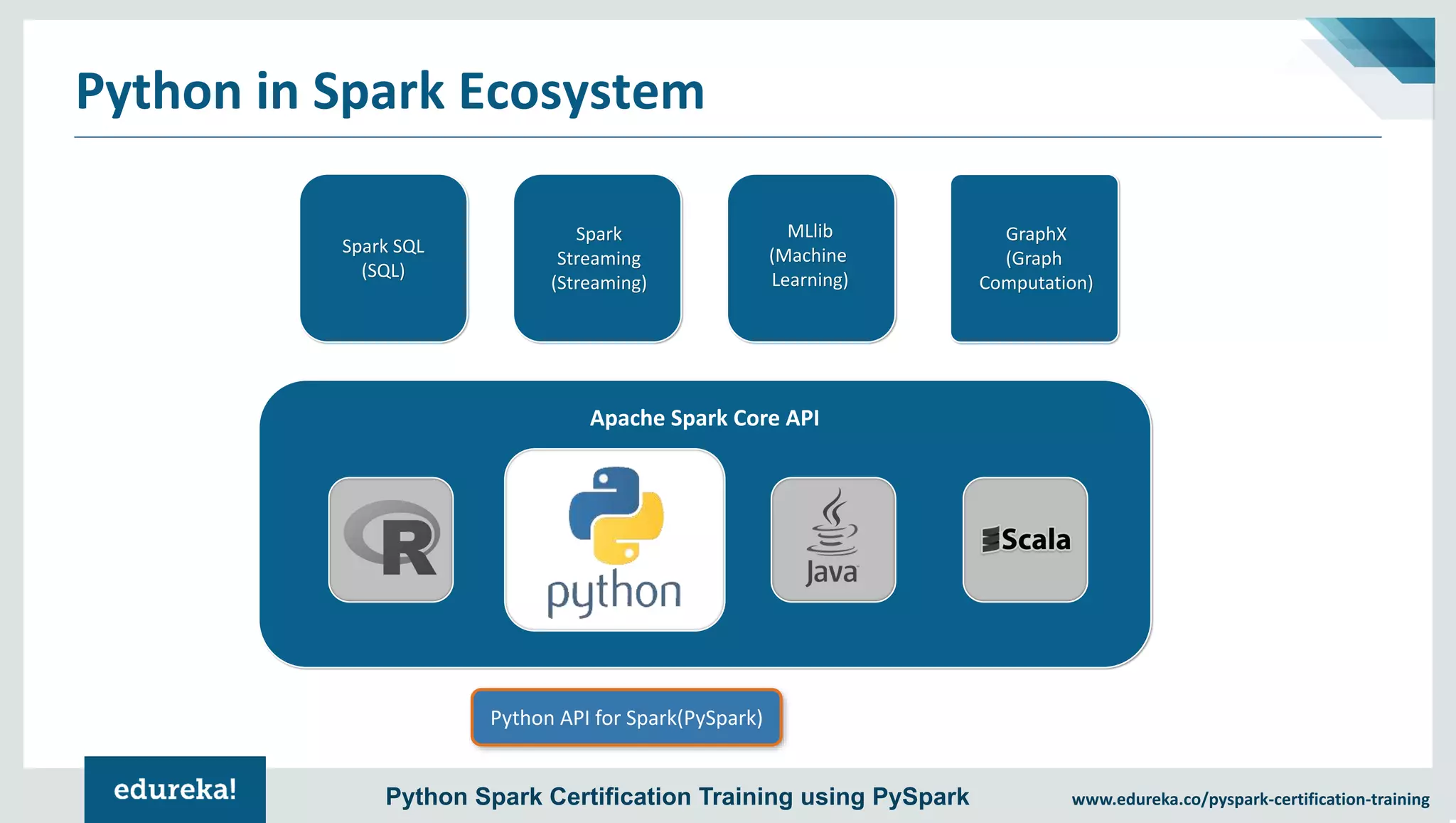




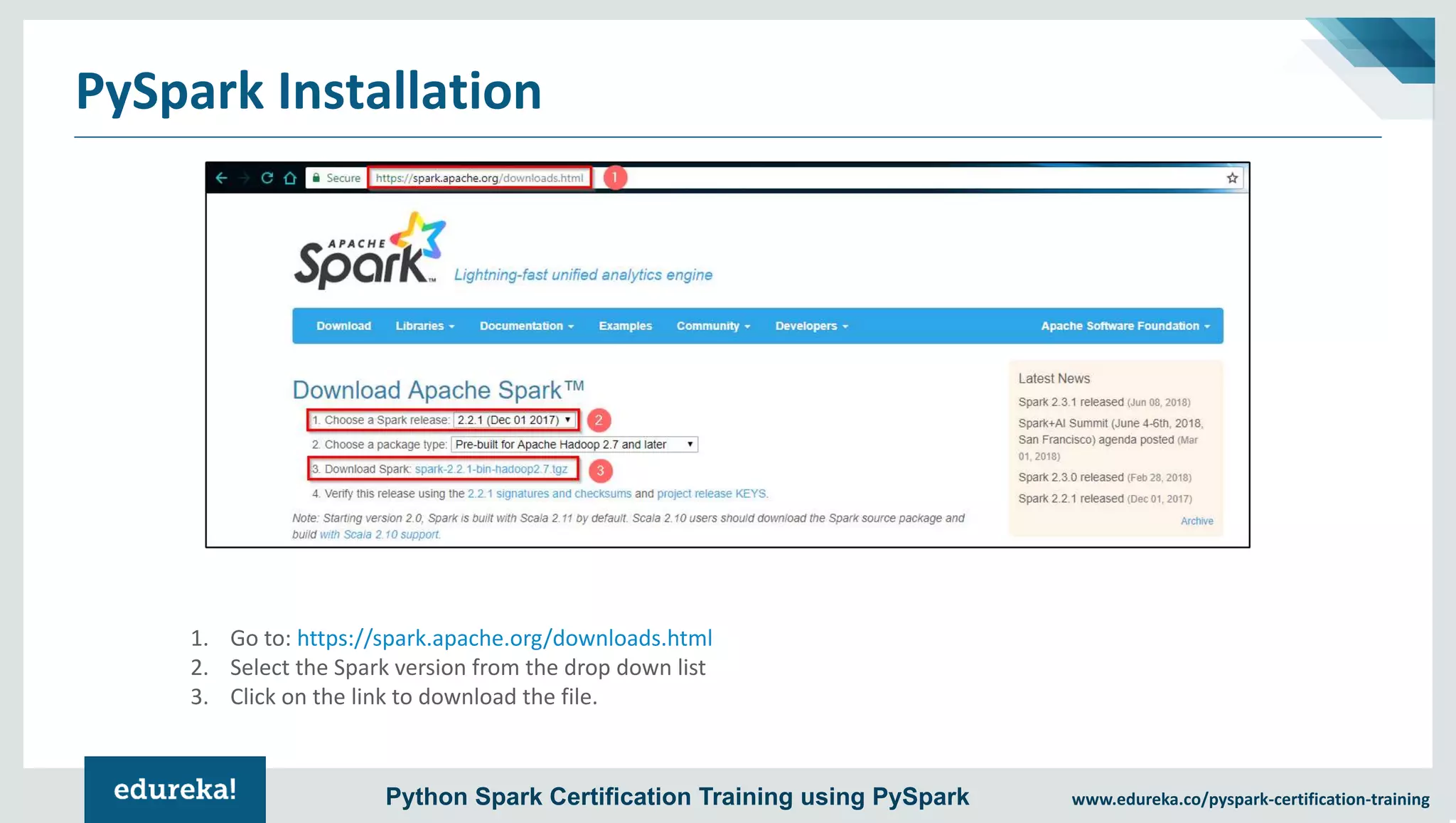

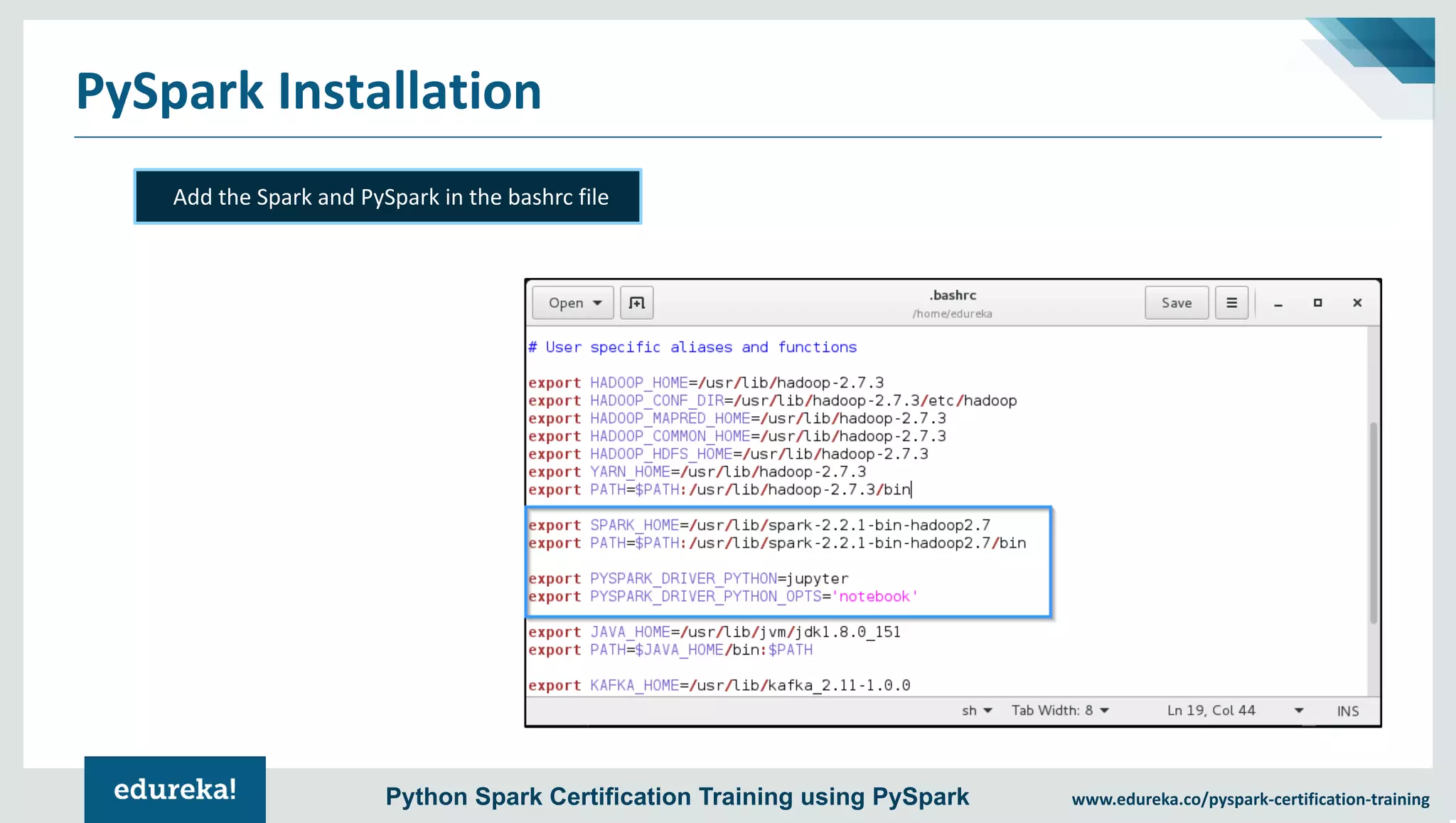
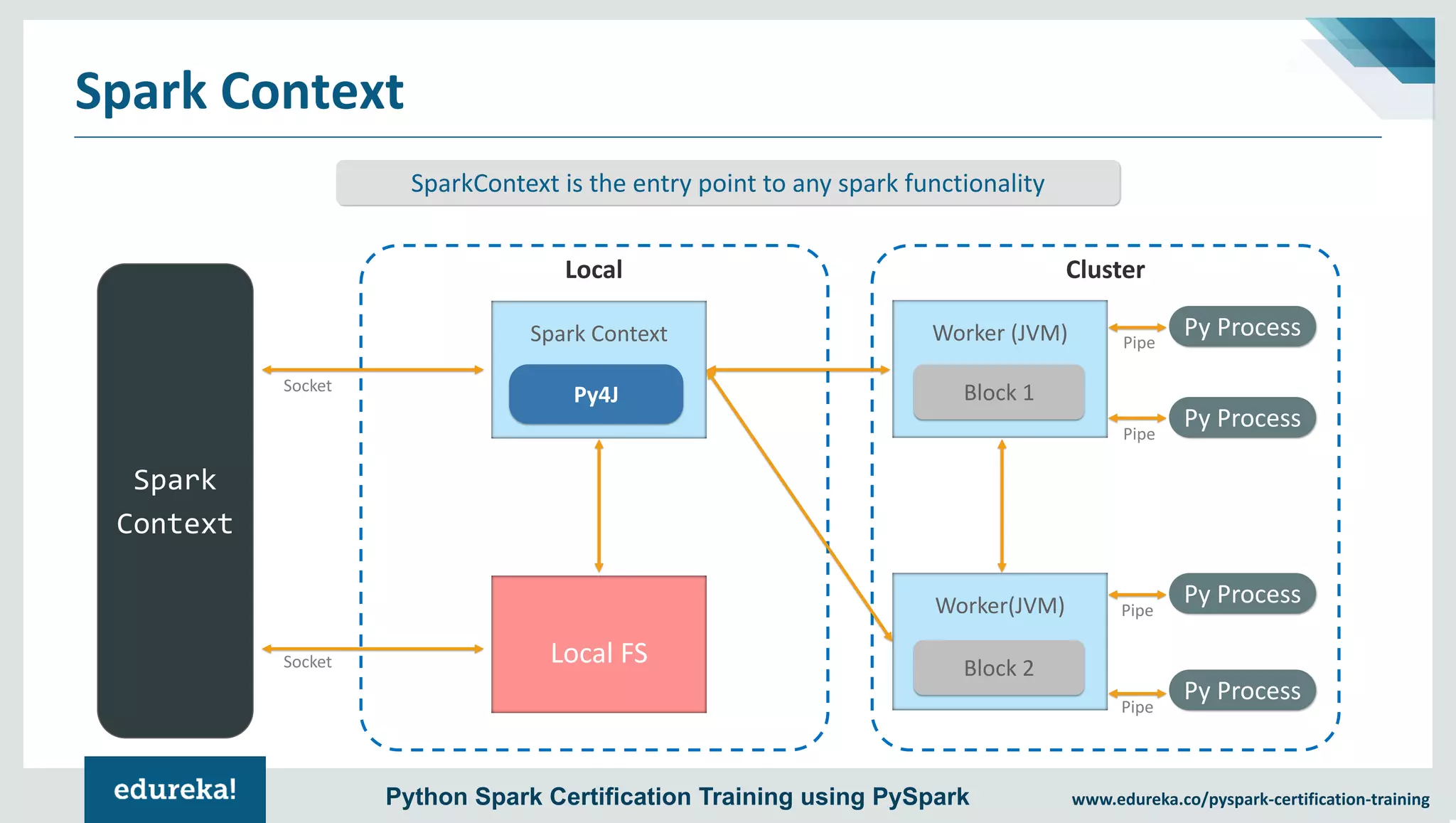
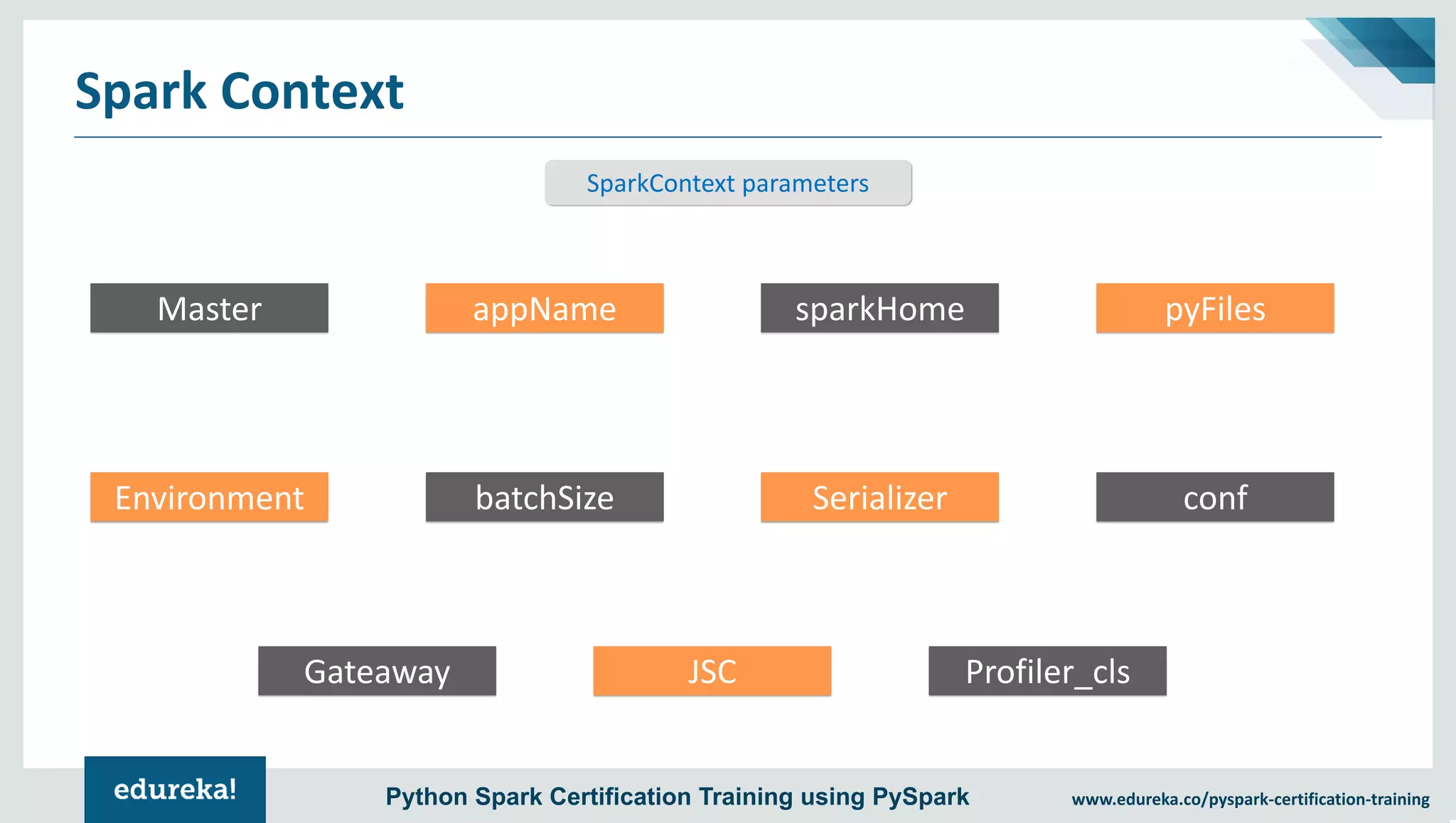
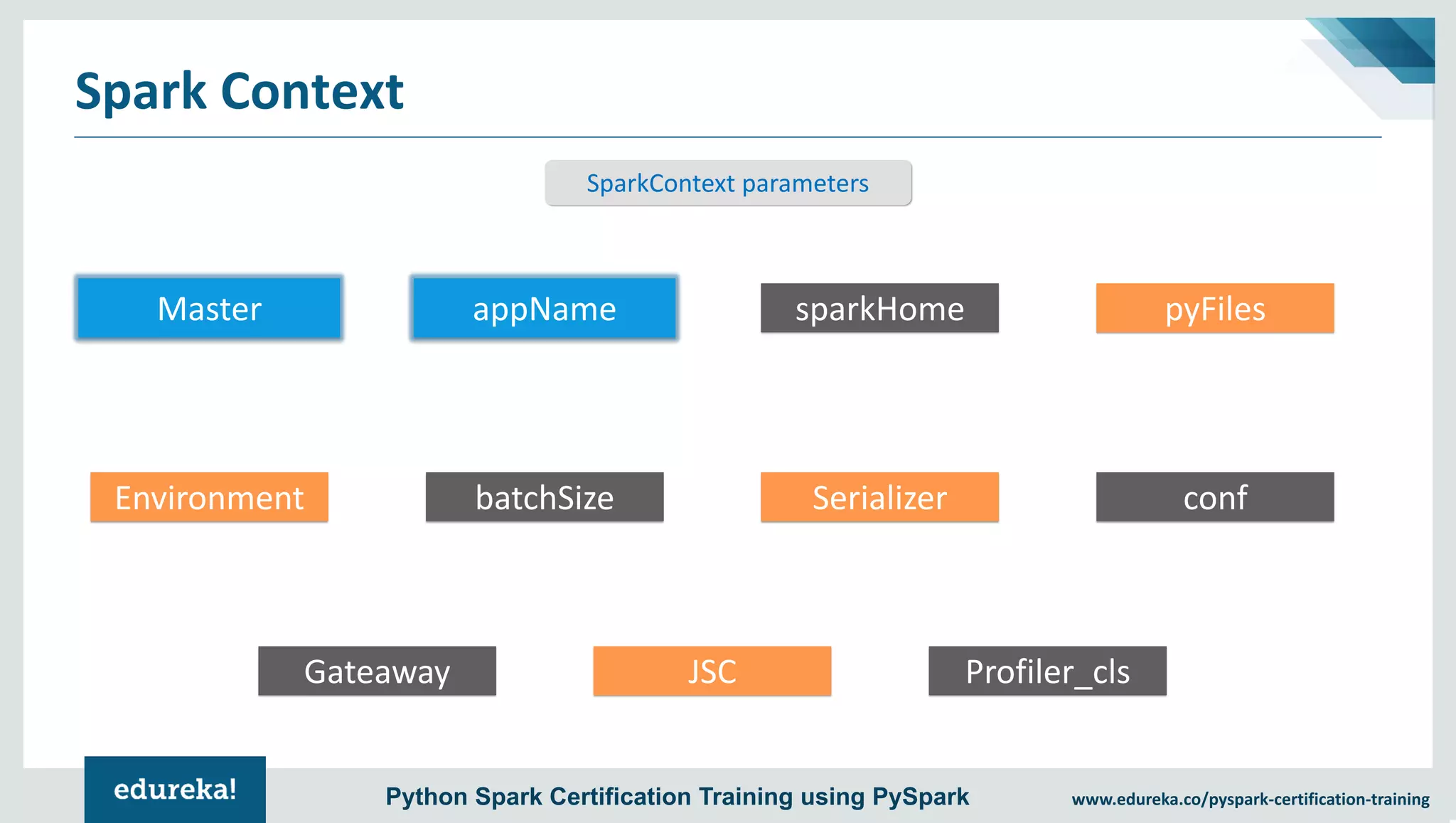
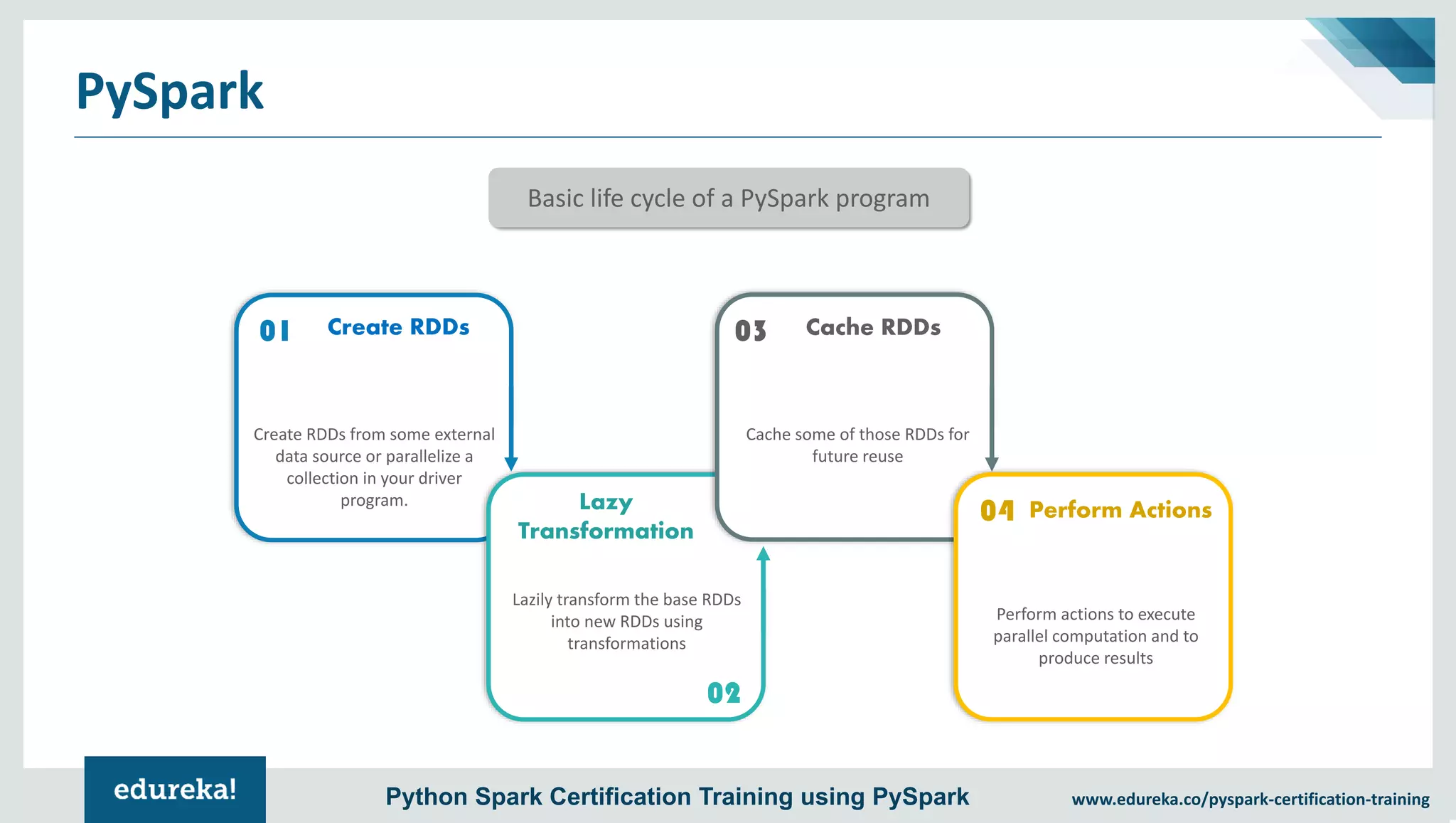



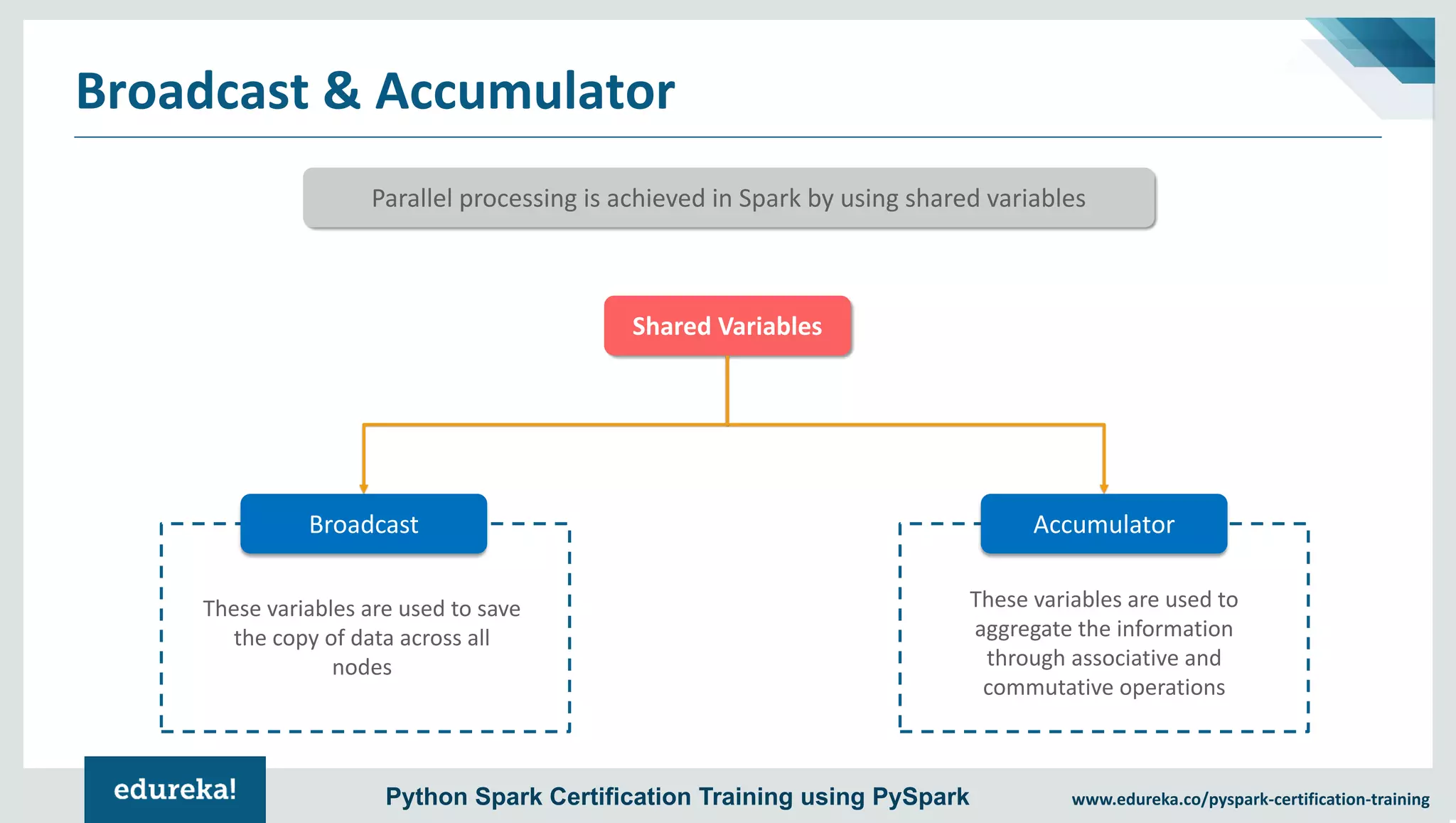
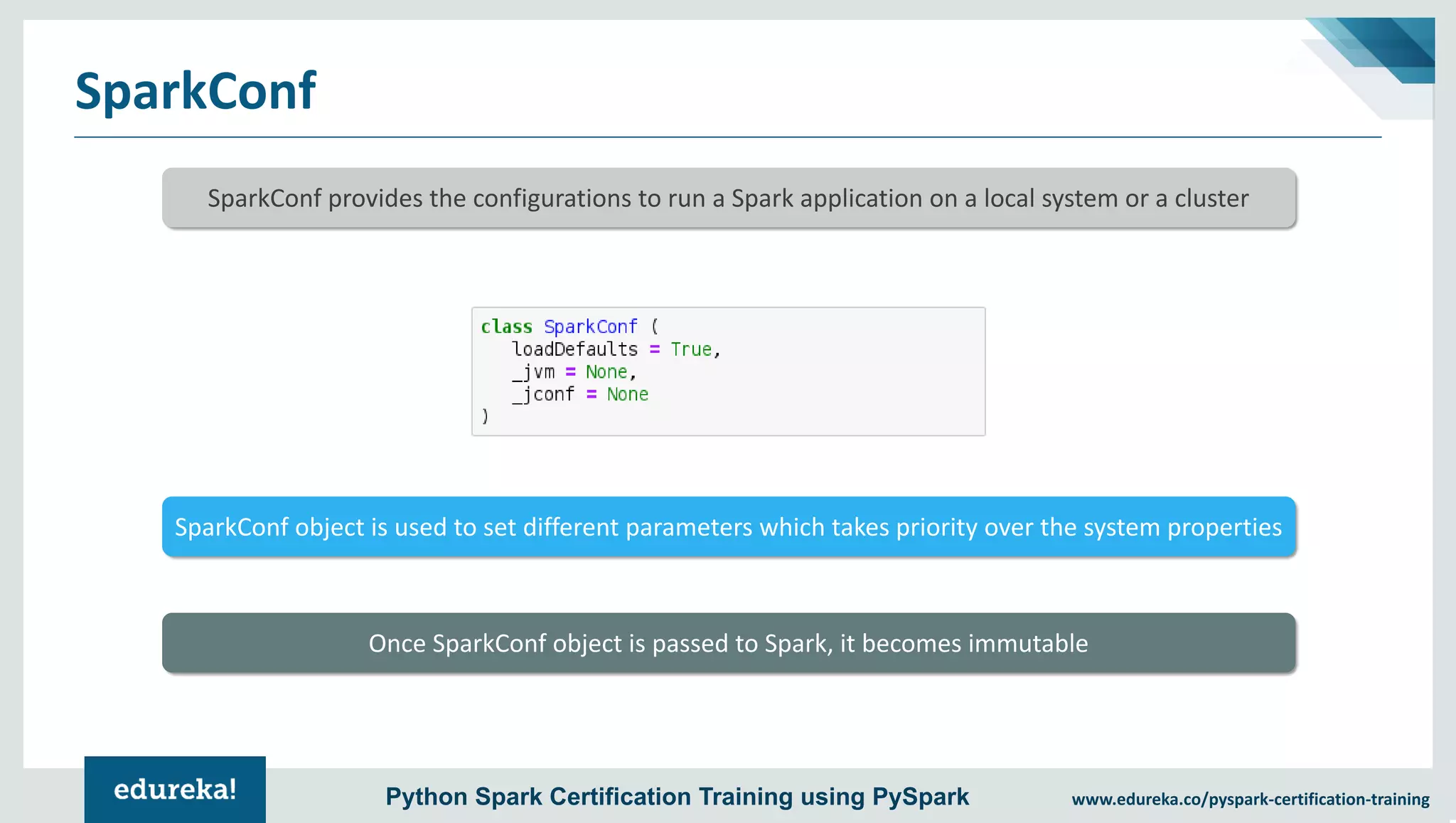


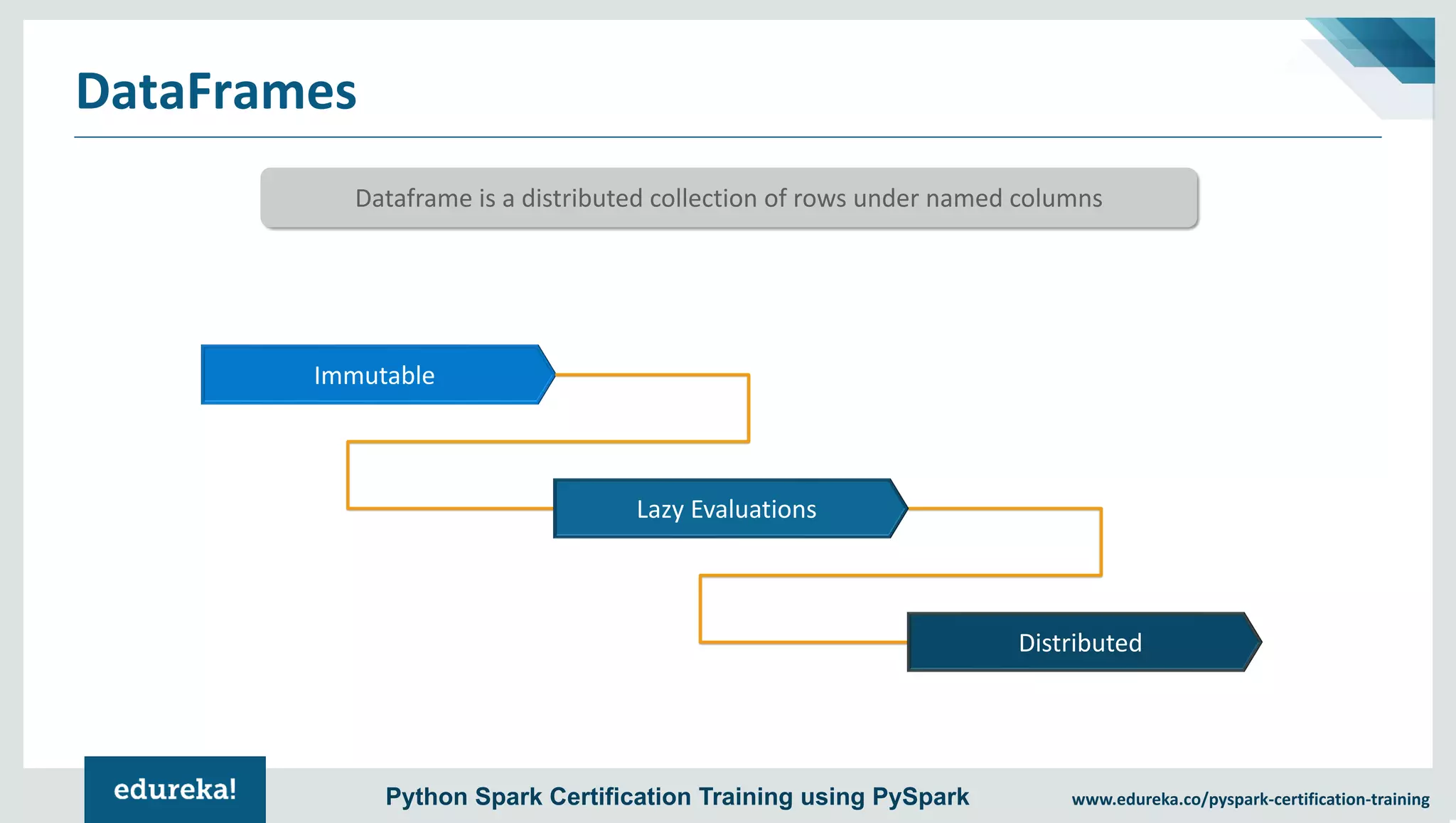
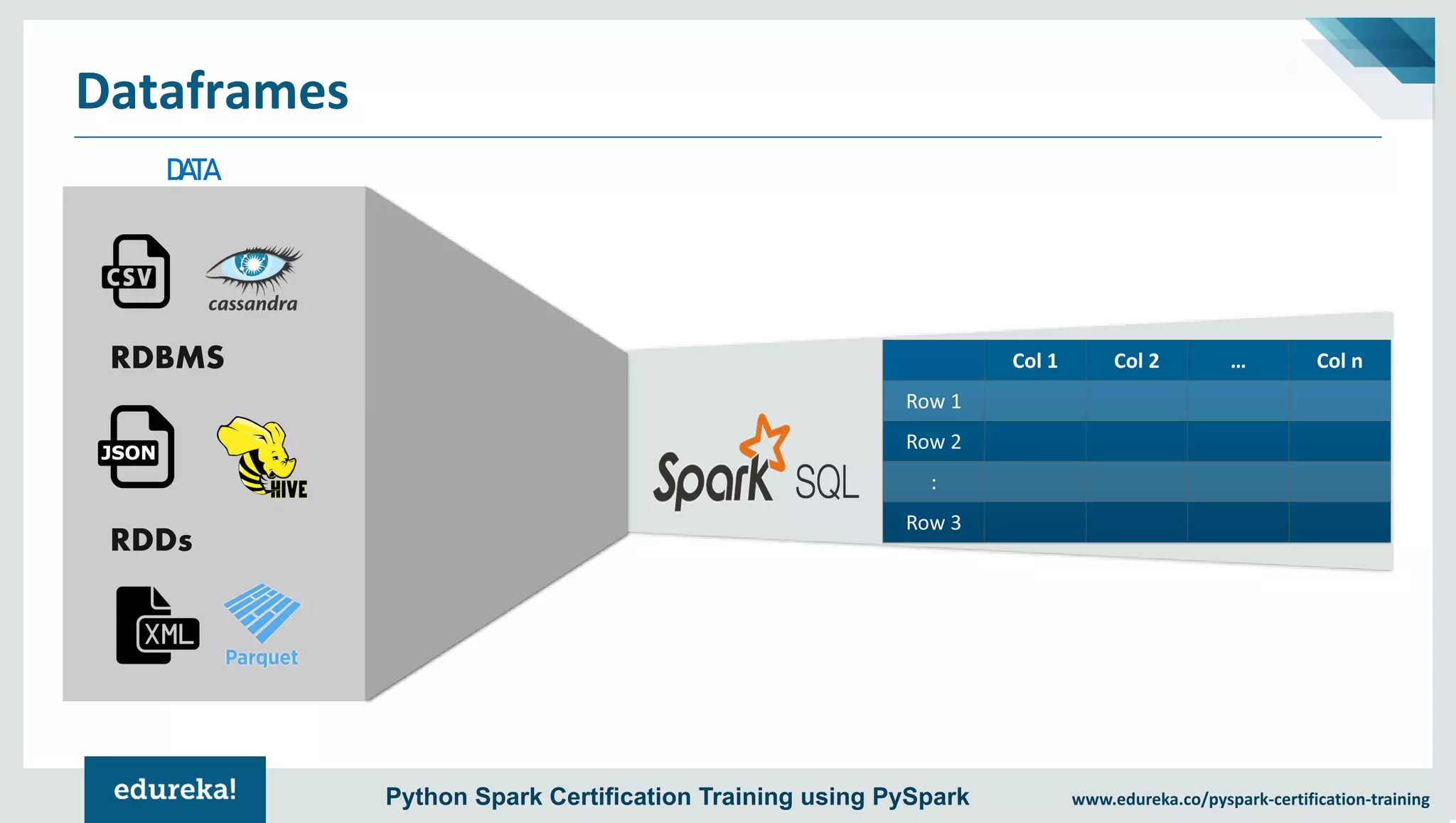
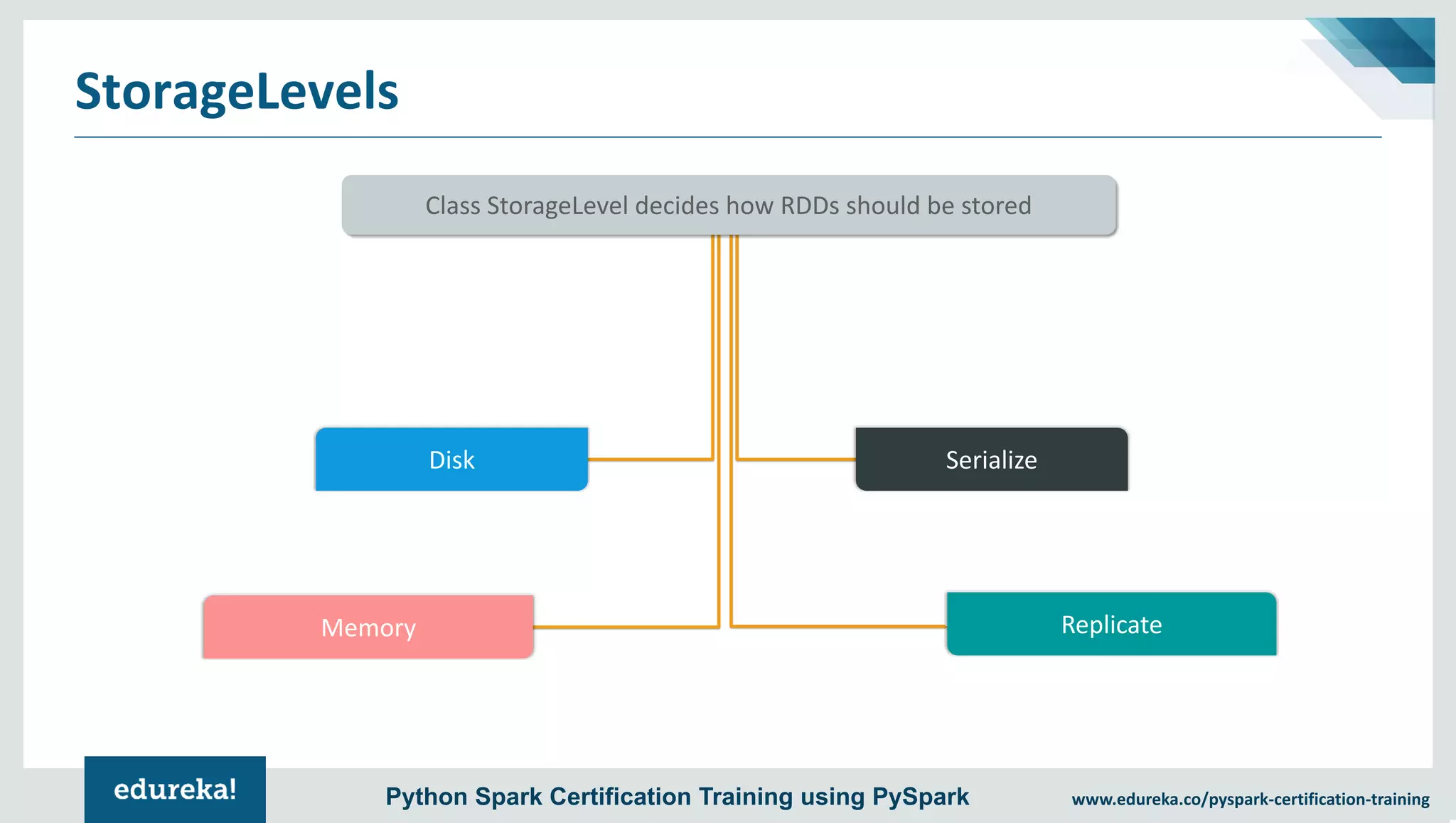
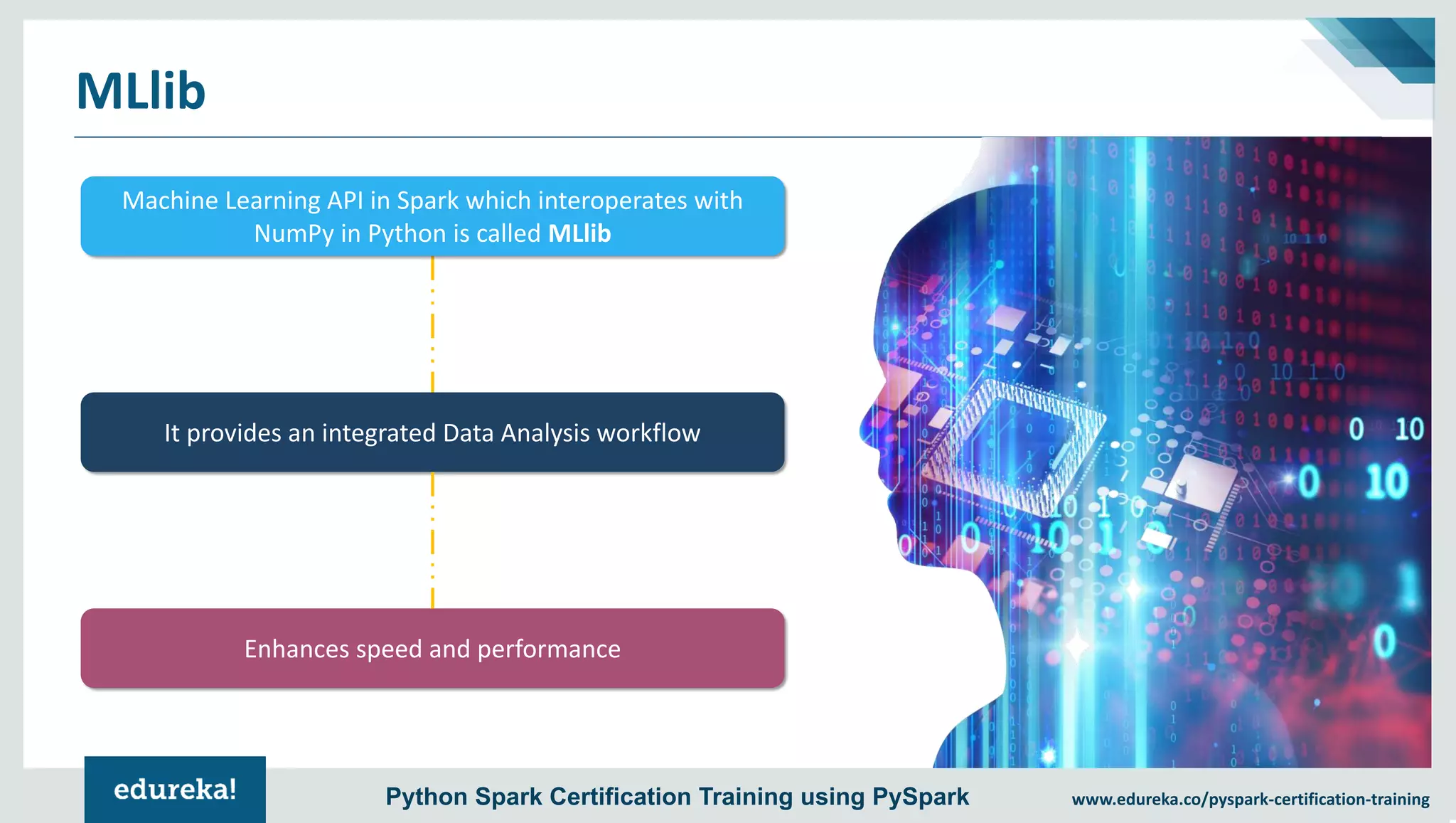
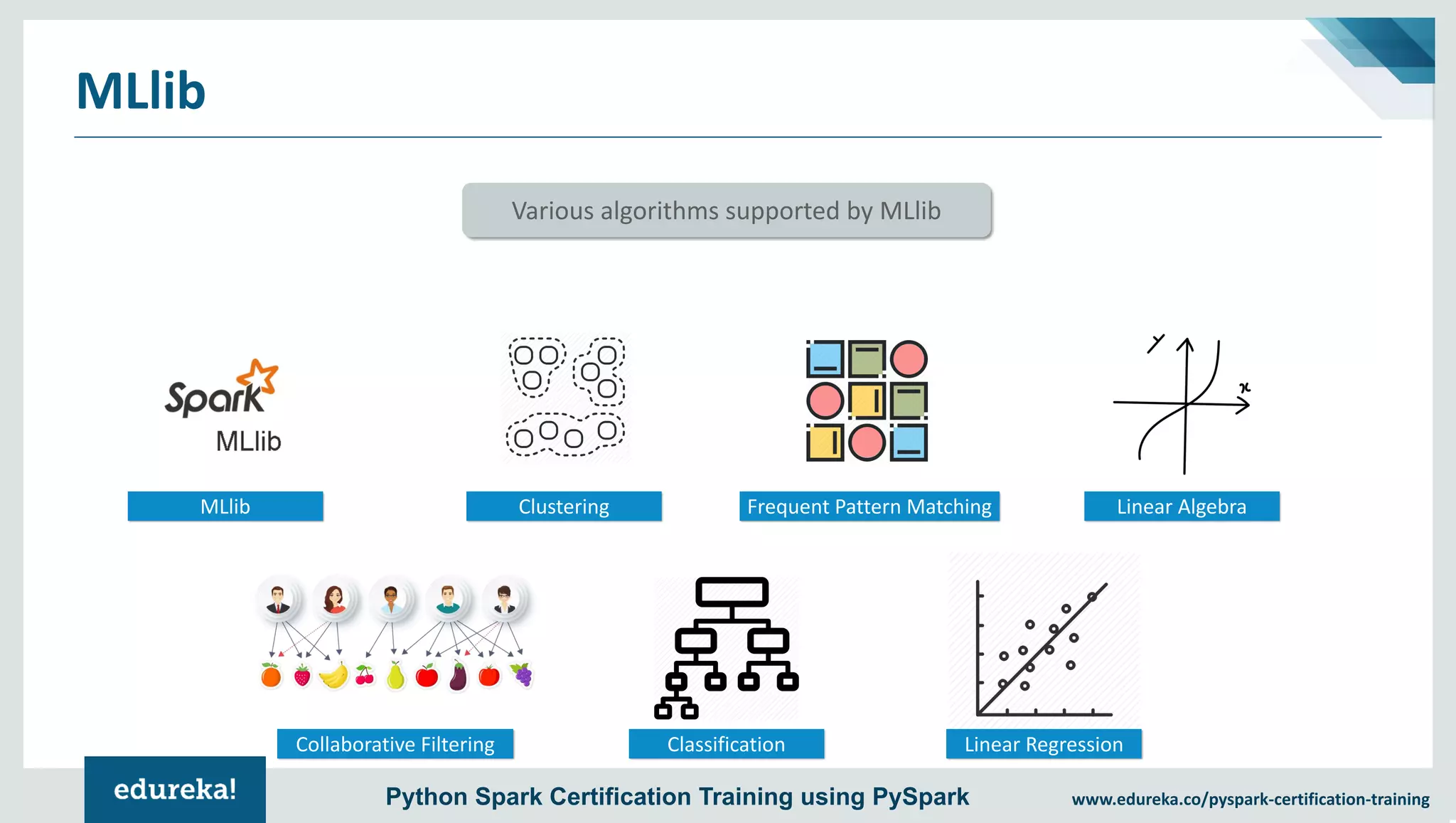
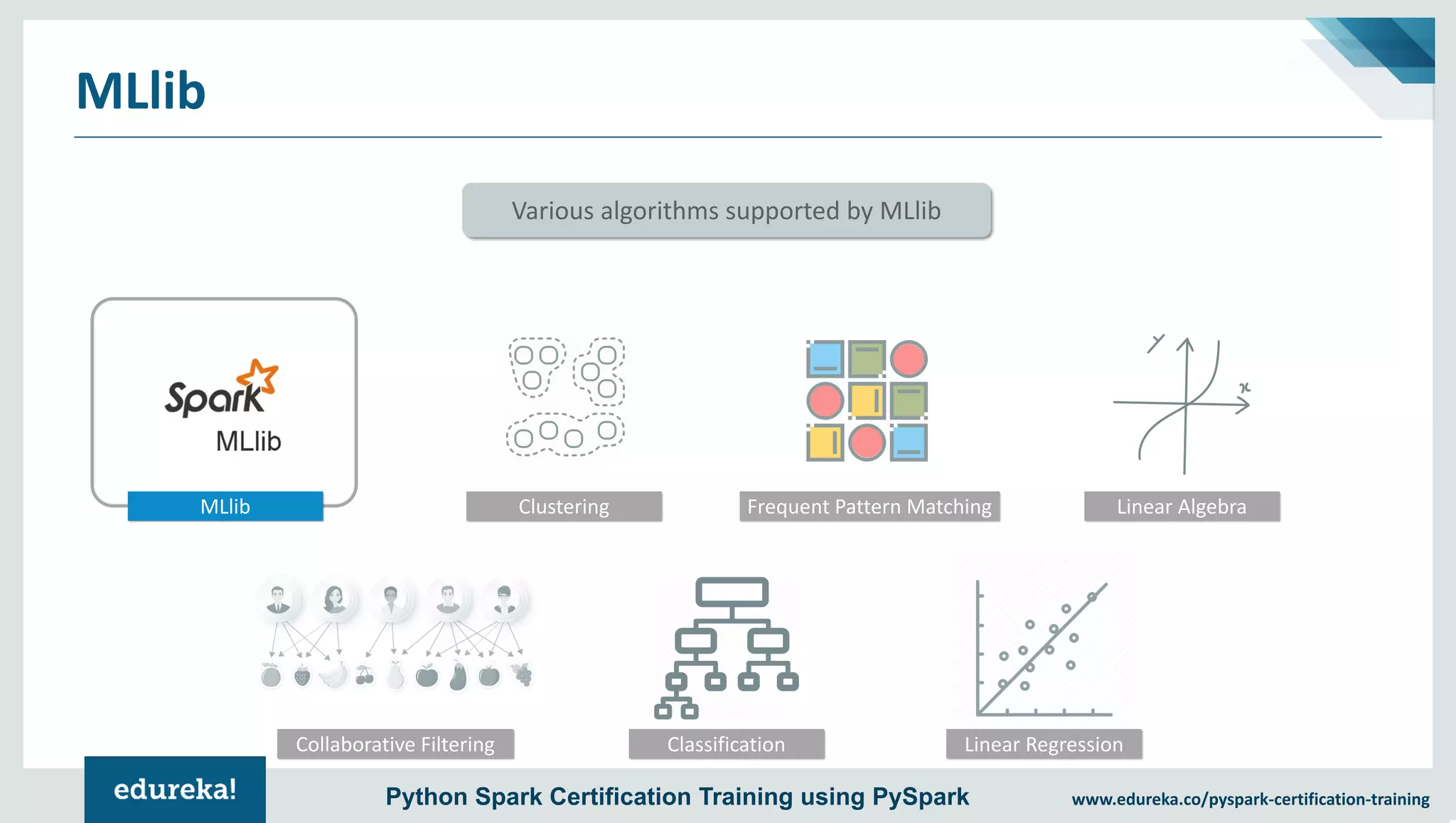

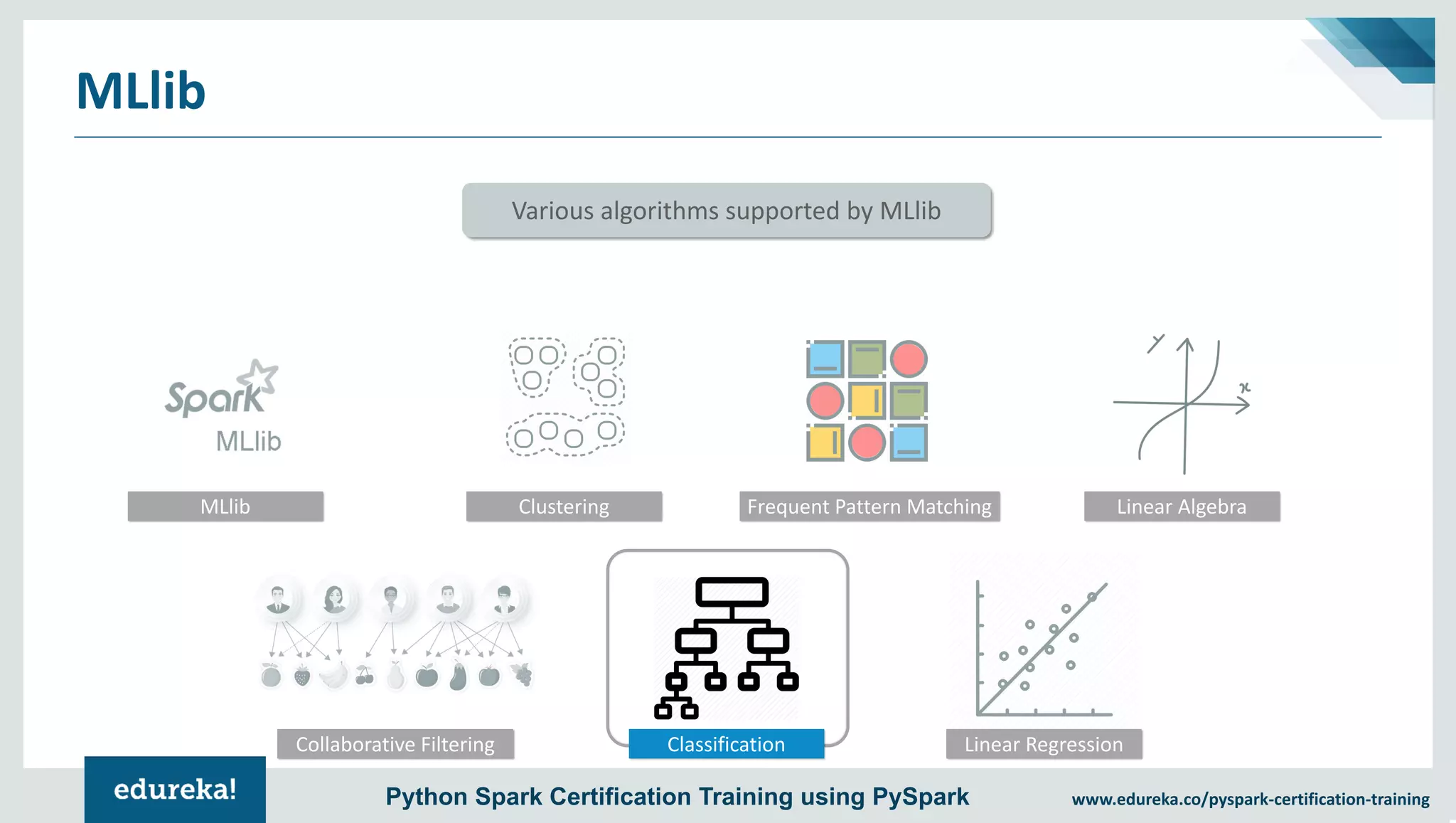
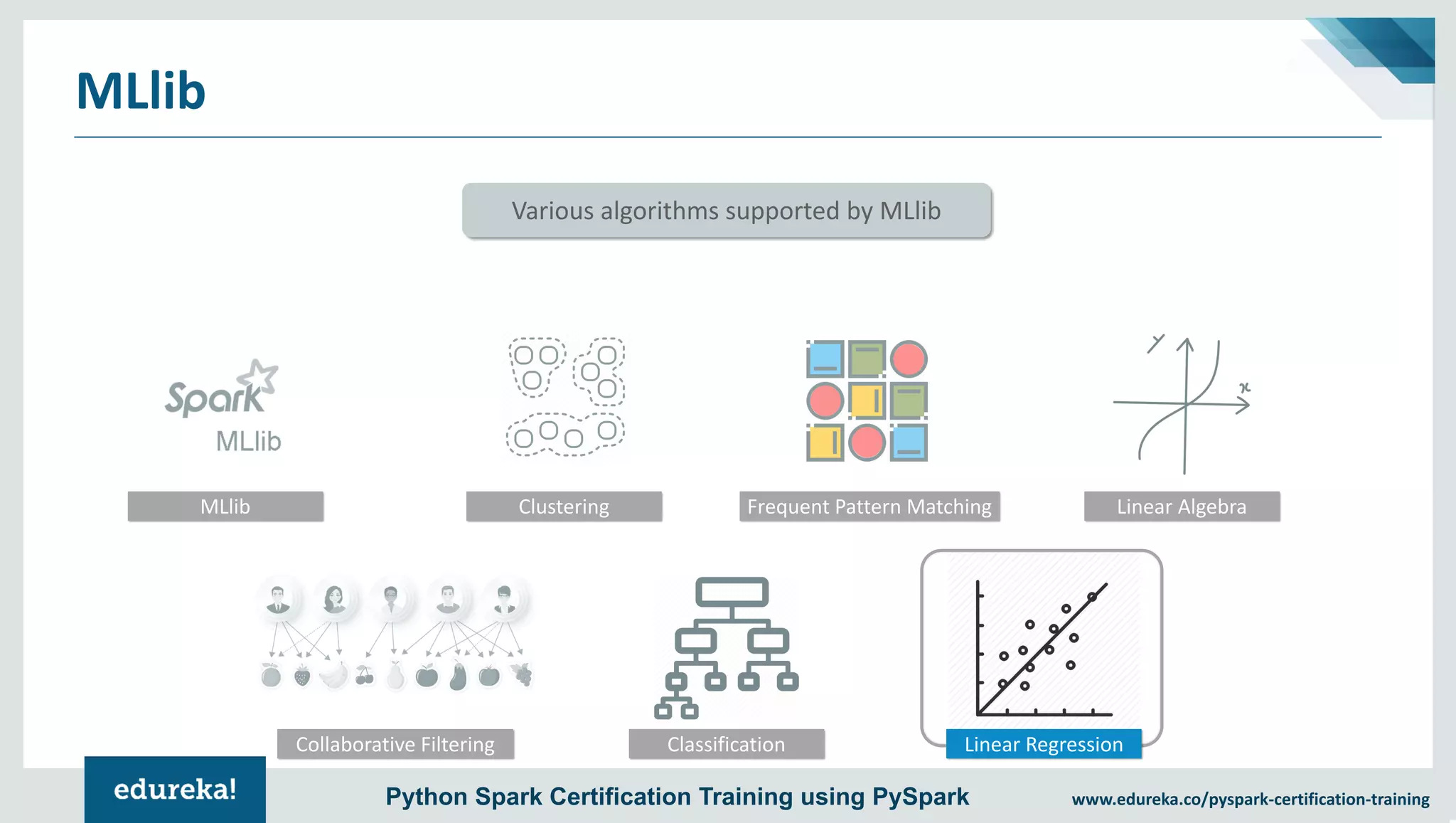


The document provides an overview of PySpark, an open-source cluster-computing framework that integrates with Python for data science and machine learning applications. It covers the advantages of PySpark, installation steps, and fundamental concepts such as RDDs, DataFrames, and the Spark context. Additionally, it outlines functionalities like transformations, actions, and the MLlib machine learning API offered by Spark.























































































