Download as PDF, PPTX













![‹#›© Cloudera, Inc. All rights reserved.
• Write a function for
anything inside an
transformation
• Make it static
• Separate Feature
generation or data
standardization
from your modeling
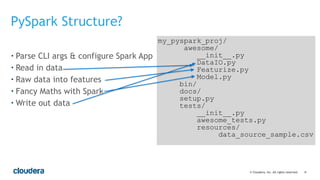
Write Testable Code
Featurize.py
…
!
@static_method
def label(single_record):
…
return label_as_a_double
@static_method
def descriptive_name_of_feature1():
...
return a_double
!
@static_method
def create_labeled_point(data_usage_rdd, sms_usage_rdd):
...
return LabeledPoint(label, [feature1])](https://image.slidesharecdn.com/pysparkbestpractices-151005164023-lva1-app6892/85/PySpark-Best-Practices-24-320.jpg)








![‹#›© Cloudera, Inc. All rights reserved.
Many Python Environments Path to Python binary to use
on the cluster can be set with
PYSPARK_PYTHON
!
Can be set it in spark-env.sh
if [ -n “${PYSPARK_PYTHON}" ]; then
export PYSPARK_PYTHON=<path>
fi](https://image.slidesharecdn.com/pysparkbestpractices-151005164023-lva1-app6892/85/PySpark-Best-Practices-33-320.jpg)


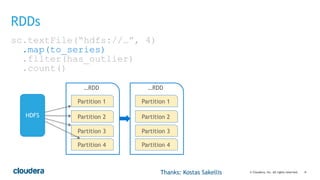
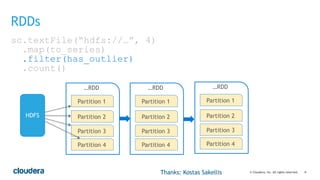
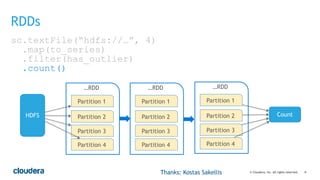
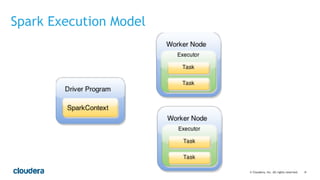
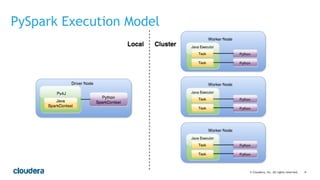
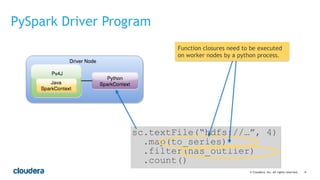
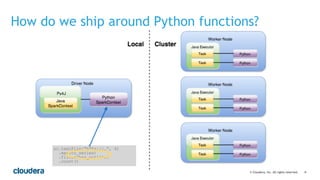
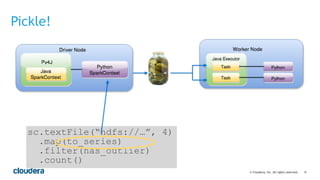
This document discusses best practices for using PySpark. It covers: - Core concepts of PySpark including RDDs and the execution model. Functions are serialized and sent to worker nodes using pickle. - Recommended project structure with modules for data I/O, feature engineering, and modeling. - Writing testable, serializable code with static methods and avoiding non-serializable objects like database connections. - Tips for testing like unit testing functions and integration testing the full workflow. - Best practices for running jobs like configuring the Python environment, managing dependencies, and logging to debug issues.





























































































