
















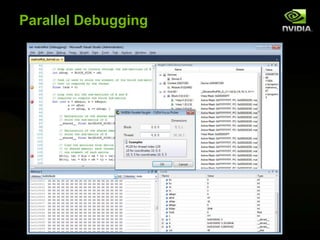









![Simple Matrix Multiplication (CPU)void MatrixMulOnHost(float* M, float* N, float* P, int Width){ for (int i = 0; i < Width; ++i) { for (int j = 0; j < Width; ++j) { float sum = 0;for (int k = 0; k < Width; ++k) {float a = M[i * width + k];float b = N[k * width + j];sum += a * b;}P[i * Width + j] = sum; } }}NkjWIDTHMPiWIDTHk29WIDTHWIDTH](https://image.slidesharecdn.com/codestockintrotogpgpuwithcuda-110605194751-phpapp02/85/Intro-to-GPGPU-Programming-with-Cuda-29-320.jpg)



![Kernel Function (contd.)for (int k = 0; k < Width; ++k) {float Melement = Md[threadIdx.y*Width+k];float Nelement = Nd[k*Width+threadIdx.x];Pvalue+= Melement * Nelement; }Pd[threadIdx.y*Width+threadIdx.x] = Pvalue;}NdkWIDTHtxMdPdtytyWIDTHtxk33WIDTHWIDTH](https://image.slidesharecdn.com/codestockintrotogpgpuwithcuda-110605194751-phpapp02/85/Intro-to-GPGPU-Programming-with-Cuda-33-320.jpg)
![Kernel Function (full)// Matrix multiplication kernel – per thread code__global__ void MatrixMulKernel(float* Md, float* Nd, float* Pd, int Width){ // Pvalue is used to store the element of the matrix// that is computed by the threadfloat Pvalue = 0; for (int k = 0; k < Width; ++k) { float Melement = Md[threadIdx.y*Width+k]; float Nelement = Nd[k*Width+threadIdx.x];Pvalue += Melement * Nelement; }Pd[threadIdx.y*Width+threadIdx.x] = Pvalue;}](https://image.slidesharecdn.com/codestockintrotogpgpuwithcuda-110605194751-phpapp02/85/Intro-to-GPGPU-Programming-with-Cuda-34-320.jpg)



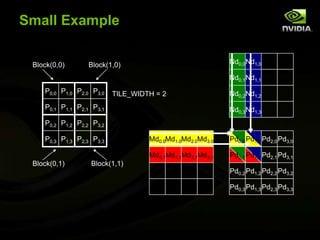



1) The document provides an introduction to GPGPU programming with CUDA, outlining goals of providing an overview and vision for using GPUs to improve applications. 2) Key aspects of GPU programming are discussed, including the large number of cores devoted to data processing, example applications that are well-suited to parallelization, and the CUDA tooling in Visual Studio. 3) A hands-on example of matrix multiplication is presented to demonstrate basic CUDA programming concepts like memory management between host and device, kernel invocation across a grid of blocks, and using thread IDs to parallelize work.





















































































