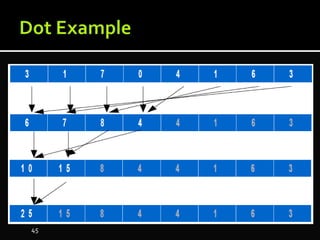
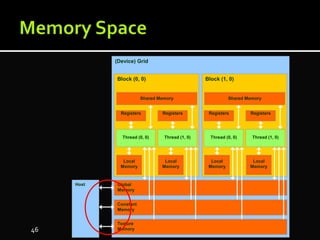
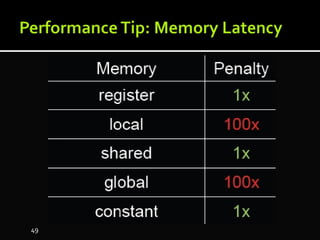
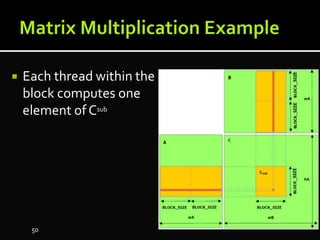
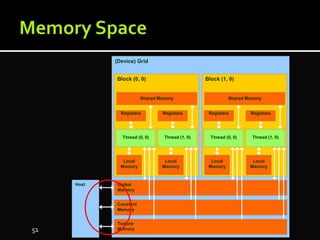
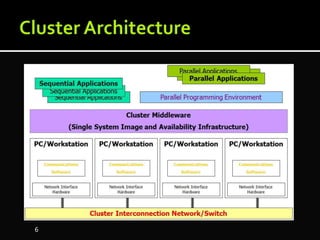
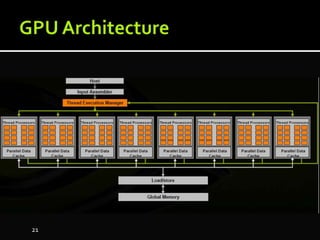
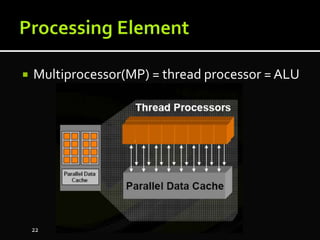
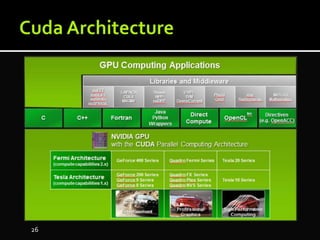
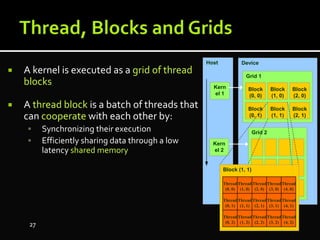
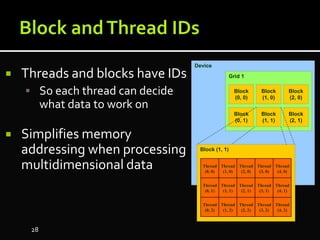
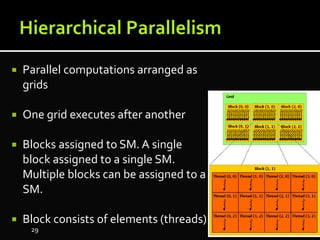
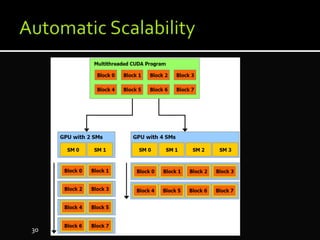
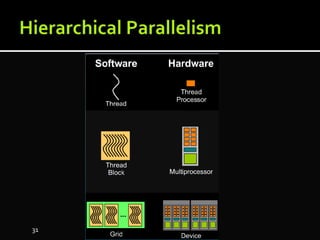
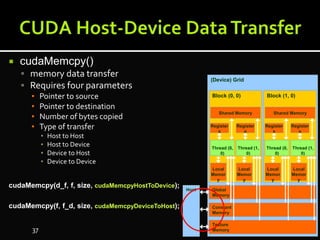
The document discusses the implementation of cloud computing and its applications across various technical domains such as computational fluid dynamics, computational biology, and financial analytics. It emphasizes the infrastructure challenges, cost considerations, and the utility of cloud computing as a flexible and scalable resource. Additionally, it details the capabilities of GPUs for parallel processing and memory management in high-performance computing environments, including discussions on CUDA programming for GPU execution.



























![ Step 1: Allocate the memory on the GPU
int a[N], b[N], c[N];
int *d_a, *d_b, *d_c;
cudaMalloc( (void**)&dev_a, N * sizeof(int) ) ;
cudaMalloc( (void**)&dev_b, N * sizeof(int) ) ;
cudaMalloc( (void**)&dev_c, N * sizeof(int) ) ;
40](https://image.slidesharecdn.com/gpucomputinworkshop23-7-91-vahidamiry-170802132652/85/Gpu-computing-workshop-40-320.jpg)


![ kernel function
__global__ void add( int *a, int *b, int *c ) {
int tid = blockIdx.x;
if (tid < N)
c[tid] = a[tid] + b[tid];
}
43](https://image.slidesharecdn.com/gpucomputinworkshop23-7-91-vahidamiry-170802132652/85/Gpu-computing-workshop-43-320.jpg)