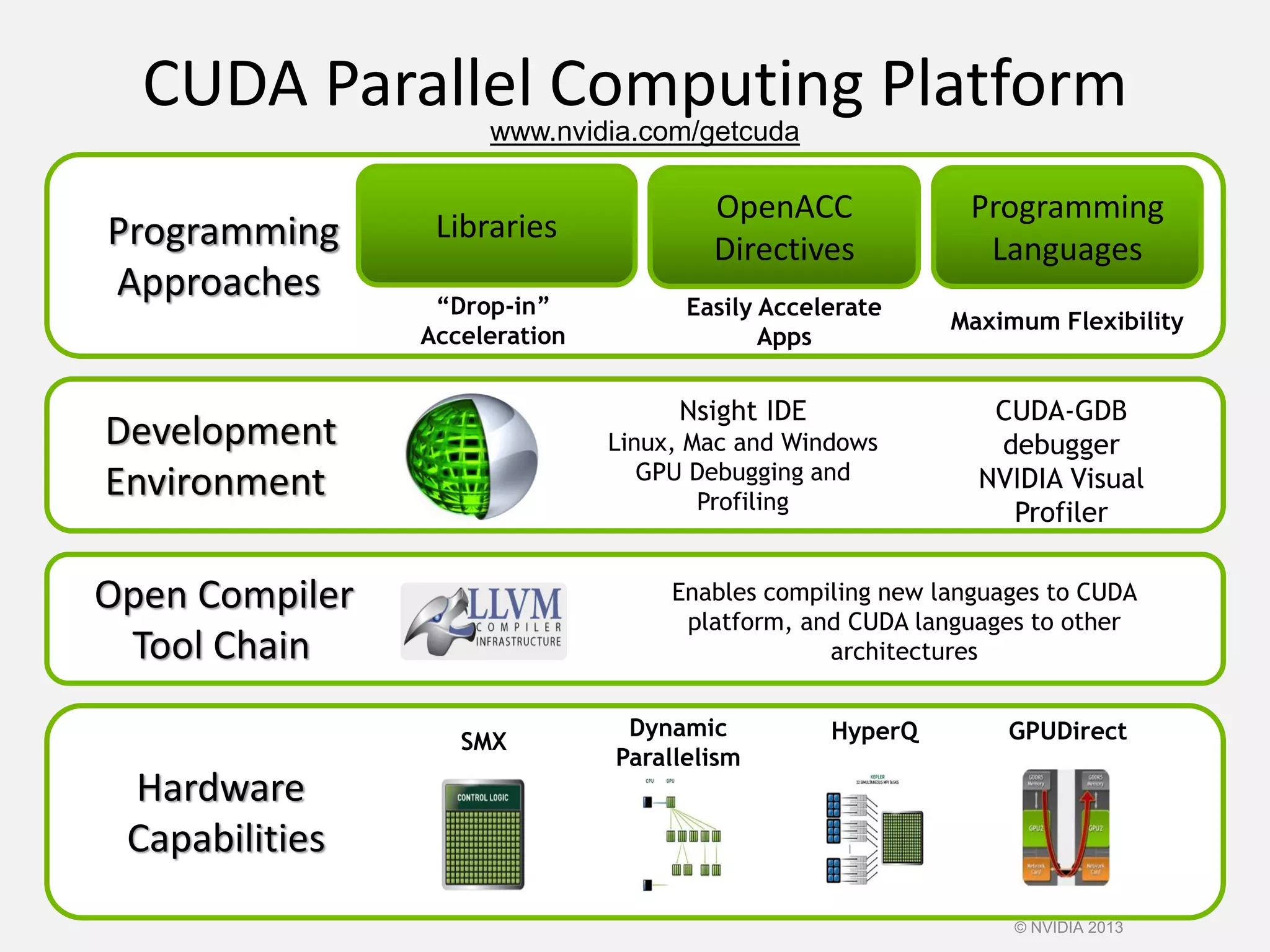
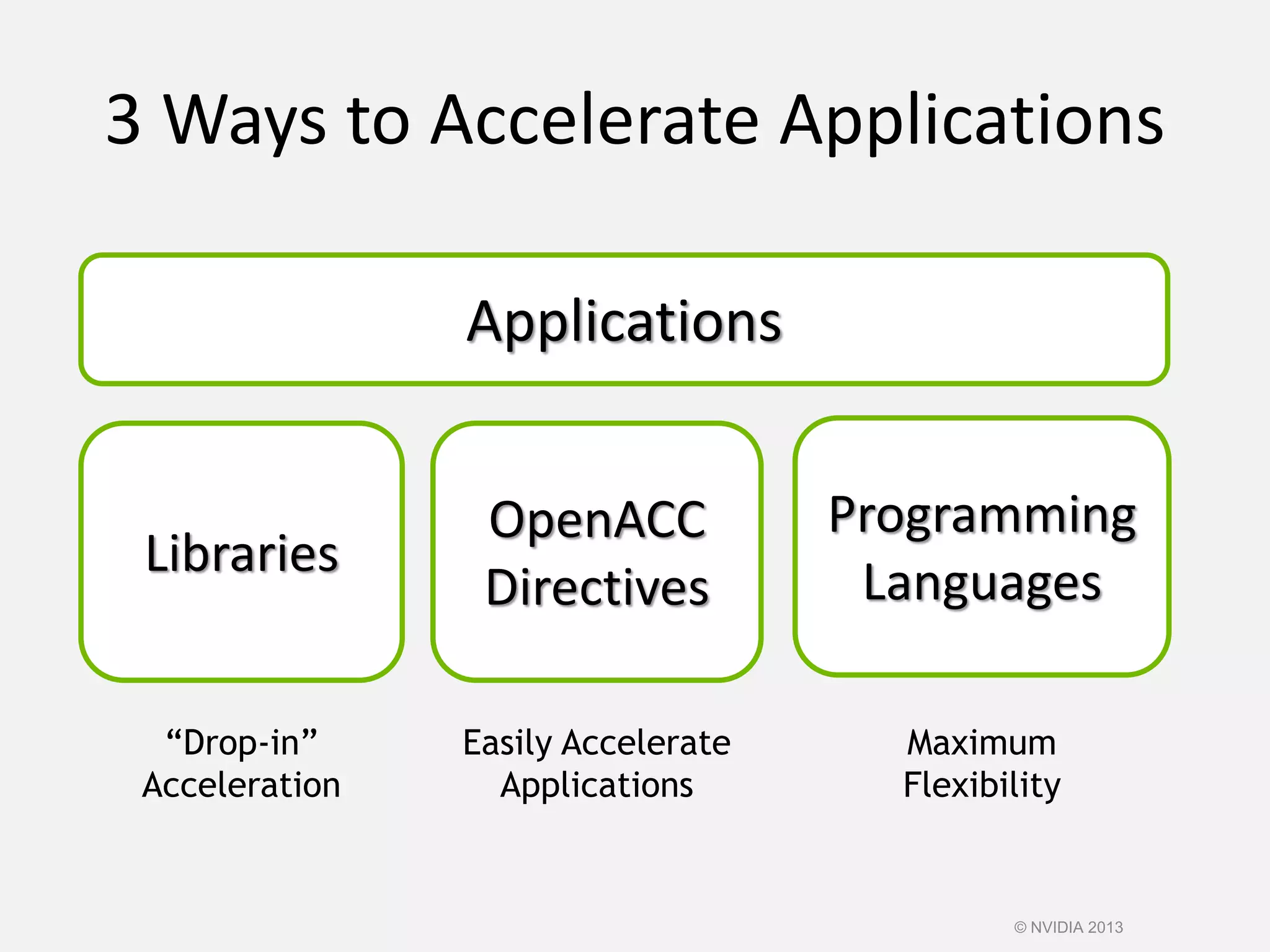
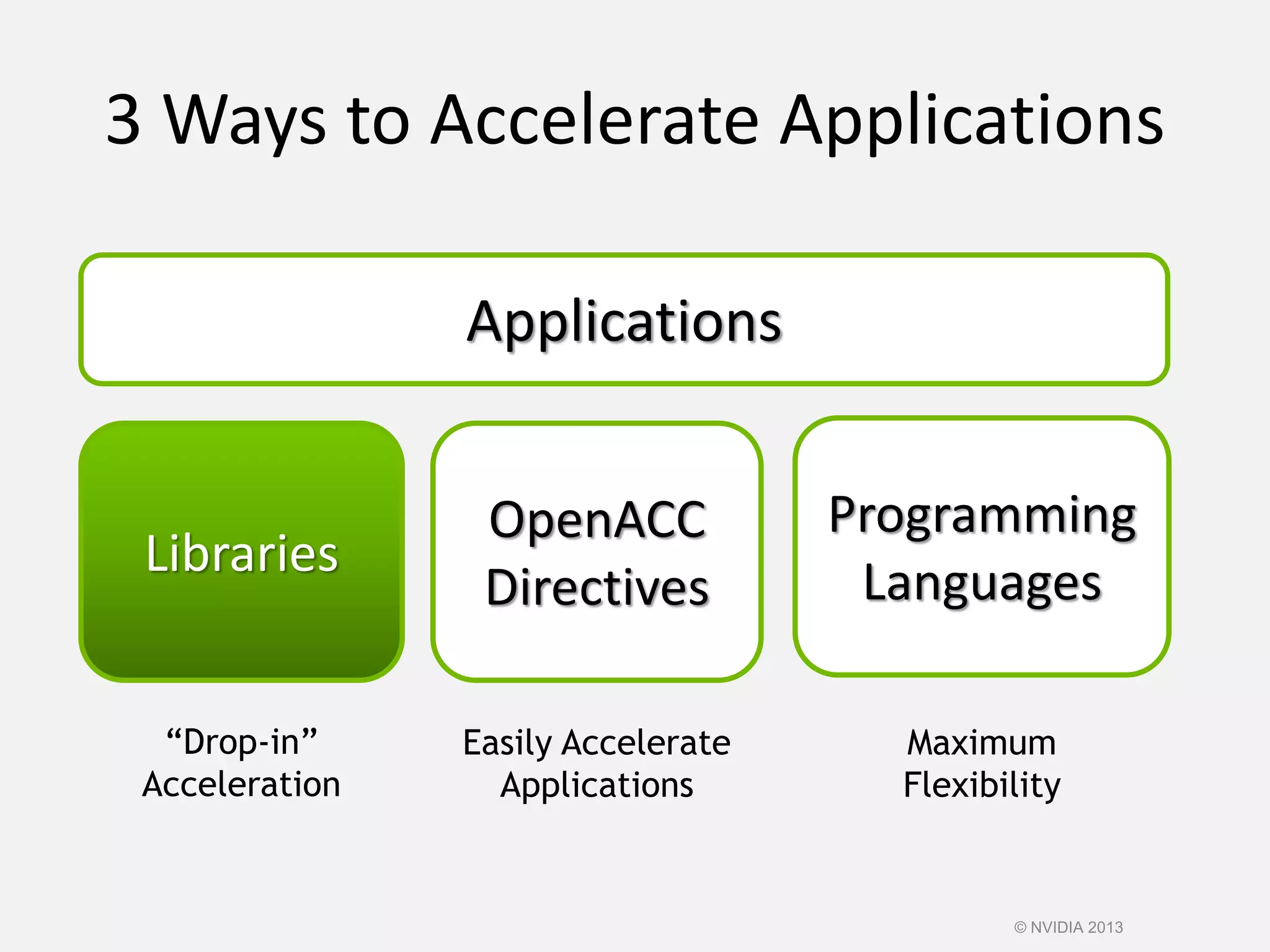
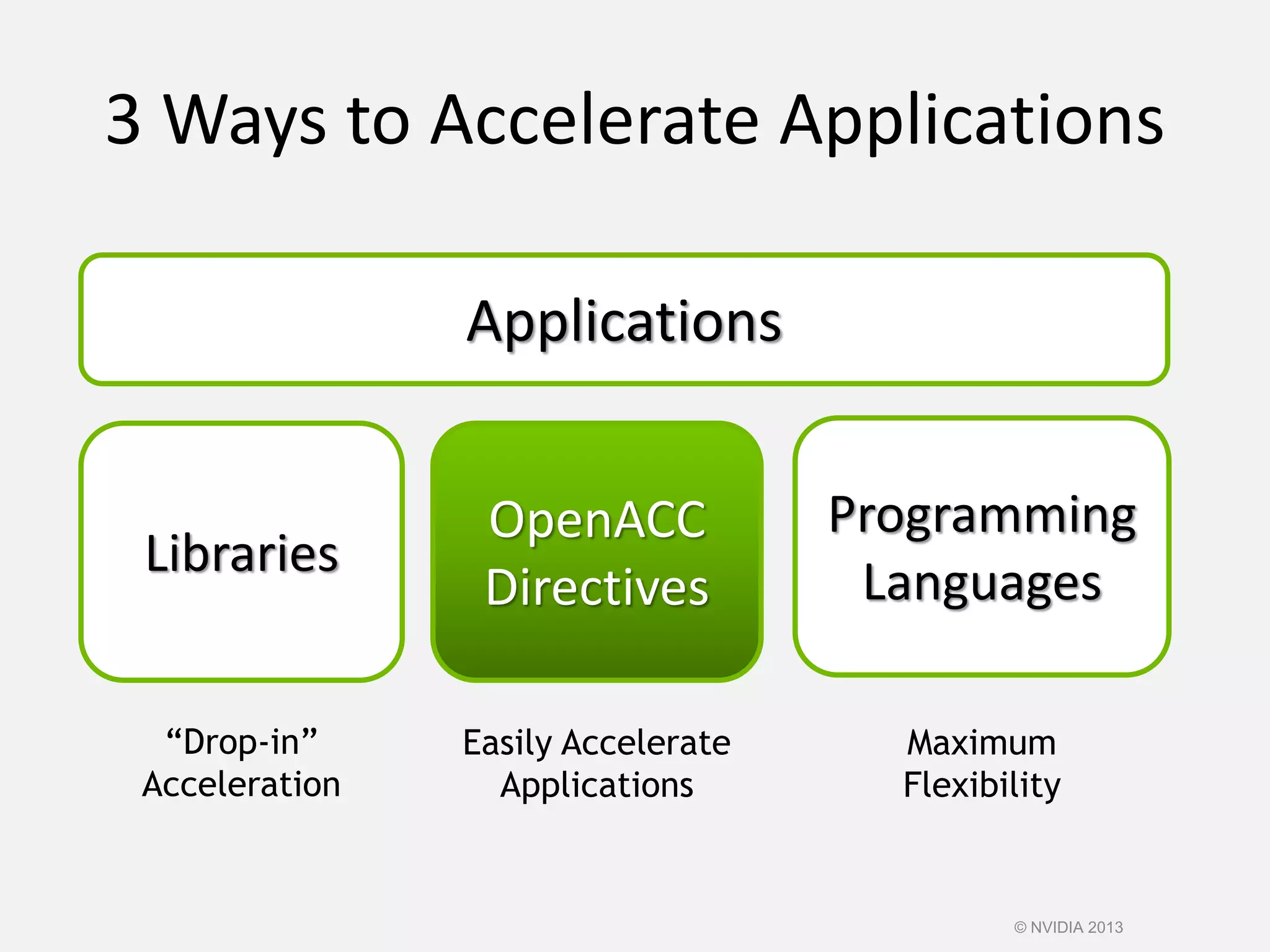
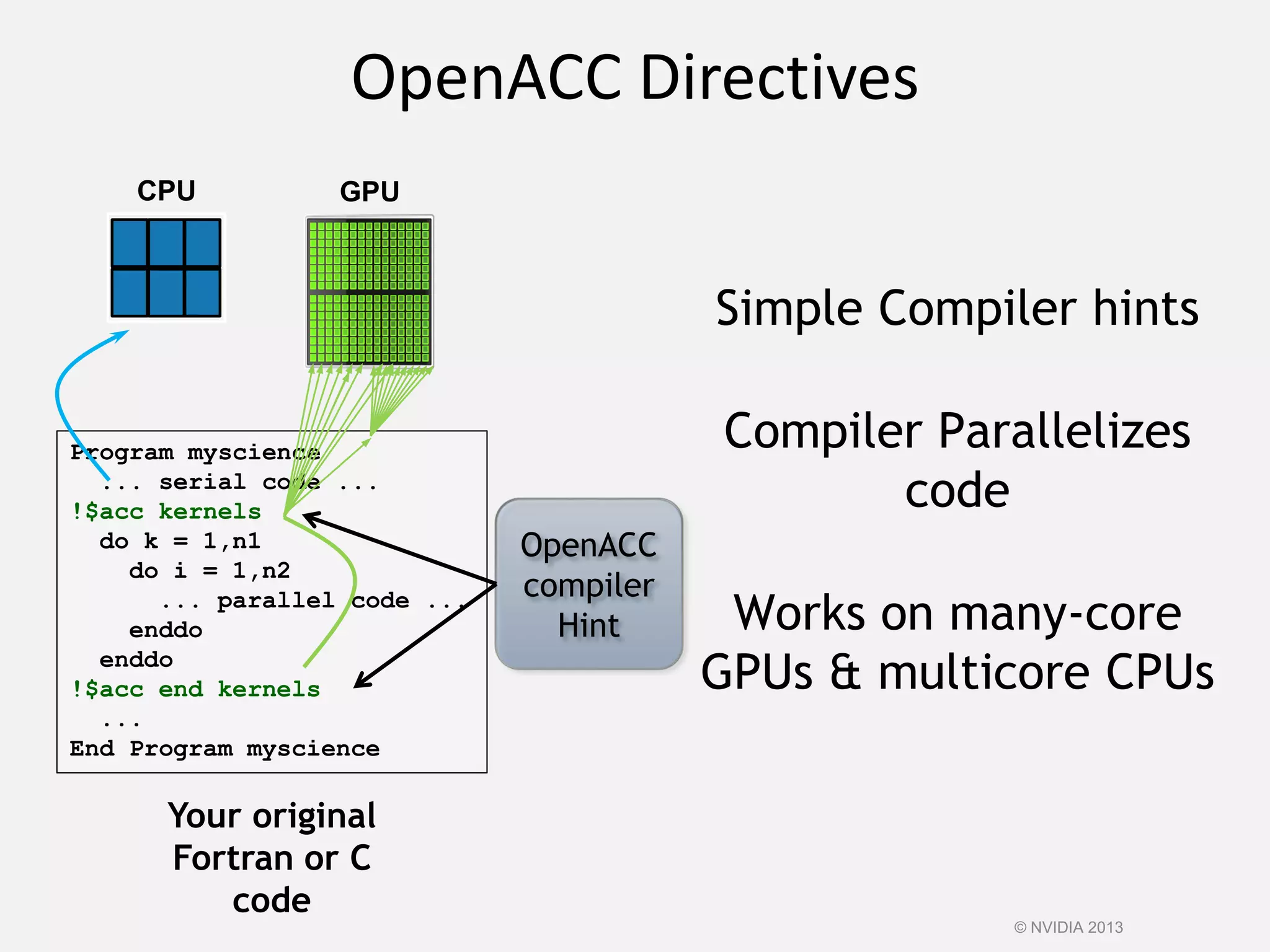
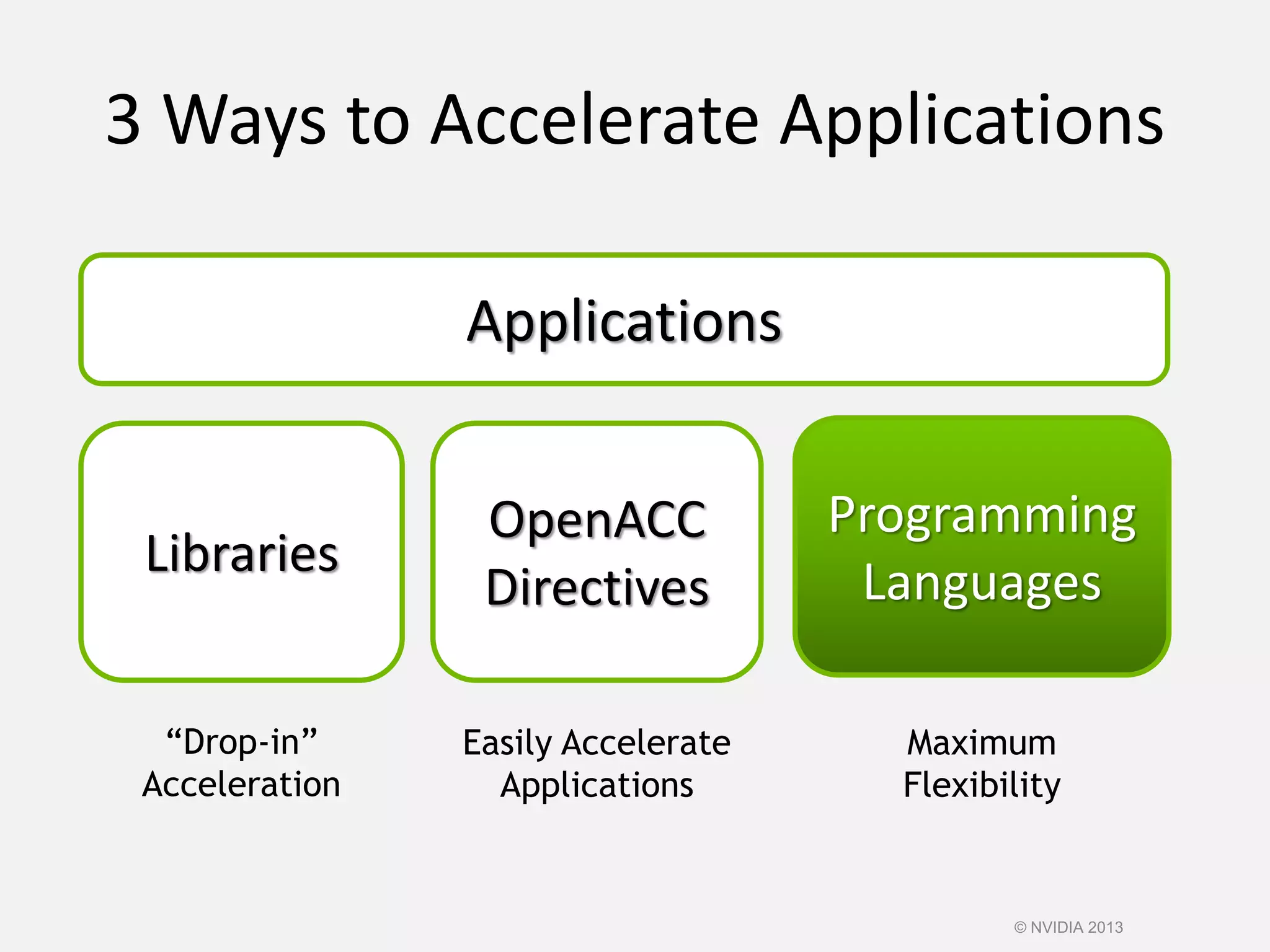
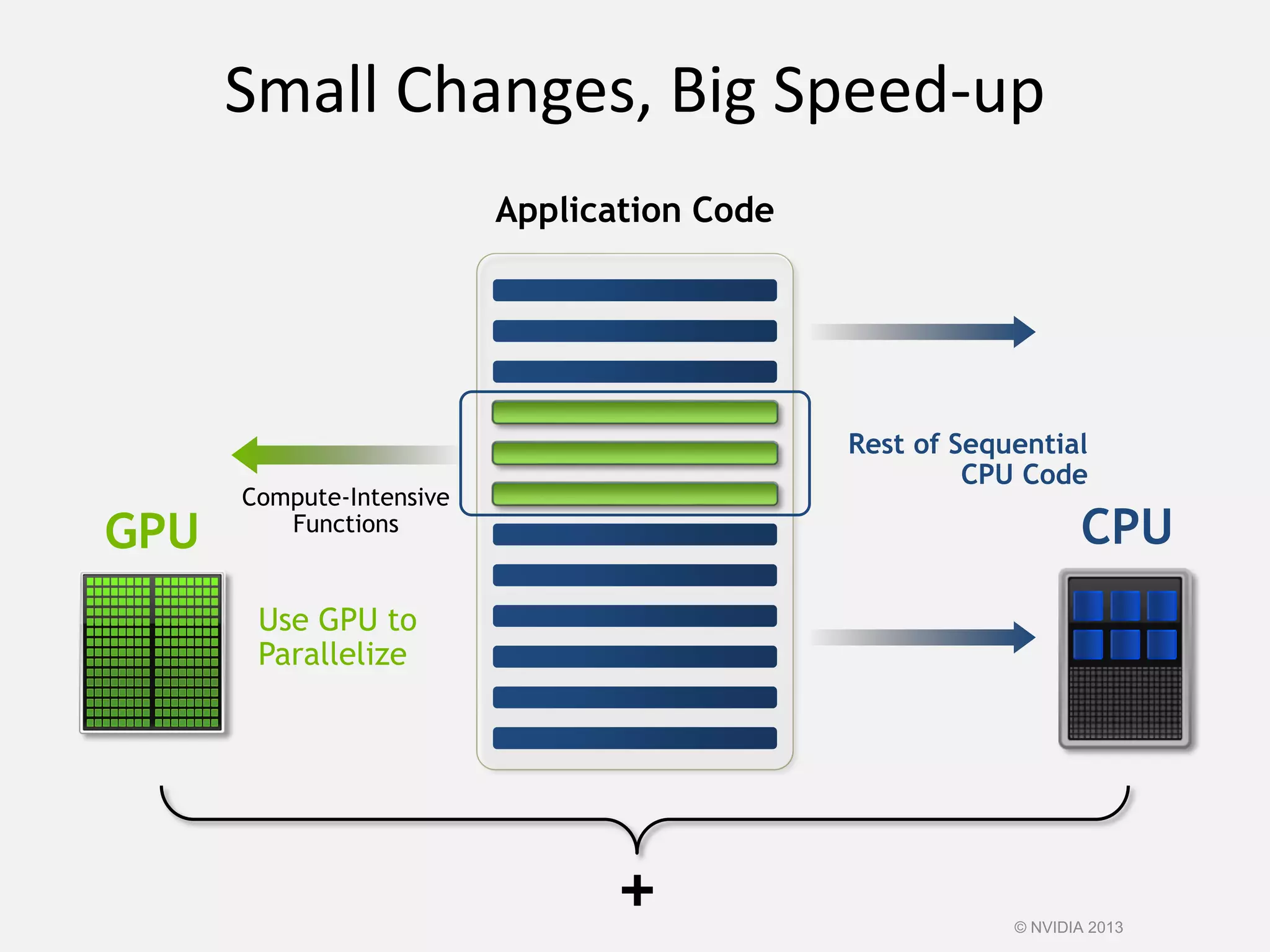
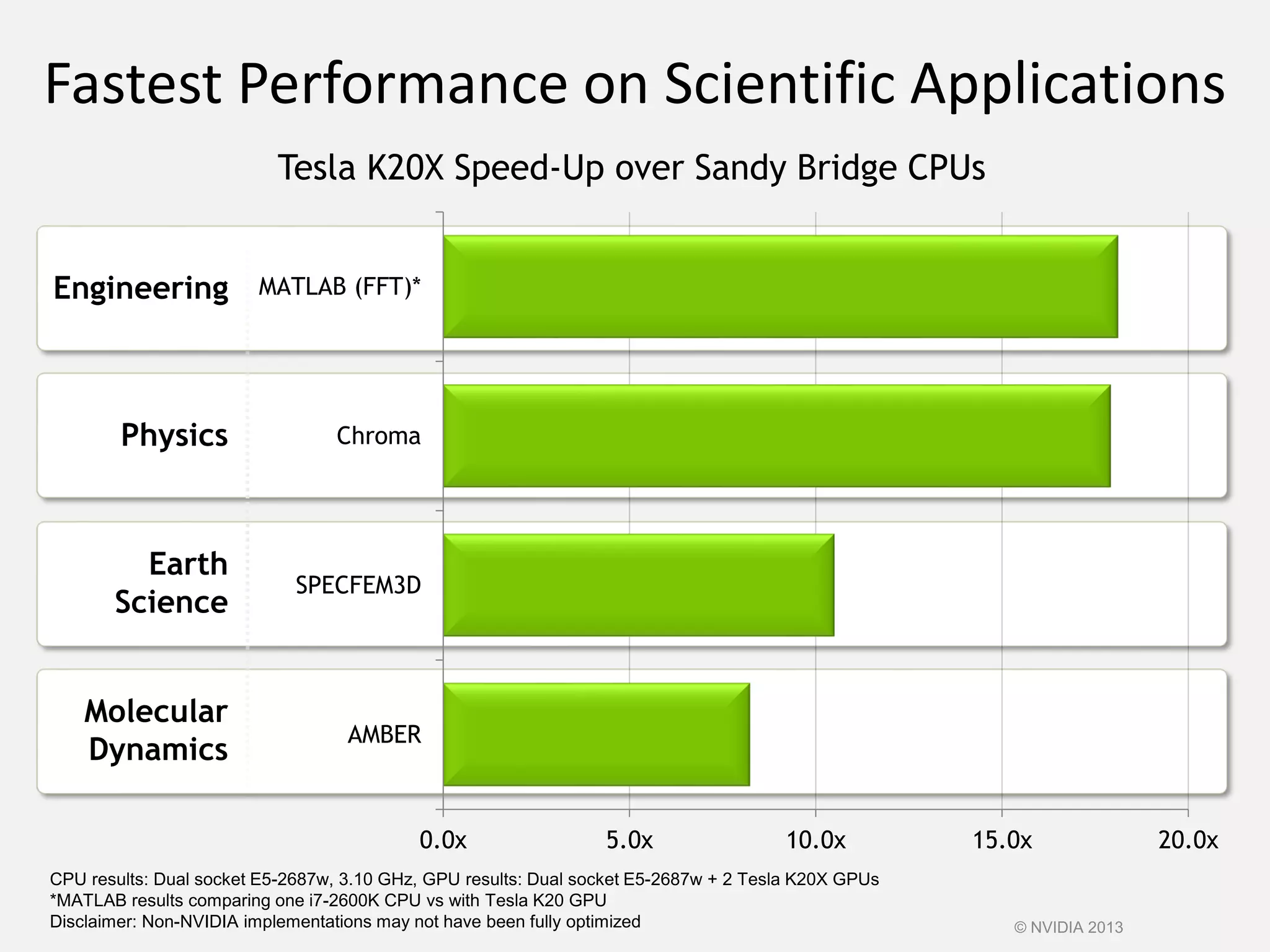
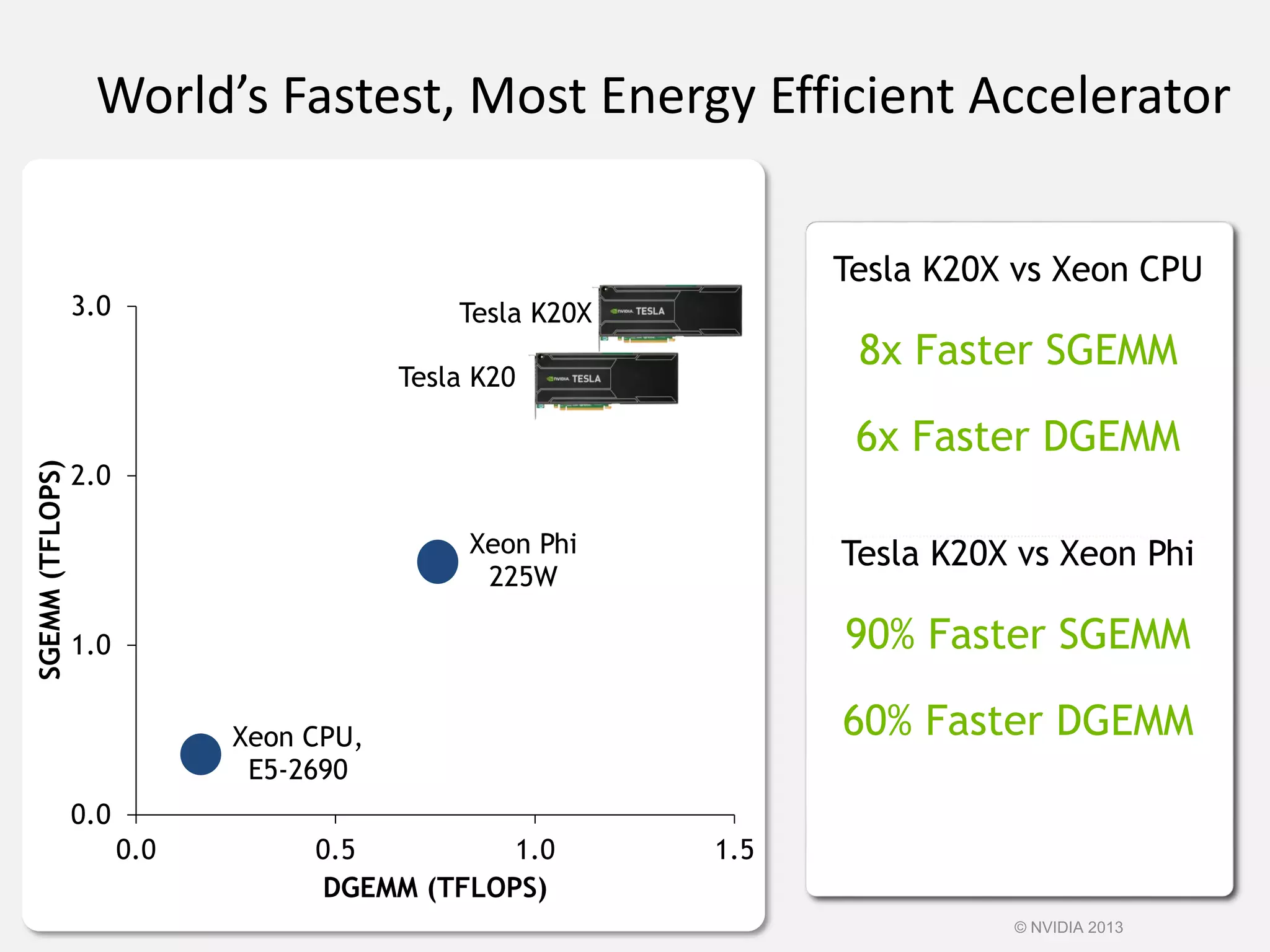
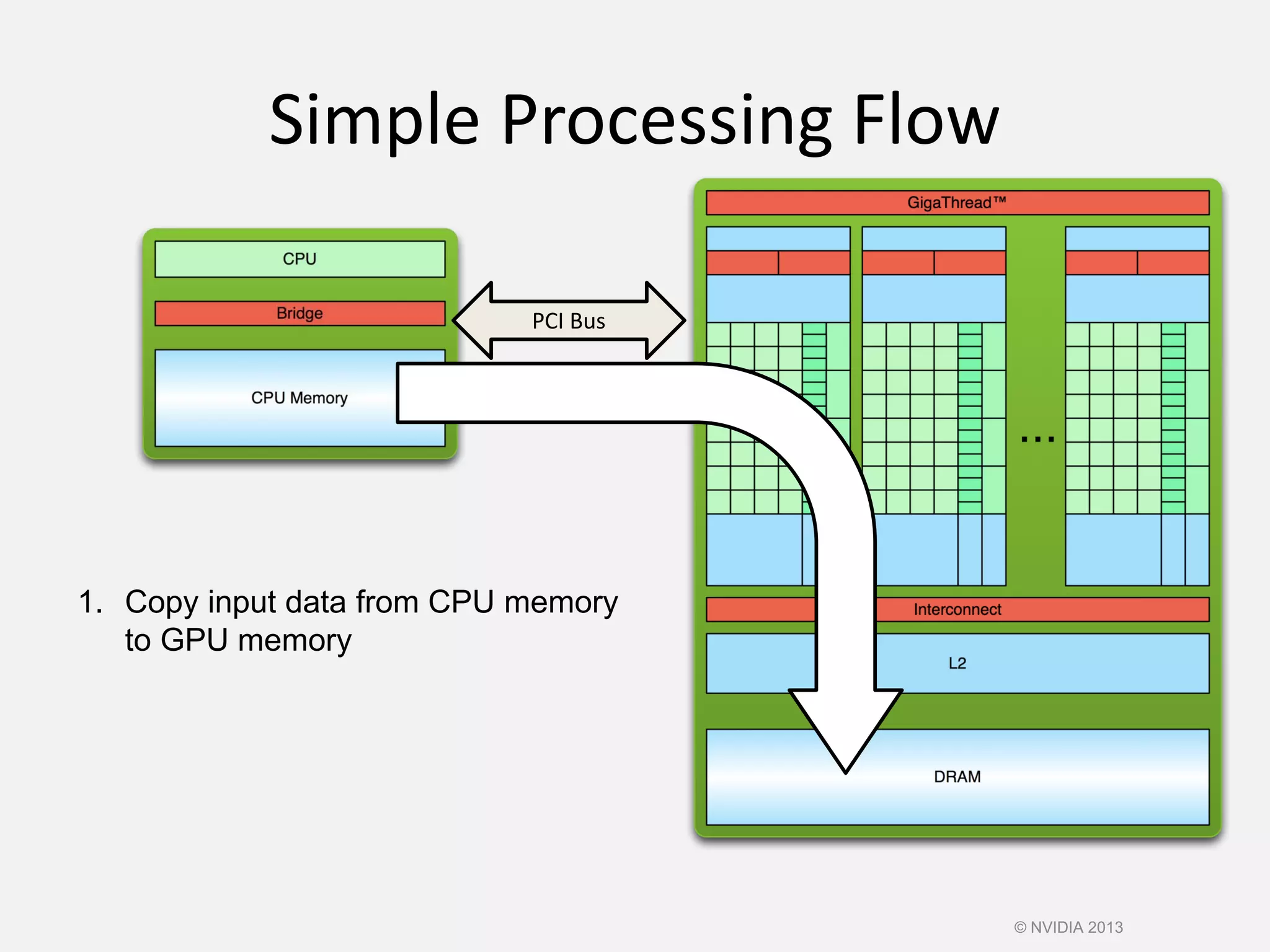
This document provides an introduction to the CUDA parallel computing platform from NVIDIA. It discusses the CUDA hardware capabilities including GPUDirect, Dynamic Parallelism, and HyperQ. It then outlines three main programming approaches for CUDA: using libraries, OpenACC directives, and programming languages. It provides examples of libraries like cuBLAS and cuRAND. For OpenACC, it shows how to add directives to existing Fortran/C code to parallelize loops. And for languages, it lists supports like CUDA C/C++, CUDA Fortran, Python with PyCUDA etc. The document aims to provide developers with maximum flexibility in choosing the best approach to accelerate their applications using CUDA and GPUs.




















![Heterogeneous Computing
#include <iostream>
#include <algorithm>
using namespace std;
#define N 1024
#define RADIUS 3
#define BLOCK_SIZE 16
__global__ void stencil_1d(int *in, int *out) {
__shared__ int temp[BLOCK_SIZE + 2 * RADIUS];
int gindex = threadIdx.x + blockIdx.x * blockDim.x;
int lindex = threadIdx.x + RADIUS;
// Read input elements into shared memory
temp[lindex] = in[gindex];
if (threadIdx.x < RADIUS) {
temp[lindex - RADIUS] = in[gindex - RADIUS];
temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE];
}
// Synchronize (ensure all the data is available)
__syncthreads();
// Apply the stencil
int result = 0;
for (int offset = -RADIUS ; offset <= RADIUS ; offset++)
result += temp[lindex + offset];
// Store the result
out[gindex] = result;
}
void fill_ints(int *x, int n) {
fill_n(x, n, 1);
}
int main(void) {
int *in, *out; // host copies of a, b, c
int *d_in, *d_out; // device copies of a, b, c
int size = (N + 2*RADIUS) * sizeof(int);
// Alloc space for host copies and setup values
in = (int *)malloc(size); fill_ints(in, N + 2*RADIUS);
out = (int *)malloc(size); fill_ints(out, N + 2*RADIUS);
// Alloc space for device copies
cudaMalloc((void **)&d_in, size);
cudaMalloc((void **)&d_out, size);
// Copy to device
cudaMemcpy(d_in, in, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_out, out, size, cudaMemcpyHostToDevice);
// Launch stencil_1d() kernel on GPU
stencil_1d<<<N/BLOCK_SIZE,BLOCK_SIZE>>>(d_in + RADIUS,
d_out + RADIUS);
// Copy result back to host
cudaMemcpy(out, d_out, size, cudaMemcpyDeviceToHost);
// Cleanup
free(in); free(out);
cudaFree(d_in); cudaFree(d_out);
return 0;
}
serial code
parallel code
serial code
parallel fn
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-32-2048.jpg)
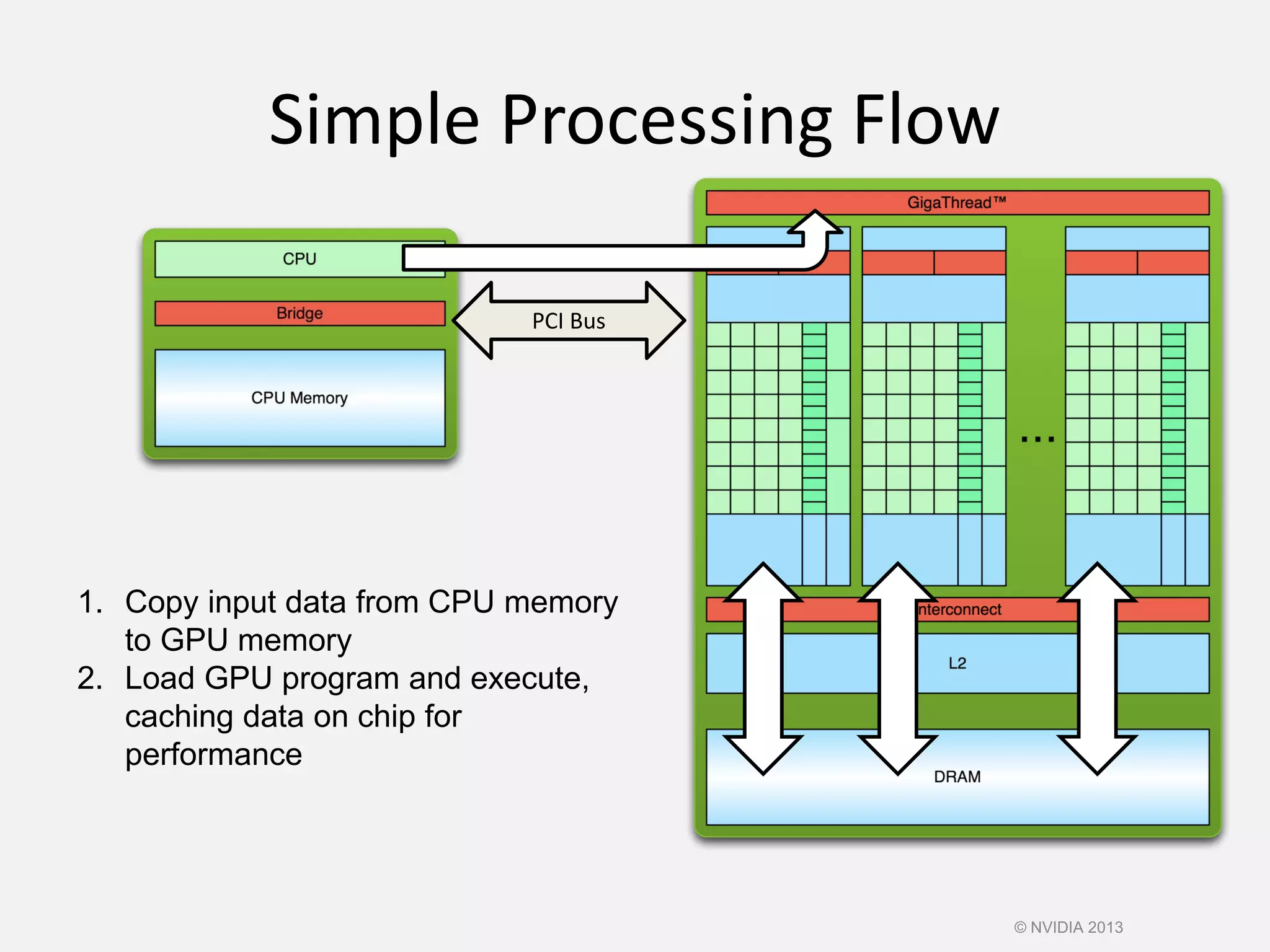














![Vector Addition on the Device
• With add() running in parallel we can do vector addition
• Terminology: each parallel invocation of add() is referred to
as a block
– The set of blocks is referred to as a grid
– Each invocation can refer to its block index using blockIdx.x
__global__ void add(int *a, int *b, int *c) {
c[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x];
}
• By using blockIdx.x to index into the array, each block handles
a different index
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-50-2048.jpg)
![Vector Addition on the Device
__global__ void add(int *a, int *b, int *c) {
c[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x];
}
• On the device, each block can execute in parallel:
c[0] = a[0] + b[0]; c[1] = a[1] + b[1]; c[2] = a[2] + b[2]; c[3] = a[3] + b[3];
Block 0 Block 1 Block 2 Block 3
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-51-2048.jpg)
![Vector Addition on the Device: add()
• Returning to our parallelized add() kernel
__global__ void add(int *a, int *b, int *c) {
c[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x];
}
• Let’s take a look at main()…
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-52-2048.jpg)





![CUDA Threads
• Terminology: a block can be split into parallel threads
• Let’s change add() to use parallel threads instead of
parallel blocks
• We use threadIdx.x instead of blockIdx.x
• Need to make one change in main()…
__global__ void add(int *a, int *b, int *c) {
c[threadIdx.x] = a[threadIdx.x] + b[threadIdx.x];
}
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-58-2048.jpg)






![Vector Addition with Blocks and
Threads
• What changes need to be made in main()?
• Use the built-in variable blockDim.x for threads per
block
int index = threadIdx.x + blockIdx.x * blockDim.x;
• Combined version of add() to use parallel
threads and parallel blocks
__global__ void add(int *a, int *b, int *c) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
c[index] = a[index] + b[index];
}
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-65-2048.jpg)


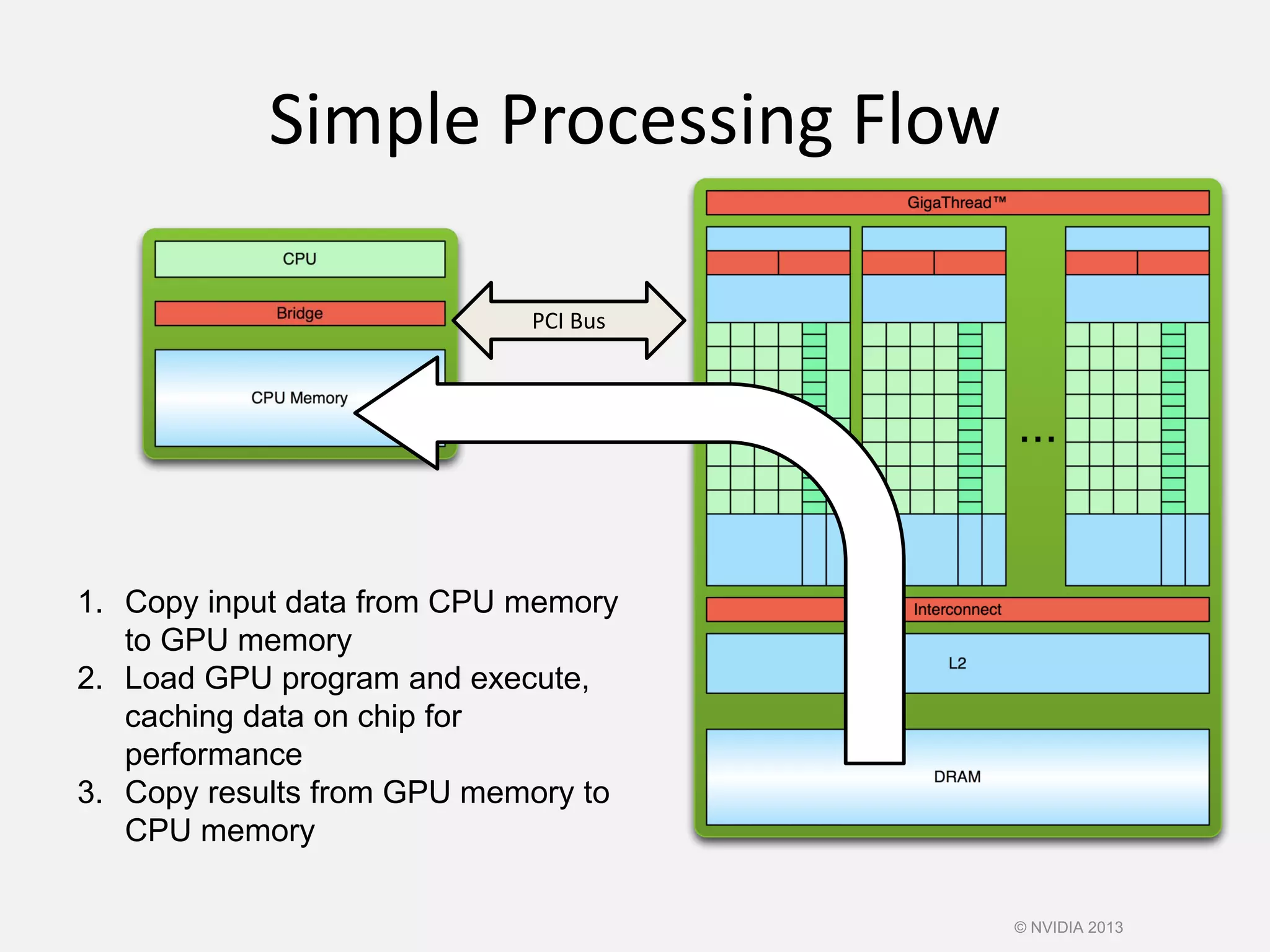
![Handling Arbitrary Vector Sizes
• Update the kernel launch:
add<<<(N + M-1) / M,M>>>(d_a, d_b, d_c, N);
• Typical problems are not friendly multiples of
blockDim.x
• Avoid accessing beyond the end of the arrays:
__global__ void add(int *a, int *b, int *c, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
if (index < n)
c[index] = a[index] + b[index];
}
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-68-2048.jpg)





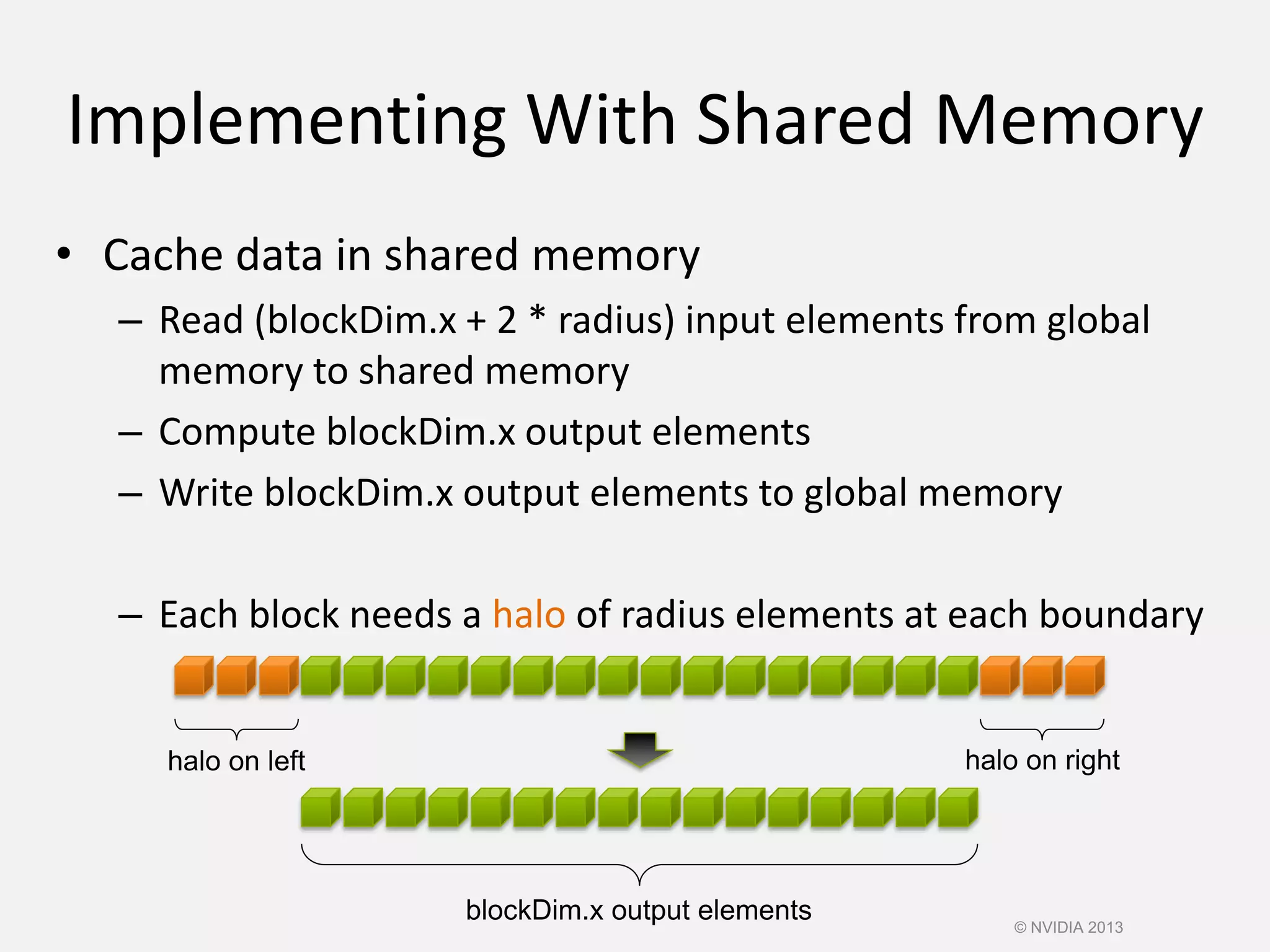
![__global__ void stencil_1d(int *in, int *out) {
__shared__ int temp[BLOCK_SIZE + 2 * RADIUS];
int gindex = threadIdx.x + blockIdx.x * blockDim.x;
int lindex = threadIdx.x + RADIUS;
// Read input elements into shared memory
temp[lindex] = in[gindex];
if (threadIdx.x < RADIUS) {
temp[lindex - RADIUS] = in[gindex - RADIUS];
temp[lindex + BLOCK_SIZE] =
in[gindex + BLOCK_SIZE];
}
© NVIDIA 2013
Stencil Kernel](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-75-2048.jpg)
![// Apply the stencil
int result = 0;
for (int offset = -RADIUS ; offset <= RADIUS ; offset++)
result += temp[lindex + offset];
// Store the result
out[gindex] = result;
}
Stencil Kernel
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-76-2048.jpg)
![Data Race!
© NVIDIA 2013
The stencil example will not work…
Suppose thread 15 reads the halo before thread 0 has fetched it…
temp[lindex] = in[gindex];
if (threadIdx.x < RADIUS) {
temp[lindex – RADIUS = in[gindex – RADIUS];
temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE];
}
int result = 0;
result += temp[lindex + 1];
Store at temp[18]
Load from temp[19]
Skipped, threadIdx > RADIUS](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-77-2048.jpg)

![Stencil Kernel
__global__ void stencil_1d(int *in, int *out) {
__shared__ int temp[BLOCK_SIZE + 2 * RADIUS];
int gindex = threadIdx.x + blockIdx.x * blockDim.x;
int lindex = threadIdx.x + radius;
// Read input elements into shared memory
temp[lindex] = in[gindex];
if (threadIdx.x < RADIUS) {
temp[lindex – RADIUS] = in[gindex – RADIUS];
temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE];
}
// Synchronize (ensure all the data is available)
__syncthreads();
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-79-2048.jpg)
![Stencil Kernel
// Apply the stencil
int result = 0;
for (int offset = -RADIUS ; offset <= RADIUS ; offset++)
result += temp[lindex + offset];
// Store the result
out[gindex] = result;
}
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-80-2048.jpg)








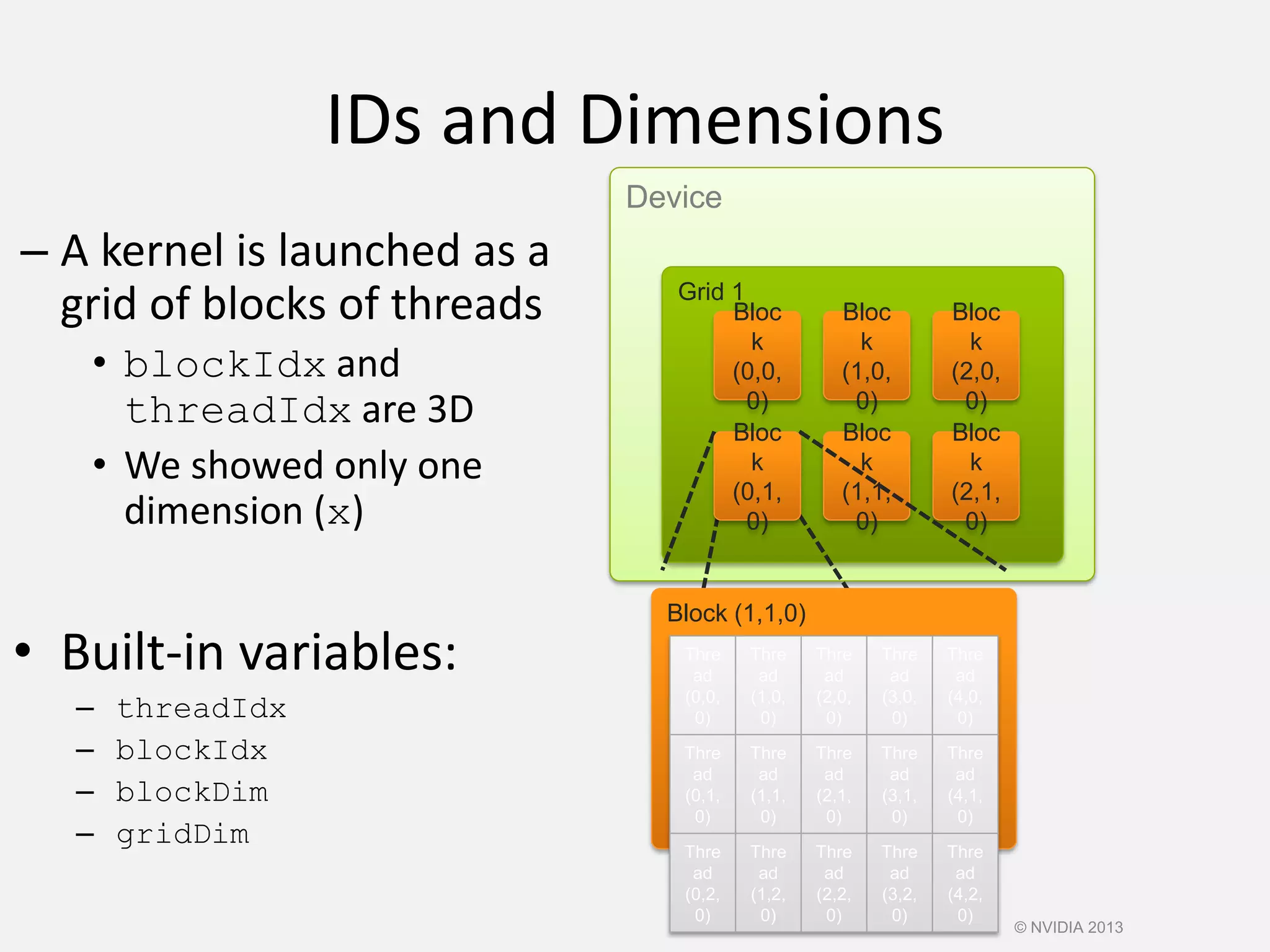






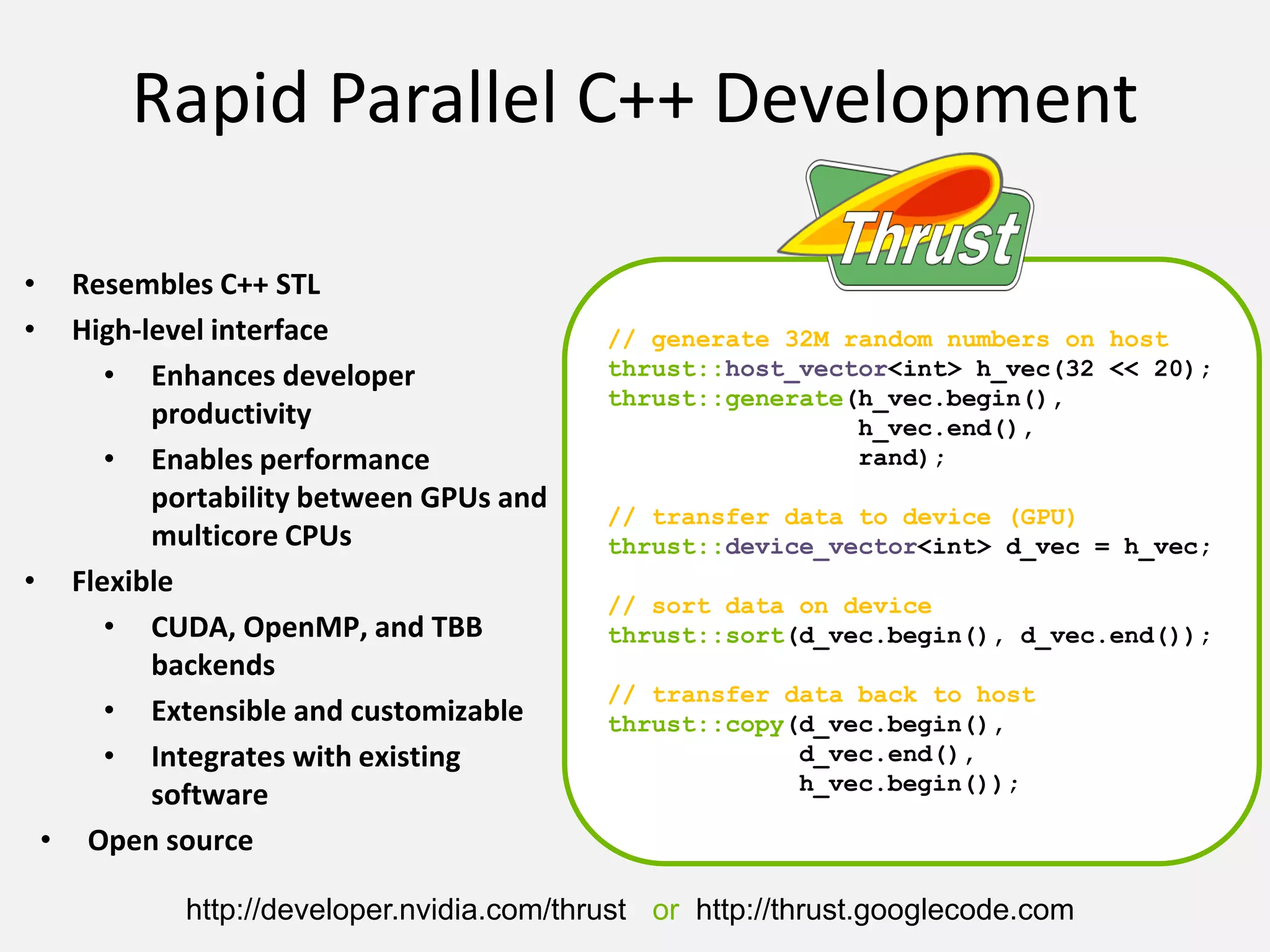
![Productivity
• Containers
host_vector
device_vector
• Memory Mangement
– Allocation
– Transfers
• Algorithm Selection
– Location is implicit
// allocate host vector with two elements
thrust::host_vector<int> h_vec(2);
// copy host data to device memory
thrust::device_vector<int> d_vec = h_vec;
// write device values from the host
d_vec[0] = 27;
d_vec[1] = 13;
// read device values from the host
int sum = d_vec[0] + d_vec[1];
// invoke algorithm on device
thrust::sort(d_vec.begin(), d_vec.end());
// memory automatically released](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-97-2048.jpg)










![int N = 1 << 20;
// Perform SAXPY on 1M elements: y[]=a*x[]+y[]
saxpy(N, 2.0, d_x, 1, d_y, 1);
Drop-In Acceleration (Step 1)
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-111-2048.jpg)
![int N = 1 << 20;
// Perform SAXPY on 1M elements: d_y[]=a*d_x[]+d_y[]
cublasSaxpy(N, 2.0, d_x, 1, d_y, 1);
Drop-In Acceleration (Step 1)
Add “cublas” prefix
and use device
variables
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-112-2048.jpg)
![int N = 1 << 20;
cublasInit();
// Perform SAXPY on 1M elements: d_y[]=a*d_x[]+d_y[]
cublasSaxpy(N, 2.0, d_x, 1, d_y, 1);
cublasShutdown();
Drop-In Acceleration (Step 2)
Initialize CUBLAS
Shut down CUBLAS
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-113-2048.jpg)
![int N = 1 << 20;
cublasInit();
cublasAlloc(N, sizeof(float), (void**)&d_x);
cublasAlloc(N, sizeof(float), (void*)&d_y);
// Perform SAXPY on 1M elements: d_y[]=a*d_x[]+d_y[]
cublasSaxpy(N, 2.0, d_x, 1, d_y, 1);
cublasFree(d_x);
cublasFree(d_y);
cublasShutdown();
Drop-In Acceleration (Step 2)
Allocate device
vectors
Deallocate device
vectors
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-114-2048.jpg)
![int N = 1 << 20;
cublasInit();
cublasAlloc(N, sizeof(float), (void**)&d_x);
cublasAlloc(N, sizeof(float), (void*)&d_y);
cublasSetVector(N, sizeof(x[0]), x, 1, d_x, 1);
cublasSetVector(N, sizeof(y[0]), y, 1, d_y, 1);
// Perform SAXPY on 1M elements: d_y[]=a*d_x[]+d_y[]
cublasSaxpy(N, 2.0, d_x, 1, d_y, 1);
cublasGetVector(N, sizeof(y[0]), d_y, 1, y, 1);
cublasFree(d_x);
cublasFree(d_y);
cublasShutdown();
Drop-In Acceleration (Step 2)
Transfer data to GPU
Read data back GPU
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-115-2048.jpg)


![subroutine saxpy(n, a, x, y)
real :: x(:), y(:), a
integer :: n, i
$!acc kernels
do i=1,n
y(i) = a*x(i)+y(i)
enddo
$!acc end kernels
end subroutine saxpy
...
$ Perform SAXPY on 1M elements
call saxpy(2**20, 2.0, x_d, y_d)
...
void saxpy(int n,
float a,
float *x,
float *restrict y)
{
#pragma acc kernels
for (int i = 0; i < n; ++i)
y[i] = a*x[i] + y[i];
}
...
// Perform SAXPY on 1M elements
saxpy(1<<20, 2.0, x, y);
...
A Very Simple Exercise: SAXPY
© NVIDIA 2013
SAXPY in C SAXPY in Fortran](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-118-2048.jpg)
![Directive Syntax
• Fortran
!$acc directive [clause [,] clause] …]
Often paired with a matching end directive surrounding
a structured code block
!$acc end directive
• C
#pragma acc directive [clause [,] clause] …]
Often followed by a structured code block
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-119-2048.jpg)
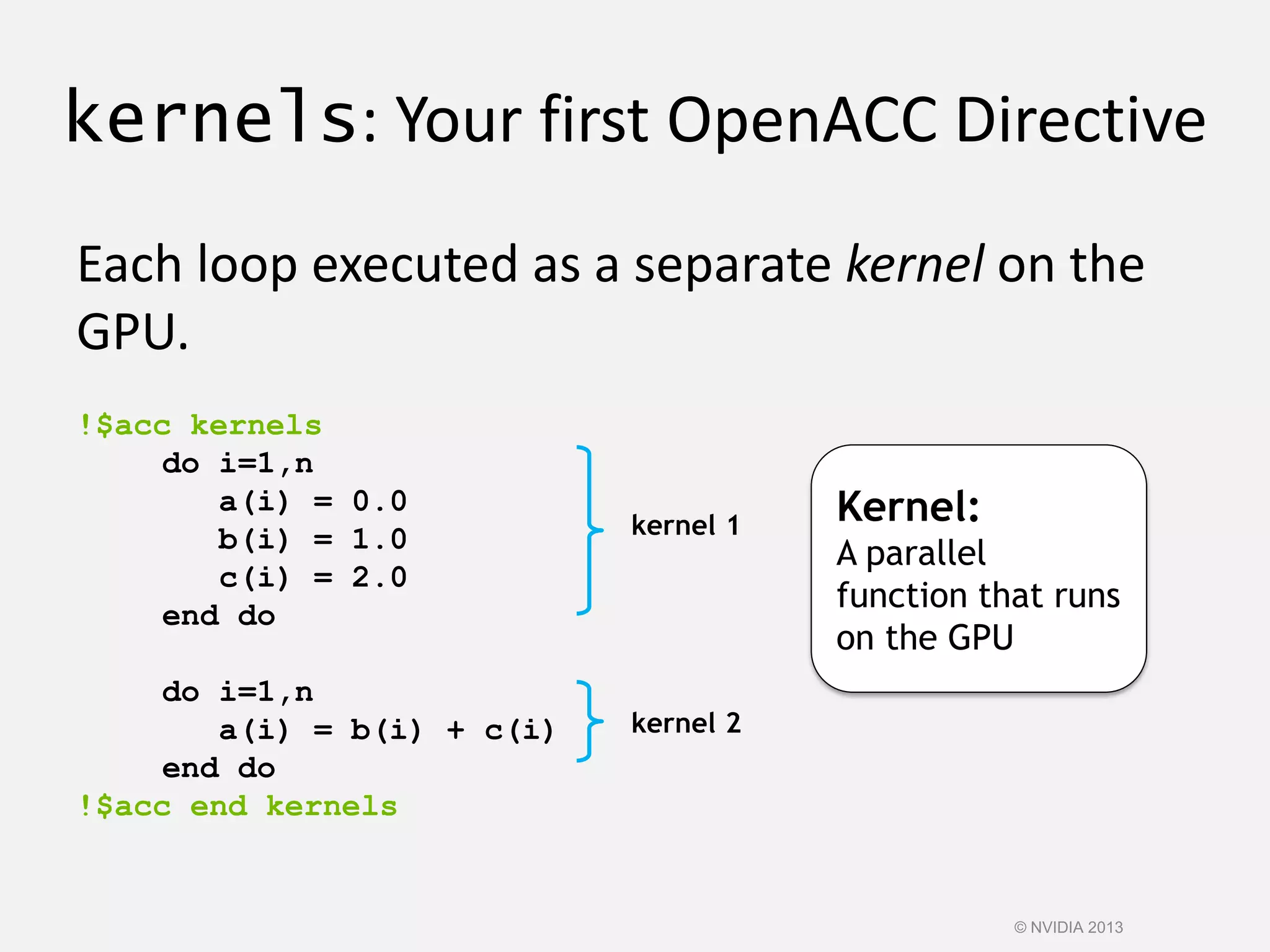
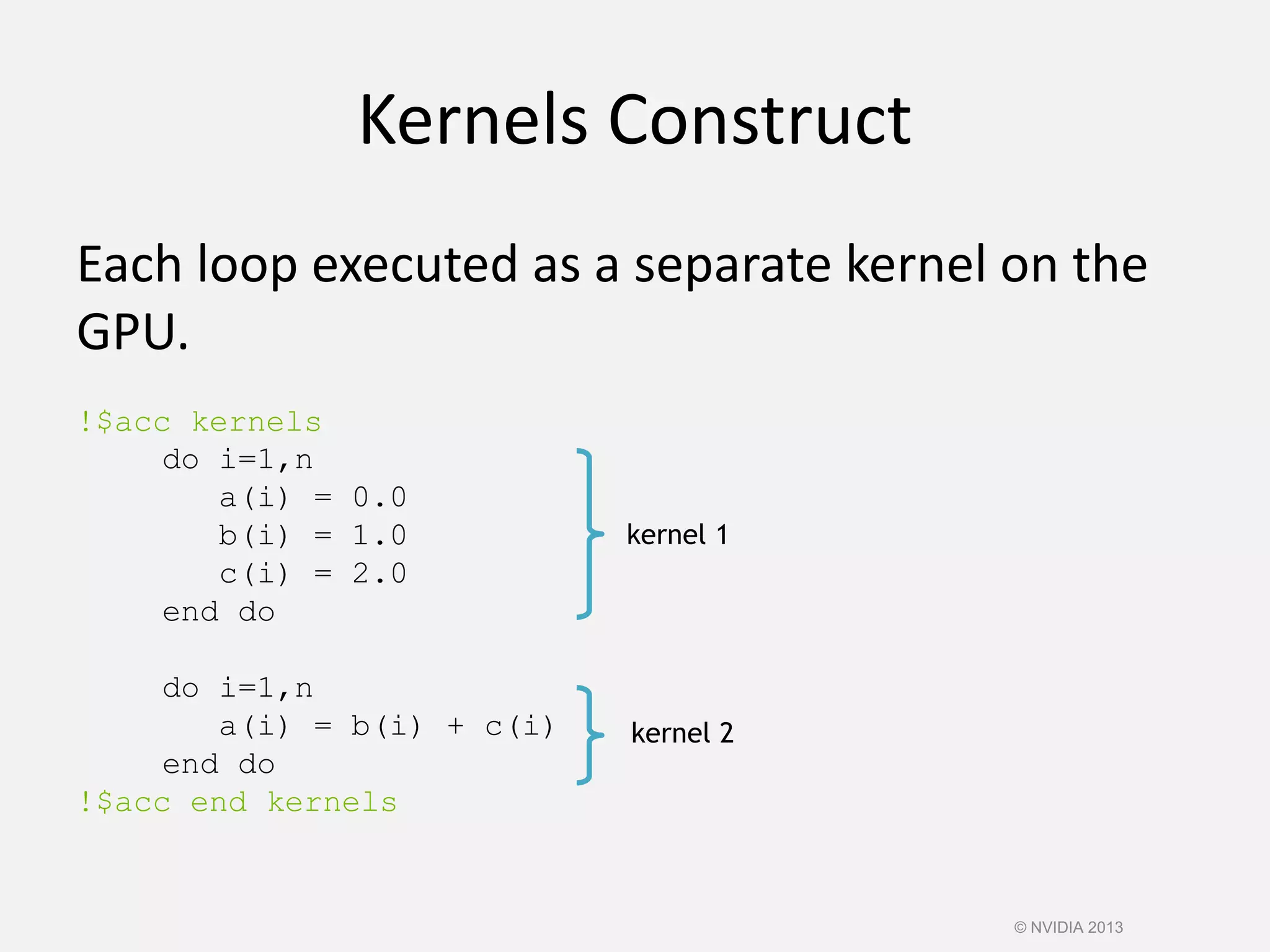
![Kernels Construct
Fortran
!$acc kernels [clause …]
structured block
!$acc end kernels
Clauses
if( condition )
async( expression )
Also, any data clause (more later)
C
#pragma acc kernels [clause …]
{ structured block }
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-121-2048.jpg)

![Complete SAXPY example code
• Trivial first example
– Apply a loop directive
– Learn compiler commands
#include <stdlib.h>
void saxpy(int n,
float a,
float *x,
float *restrict y)
{
#pragma acc kernels
for (int i = 0; i < n; ++i)
y[i] = a * x[i] + y[i];
}
int main(int argc, char **argv)
{
int N = 1<<20; // 1 million floats
if (argc > 1)
N = atoi(argv[1]);
float *x = (float*)malloc(N * sizeof(float));
float *y = (float*)malloc(N * sizeof(float));
for (int i = 0; i < N; ++i)
{
x[i] = 2.0f;
y[i] = 1.0f;
}
saxpy(N, 3.0f, x, y);
return 0;
}
*restrict:
“I promise y does not
alias x”
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-123-2048.jpg)
![Compile and run
• C:
pgcc –acc -ta=nvidia -Minfo=accel –o saxpy_acc saxpy.c
• Fortran:
pgf90 –acc -ta=nvidia -Minfo=accel –o saxpy_acc saxpy.f90
• Compiler output:
pgcc -acc -Minfo=accel -ta=nvidia -o saxpy_acc saxpy.c
saxpy:
8, Generating copyin(x[:n-1])
Generating copy(y[:n-1])
Generating compute capability 1.0 binary
Generating compute capability 2.0 binary
9, Loop is parallelizable
Accelerator kernel generated
9, #pragma acc loop worker, vector(256) /* blockIdx.x threadIdx.x */
CC 1.0 : 4 registers; 52 shared, 4 constant, 0 local memory bytes; 100% occupancy
CC 2.0 : 8 registers; 4 shared, 64 constant, 0 local memory bytes; 100% occupancy
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-124-2048.jpg)

![Jacobi Iteration C Code
while ( error > tol && iter < iter_max )
{
error=0.0;
for( int j = 1; j < n-1; j++) {
for(int i = 1; i < m-1; i++) {
Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] +
A[j-1][i] + A[j+1][i]);
error = max(error, abs(Anew[j][i] - A[j][i]);
}
}
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
A[j][i] = Anew[j][i];
}
}
iter++;
}
Iterate until converged
Iterate across matrix
elements
Calculate new value
from neighbors
Compute max error for
convergence
Swap input/output
arrays
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-126-2048.jpg)

![OpenMP C Code
while ( error > tol && iter < iter_max ) {
error=0.0;
#pragma omp parallel for shared(m, n, Anew, A)
for( int j = 1; j < n-1; j++) {
for(int i = 1; i < m-1; i++) {
Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] +
A[j-1][i] + A[j+1][i]);
error = max(error, abs(Anew[j][i] - A[j][i]);
}
}
#pragma omp parallel for shared(m, n, Anew, A)
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
A[j][i] = Anew[j][i];
}
}
iter++;
}
Parallelize loop across
CPU threads
Parallelize loop across
CPU threads
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-128-2048.jpg)


![First Attempt: OpenACC C
while ( error > tol && iter < iter_max ) {
error=0.0;
#pragma acc kernels
for( int j = 1; j < n-1; j++) {
for(int i = 1; i < m-1; i++) {
Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] +
A[j-1][i] + A[j+1][i]);
error = max(error, abs(Anew[j][i] - A[j][i]);
}
}
#pragma acc kernels
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
A[j][i] = Anew[j][i];
}
}
iter++;
}
Execute GPU kernel for
loop nest
Execute GPU kernel for
loop nest
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-131-2048.jpg)

![First Attempt: Compiler output (C)
pgcc -acc -ta=nvidia -Minfo=accel -o laplace2d_acc laplace2d.c
main:
57, Generating copyin(A[:4095][:4095])
Generating copyout(Anew[1:4094][1:4094])
Generating compute capability 1.3 binary
Generating compute capability 2.0 binary
58, Loop is parallelizable
60, Loop is parallelizable
Accelerator kernel generated
58, #pragma acc loop worker, vector(16) /* blockIdx.y threadIdx.y */
60, #pragma acc loop worker, vector(16) /* blockIdx.x threadIdx.x */
Cached references to size [18x18] block of 'A'
CC 1.3 : 17 registers; 2656 shared, 40 constant, 0 local memory bytes; 75% occupancy
CC 2.0 : 18 registers; 2600 shared, 80 constant, 0 local memory bytes; 100% occupancy
64, Max reduction generated for error
69, Generating copyout(A[1:4094][1:4094])
Generating copyin(Anew[1:4094][1:4094])
Generating compute capability 1.3 binary
Generating compute capability 2.0 binary
70, Loop is parallelizable
72, Loop is parallelizable
Accelerator kernel generated
70, #pragma acc loop worker, vector(16) /* blockIdx.y threadIdx.y */
72, #pragma acc loop worker, vector(16) /* blockIdx.x threadIdx.x */
CC 1.3 : 8 registers; 48 shared, 8 constant, 0 local memory bytes; 100% occupancy
CC 2.0 : 10 registers; 8 shared, 56 constant, 0 local memory bytes; 100% occupancy
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-133-2048.jpg)

![Excessive Data Transfers
while ( error > tol && iter < iter_max )
{
error=0.0;
...
}
#pragma acc kernels
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++) {
Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] +
A[j-1][i] + A[j+1][i]);
error = max(error, abs(Anew[j][i] - A[j][i]);
}
}
A, Anew resident on host
A, Anew resident on host
A, Anew resident on accelerator
A, Anew resident on accelerator
These copies
happen every
iteration of the
outer while loop!*
Copy
Copy
*Note: there are two #pragma acc kernels, so there are 4 copies per while loop iteration!
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-136-2048.jpg)

![Data Construct
Fortran
!$acc data [clause …]
structured block
!$acc end data
General Clauses
if( condition )
async( expression )
C
#pragma acc data [clause …]
{ structured block }
Manage data movement. Data regions may be
nested.
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-138-2048.jpg)
![Data Clauses
copy ( list ) Allocates memory on GPU and copies data
from host to GPU when entering region and
copies data to the host when exiting region.
copyin ( list ) Allocates memory on GPU and copies data from
host to GPU when entering region.
copyout ( list ) Allocates memory on GPU and copies data to the
host when exiting region.
create ( list ) Allocates memory on GPU but does not copy.
present ( list ) Data is already present on GPU from another containing
data region.
and present_or_copy[in|out], present_or_create, deviceptr.
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-139-2048.jpg)
![Array Shaping
• Compiler sometimes cannot determine size of arrays
– Must specify explicitly using data clauses and array “shape”
• C
#pragma acc data copyin(a[0:size-1]), copyout(b[s/4:3*s/4])
• Fortran
!$pragma acc data copyin(a(1:size)), copyout(b(s/4:3*s/4))
• Note: data clauses can be used on data, kernels or
parallel
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-140-2048.jpg)
![Update Construct
Fortran
!$acc update [clause …]
Clauses
host( list )
device( list )
C
#pragma acc update [clause …]
if( expression )
async( expression )
Used to update existing data after it has changed in its
corresponding copy (e.g. update device copy after host copy
changes)
Move data from GPU to host, or host to GPU.
Data movement can be conditional, and asynchronous.
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-141-2048.jpg)
![Second Attempt: OpenACC C
#pragma acc data copy(A), create(Anew)
while ( error > tol && iter < iter_max ) {
error=0.0;
#pragma acc kernels
for( int j = 1; j < n-1; j++) {
for(int i = 1; i < m-1; i++) {
Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] +
A[j-1][i] + A[j+1][i]);
error = max(error, abs(Anew[j][i] - A[j][i]);
}
}
#pragma acc kernels
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
A[j][i] = Anew[j][i];
}
}
iter++;
}
Copy A in at beginning of
loop, out at end. Allocate
Anew on accelerator
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-142-2048.jpg)







![Kernels Construct
Fortran
!$acc kernels [clause …]
structured block
!$acc end kernels
Clauses
if( condition )
async( expression )
Also any data clause
C
#pragma acc kernels [clause …]
{ structured block }
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-150-2048.jpg)
![Parallel Construct
Fortran
!$acc parallel [clause …]
structured block
!$acc end parallel
Clauses
if( condition )
async( expression )
num_gangs( expression )
num_workers( expression )
vector_length( expression )
C
#pragma acc parallel [clause …]
{ structured block }
private( list )
firstprivate( list )
reduction( operator:list )
Also any data clause
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-152-2048.jpg)

![Loop Construct
Fortran
!$acc loop [clause …]
loop
!$acc end loop
Combined directives
!$acc parallel loop [clause …]
!$acc kernels loop [clause …]
C
#pragma acc loop [clause …]
{ loop }
!$acc parallel loop [clause …]
!$acc kernels loop [clause …]
Detailed control of the parallel execution of the
following loop.
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-154-2048.jpg)


![Loop Clauses Inside kernels Region
gang [( num_gangs )] Shares iterations across across
at most num_gangs gangs.
worker [( num_workers )] Shares iterations across at
most num_workers of a single
gang.
vector [( vector_length )] Execute the iterations in SIMD
mode with maximum
vector_length.
independent Specify that the loop iterations
are independent.
© NVIDIA 2013](https://image.slidesharecdn.com/cuda-151213044927/75/Cuda-157-2048.jpg)



























































































