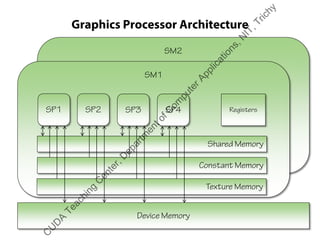
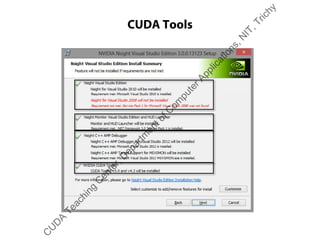
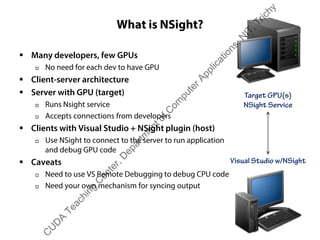
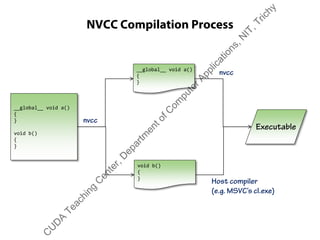
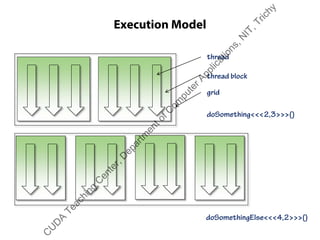
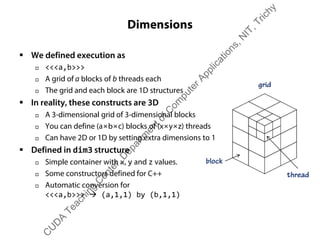
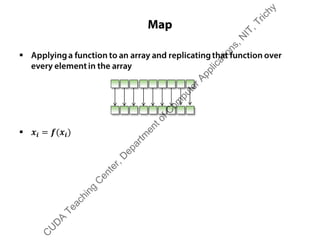
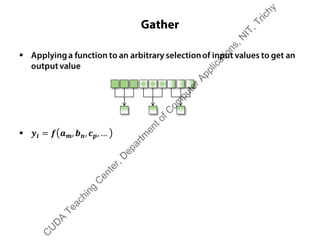
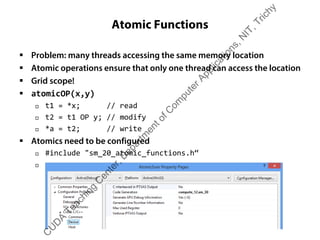
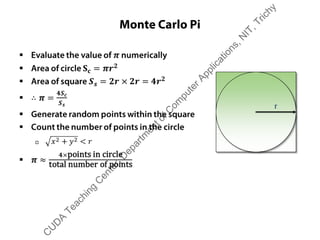
The document outlines a course on GPU architecture and CUDA programming. It covers GPU architecture overview, CUDA tools, CUDA C introduction, parallel computing patterns, thread cooperation and synchronization, memory types, atomic operations, events and streams, and advanced CUDA scenarios. Programming GPUs requires a CUDA capable GPU.





















![Reduce in Practice
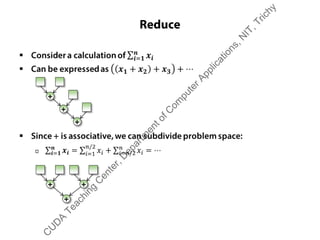
ƒ Adding up N data elements ƒ Adding up N data elements
ƒ Use 1 block of N/2 threads
ƒ Each thread does
x[i] += x[j];
ƒ At each step
† # of threads halved
† Distance (j-i) doubled
ƒ x[0] is the result
1 2 3 4 5 6 7 8
3 7 11 153
0
7
1
11
2
155
3
10 260100
0
62626
1
3663636
0
C
U
D
A
Teaching
C
enter,D
epartm
entofC
om
puterApplications,N
IT,Trichy](https://image.slidesharecdn.com/cudamaterials-140314050115-phpapp01/85/Cuda-materials-30-320.jpg)

![Scan in Practice
ƒ Similar to reduce
1 2 3 4
1 3 5 73
0
5
1
1 3 6 106
0
1 3 6 10
0
7
2
10
1
ƒ Require N-1 threads
ƒ Step size keeps doubling
ƒ Number of threads reduced
by step size
ƒ Each thread n does
x[n+step] += x[n];
5
3
9
2
000000 14
000 15
C
U
D
A
Teaching
C
enter,D
epartm
entofC
om
puterApplications,N
IT,Trichy](https://image.slidesharecdn.com/cudamaterials-140314050115-phpapp01/85/Cuda-materials-32-320.jpg)
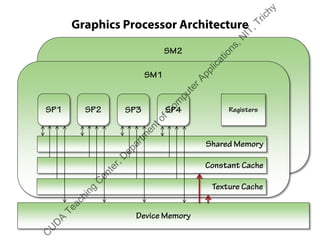
![Device Memory
ƒ Grid scope (i.e., available to all threads in all blocks in the grid)
ƒ Application lifetime (exists until app exits or explicitly deallocated)
ƒ Dynamic
† cudaMalloc() to allocate
† Pass pointer to kernel
† cudaMemcpy() to copy to/from host memory
† cudaFree() to deallocate
ƒ Static
† Declare global variable as device
__device__ int sum = 0;
† Use freely within the kernel
† Use cudaMemcpy[To/From]Symbol() to copy to/from host memory
† No need to explicitly deallocate
ƒ Slowest and most inefficient
C
U
D
A
Teaching
C
enter,D
epartm
entofC
om
puterApplications,N
IT,Trichy](https://image.slidesharecdn.com/cudamaterials-140314050115-phpapp01/85/Cuda-materials-34-320.jpg)
![Constant & Texture Memory
ƒ Read-only: useful for lookup tables, model parameters, etc.
ƒ Grid scope, Application lifetime
ƒ Resides in device memory, but
ƒ Cached in a constant memory cache
ƒ Constrained by MAX_CONSTANT_MEMORY
† Expect 64kb
ƒ Similar operation to statically-defined device memory
† Declare as __constant__
† Use freely within the kernel
† Use cudaMemcpy[To/From]Symbol() to copy to/from host memory
ƒ Very fast provided all threads read from the same location
ƒ Used for kernel arguments
ƒ Texture memory: similar to Constant, optimized for 2D access
patterns
C
U
D
A
Teaching
C
enter,D
epartm
entofC
om
puterApplications,N
IT,Trichy](https://image.slidesharecdn.com/cudamaterials-140314050115-phpapp01/85/Cuda-materials-35-320.jpg)


![Summary
Declaration Memory Scope Lifetime Slowdown
int foo; Register Thread Kernel 1x
int foo[10]; Local Thread Kernel 100x
__shared__ int foo; Shared Block Kernel 1x
__device__ int foo; Global Grid Application 100x
__constant__ int foo; Constant Grid Application 1x
C
U
D
A
Teaching
C
enter,D
epartm
entofC
om
puterApplications,N
IT,Trichy](https://image.slidesharecdn.com/cudamaterials-140314050115-phpapp01/85/Cuda-materials-38-320.jpg)


















![[Harvard CS264] 06 - CUDA Ninja Tricks: GPU Scripting, Meta-programming & Aut...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201106-cudaninjasharetmp-110301171948-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Harvard CS264] 10a - Easy, Effective, Efficient: GPU Programming in Python w...](https://cdn.slidesharecdn.com/ss_thumbnails/andreas-cs264-110331202547-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[01][gpu 컴퓨팅을 위한 언어, 도구 및 api] miller languages tools](https://cdn.slidesharecdn.com/ss_thumbnails/01gpuapimillerlanguagestools-110106231409-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[05][cuda 및 fermi 최적화 기술] hryu optimization](https://cdn.slidesharecdn.com/ss_thumbnails/05cudafermihryuoptimization-110106231451-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























