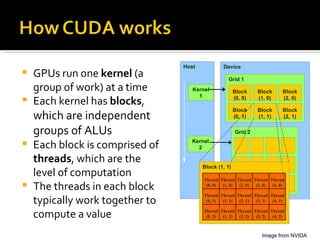
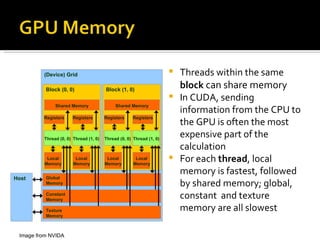
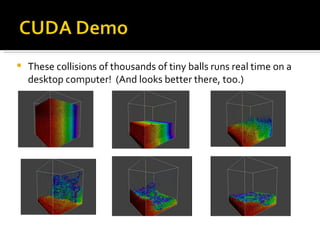
CUDA is a parallel computing platform and programming model that utilizes GPUs for accelerated computations, offering significant speedups for various applications. It allows many threads to perform calculations simultaneously, with shared and local memory used for efficient processing. CUDA is applicable in fields such as imaging, video processing, and molecular dynamics, enhancing the speed and performance of computational tasks.