Monte Carlo simulation is well-suited for GPU acceleration due to its highly parallel nature. GPUs provide lower cost and higher performance than CPUs for Monte Carlo applications. Numerical libraries for GPUs allow developers to focus on their models rather than reimplementing basic components. NAG has developed GPU libraries including random number generators and is working with financial institutions to apply Monte Carlo simulations to problems in finance.





































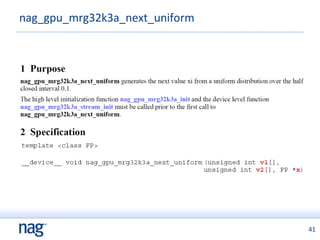

![Example program – kernel function __global__ void mrg32k3a_kernel(int np, FP *d_P){ unsigned int v1[3], v2[3]; int n, i0; FP x, x2 = nanf(""); // initialisation for first point nag_gpu_mrg32k3a_stream_init(v1, v2, np); // now do points i0 = threadIdx.x + np*blockDim.x*blockIdx.x; for (n=0; n<np; n++) { nag_gpu_mrg32k3a_next_uniform(v1, v2, x); } d_P[i0] = x; i0 += blockDim.x; }](https://image.slidesharecdn.com/montecarloongpus-12652079381209-phpapp02/85/Monte-Carlo-on-GPUs-43-320.jpg)








![Acknowledgments Mike Giles (Mathematical Institute, University of Oxford) – algorithmic input Technology Strategy Board through Knowledge Transfer Partnership with Smith Institute NVIDIA for technical support and supply of Tesla C1060 and Quadro FX 5800 See www.nag.co.uk/numeric/GPUs/ Contact: [email_address]](https://image.slidesharecdn.com/montecarloongpus-12652079381209-phpapp02/85/Monte-Carlo-on-GPUs-52-320.jpg)

















































































