Download as PDF, PPTX
























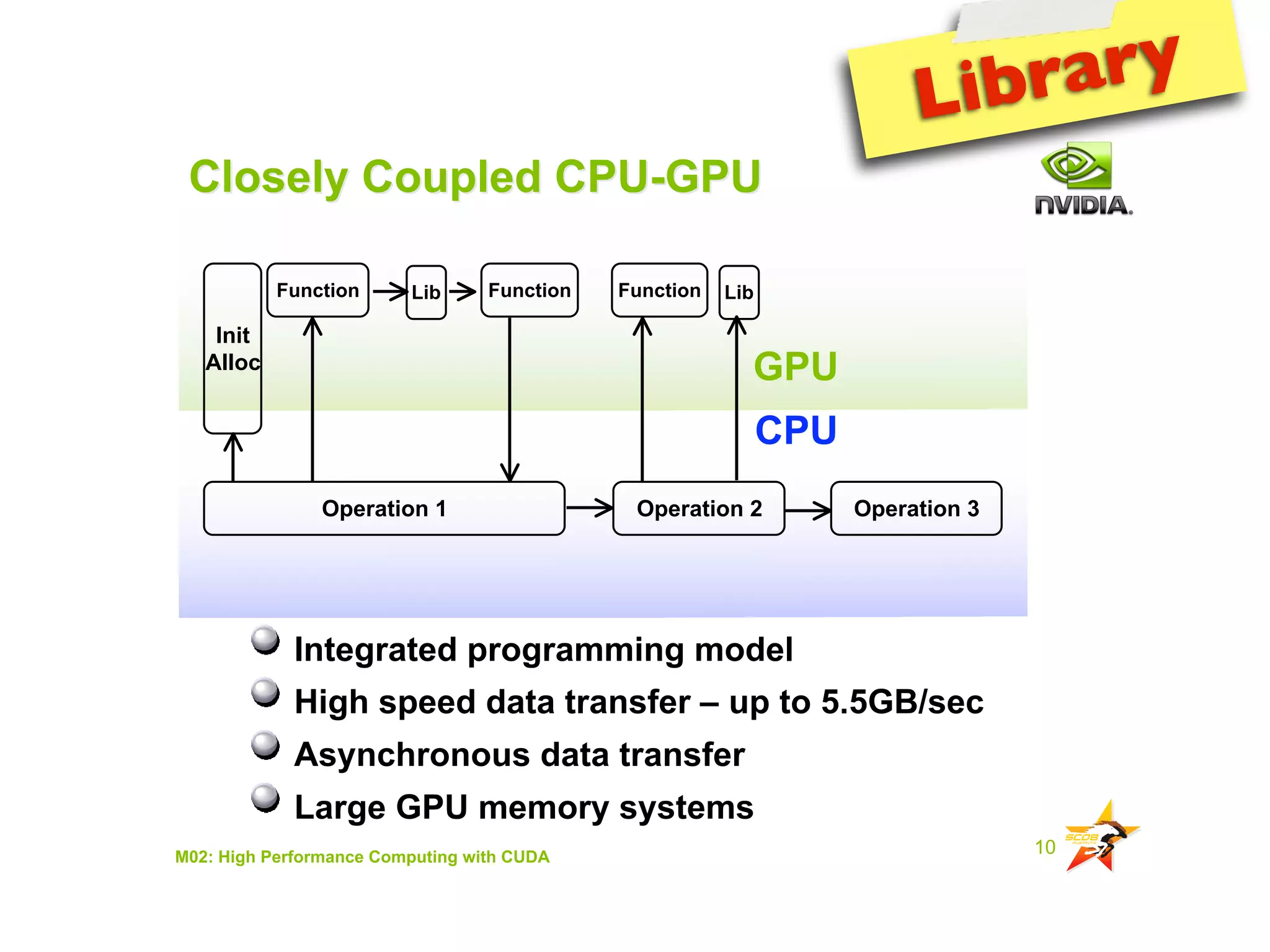








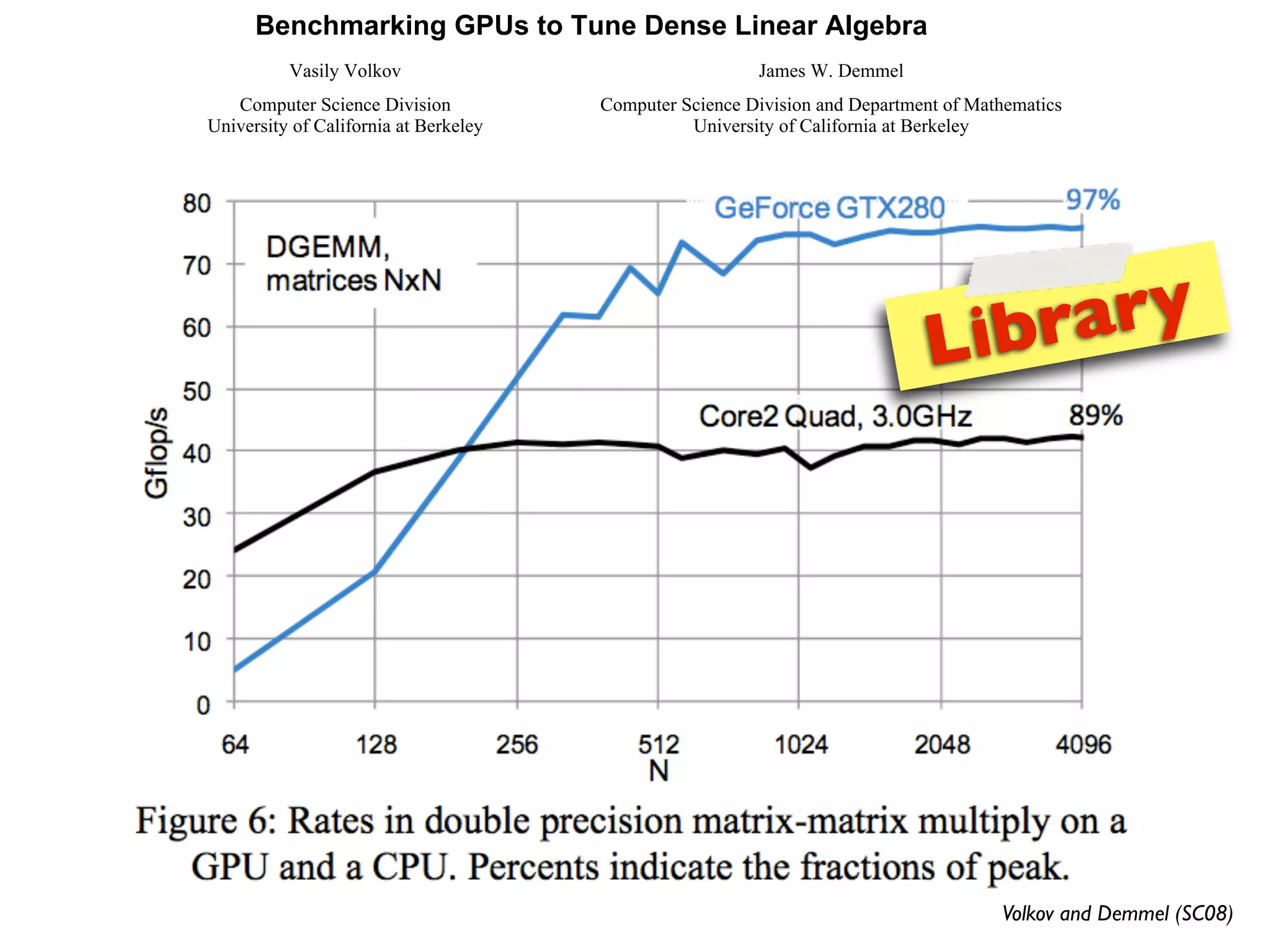
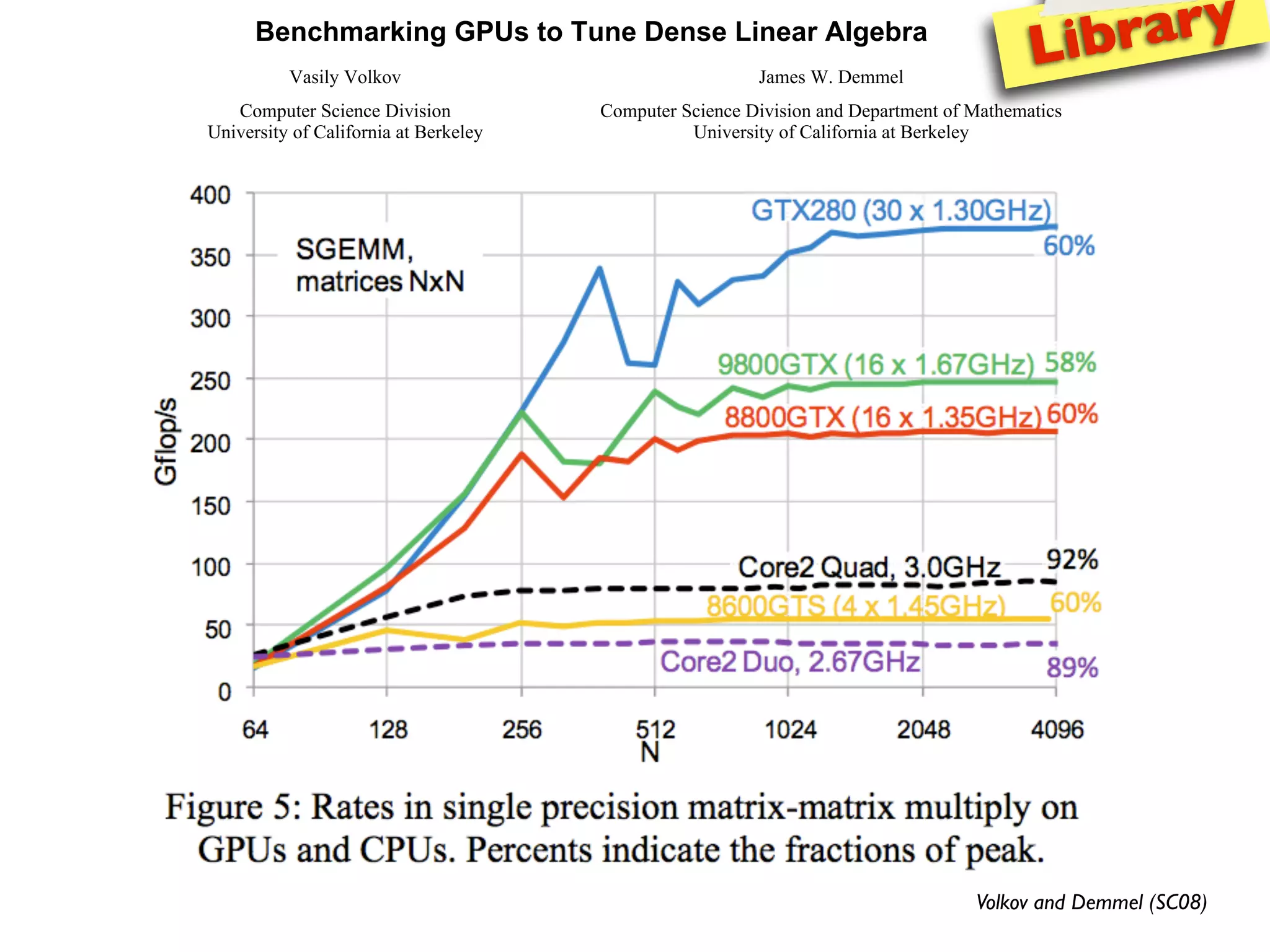
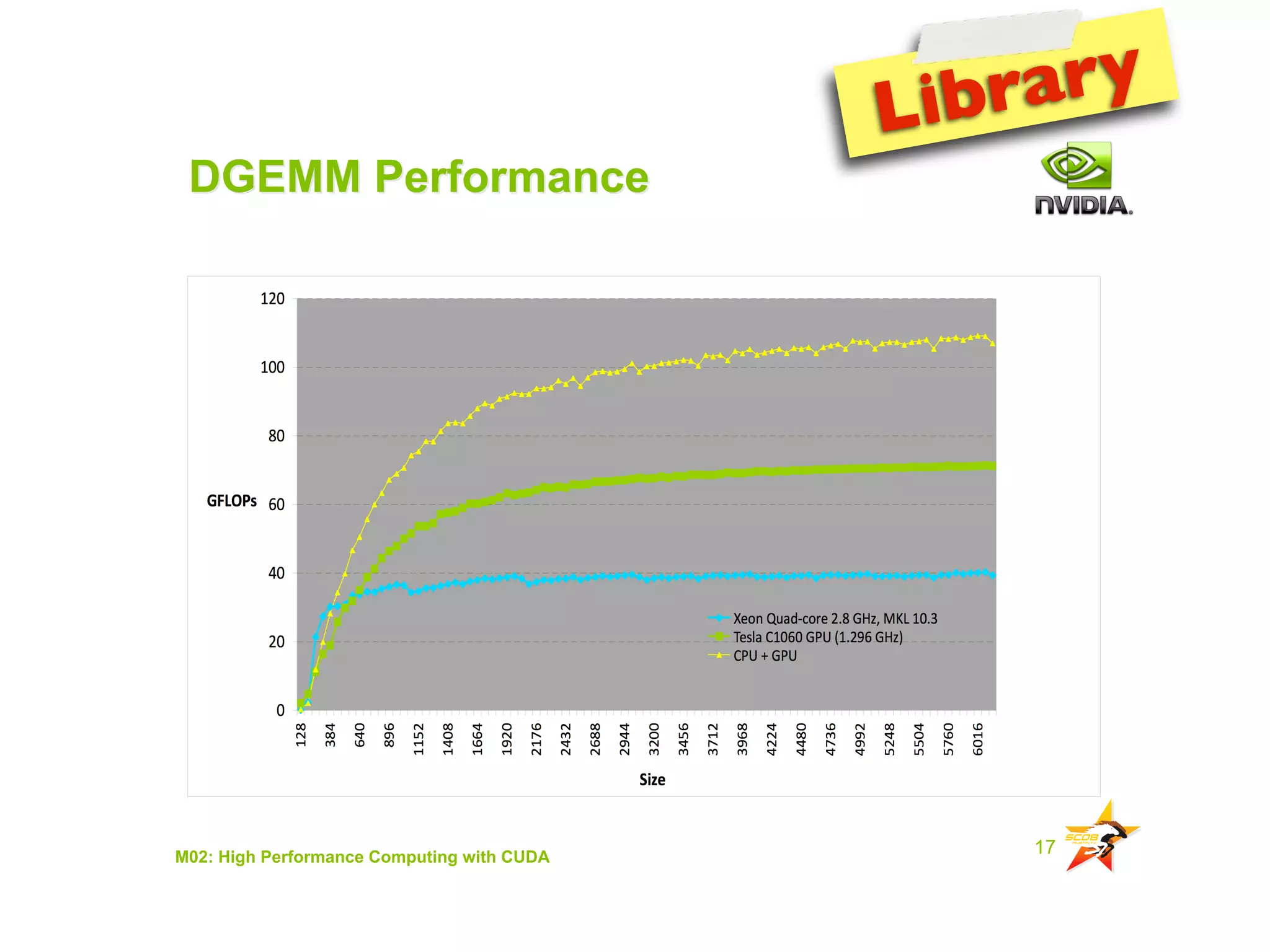


















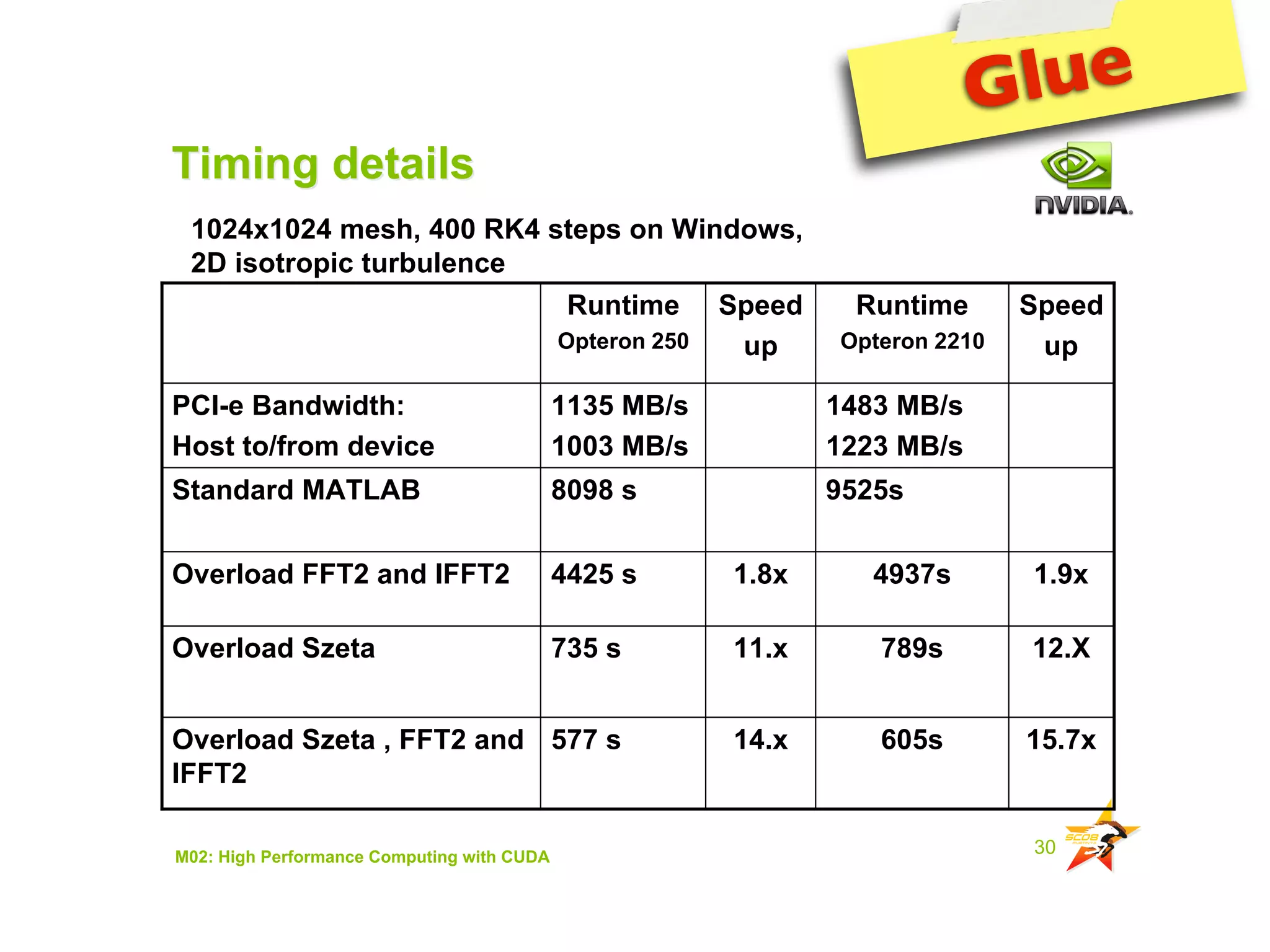
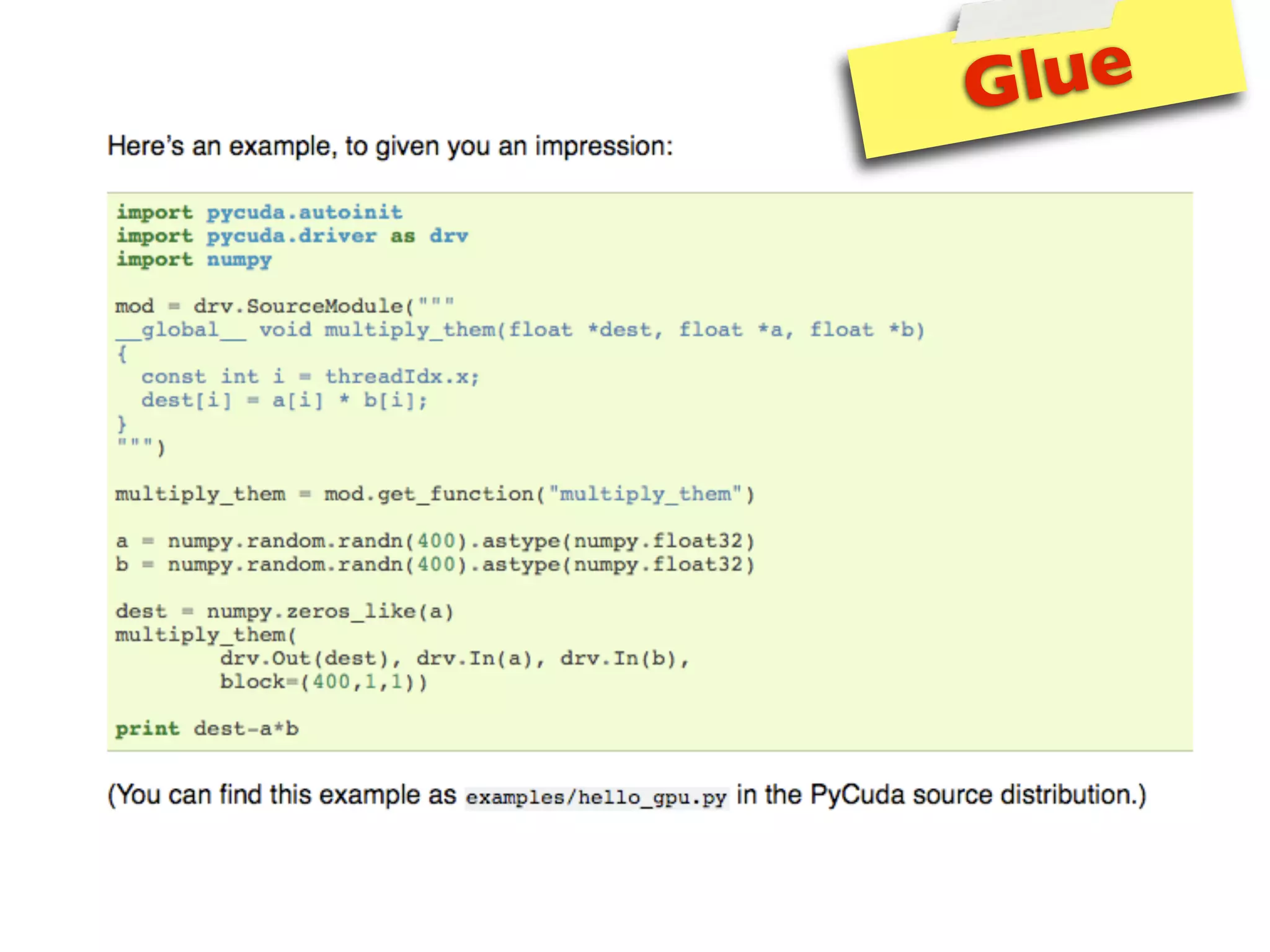

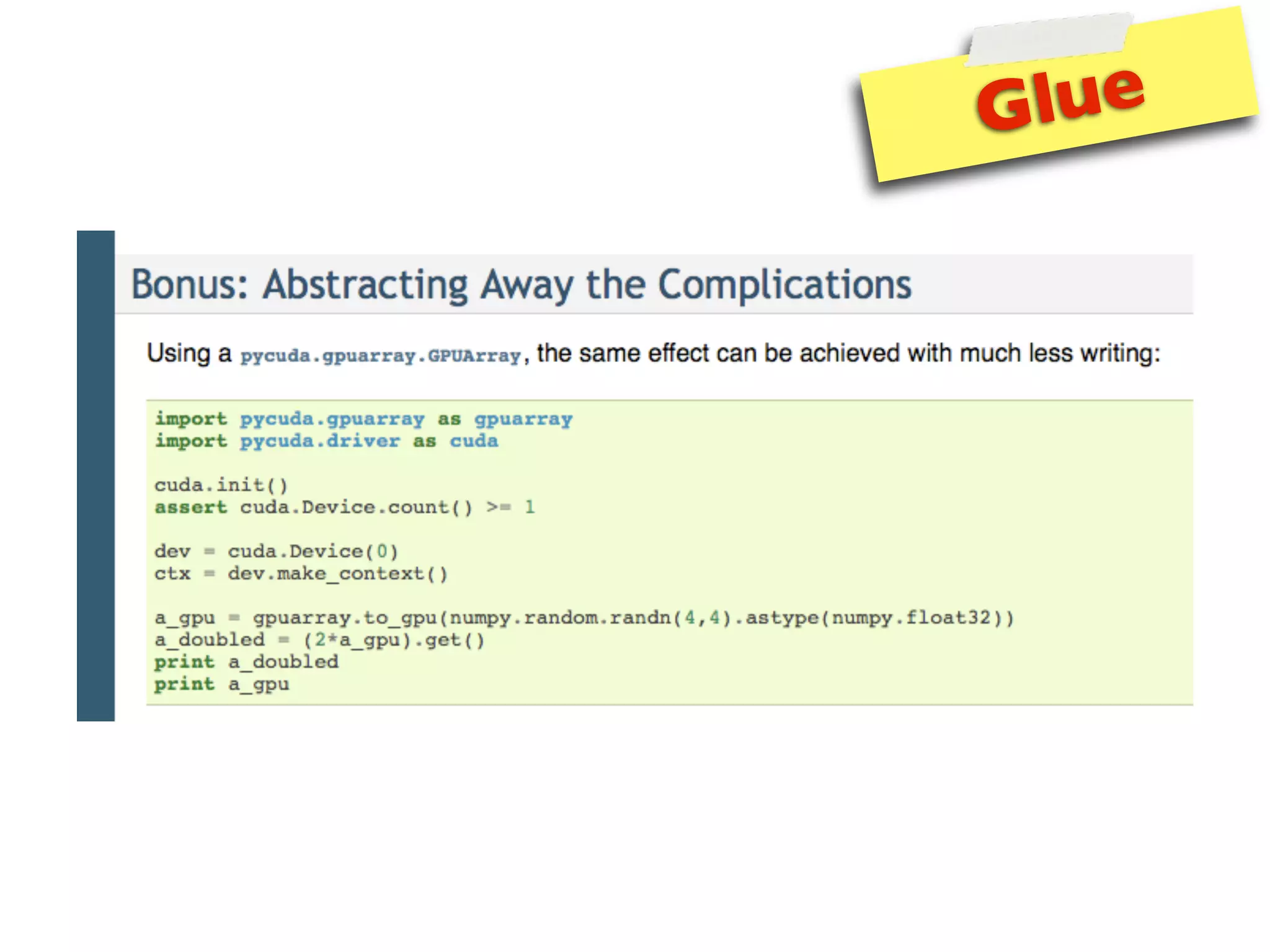
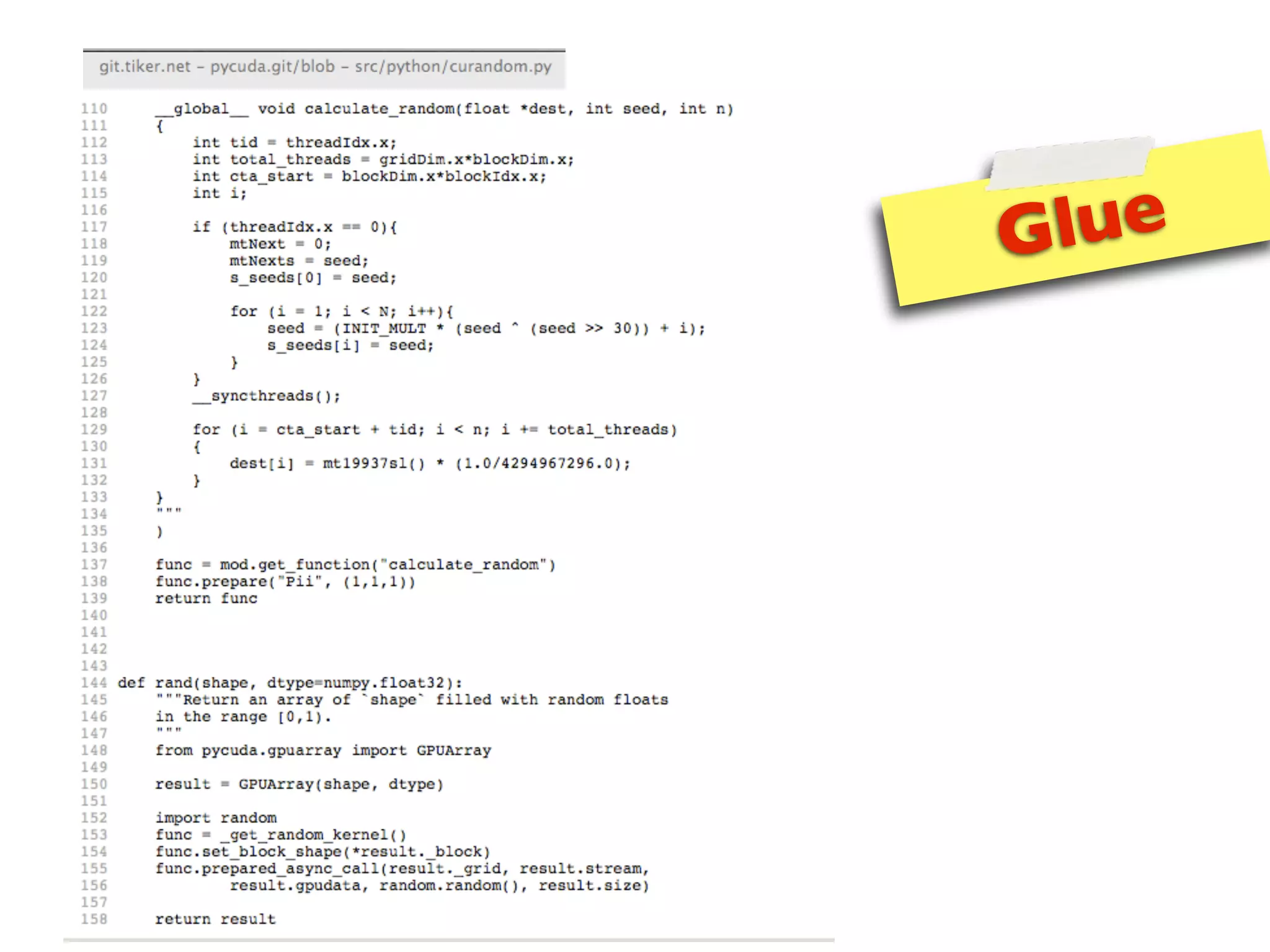



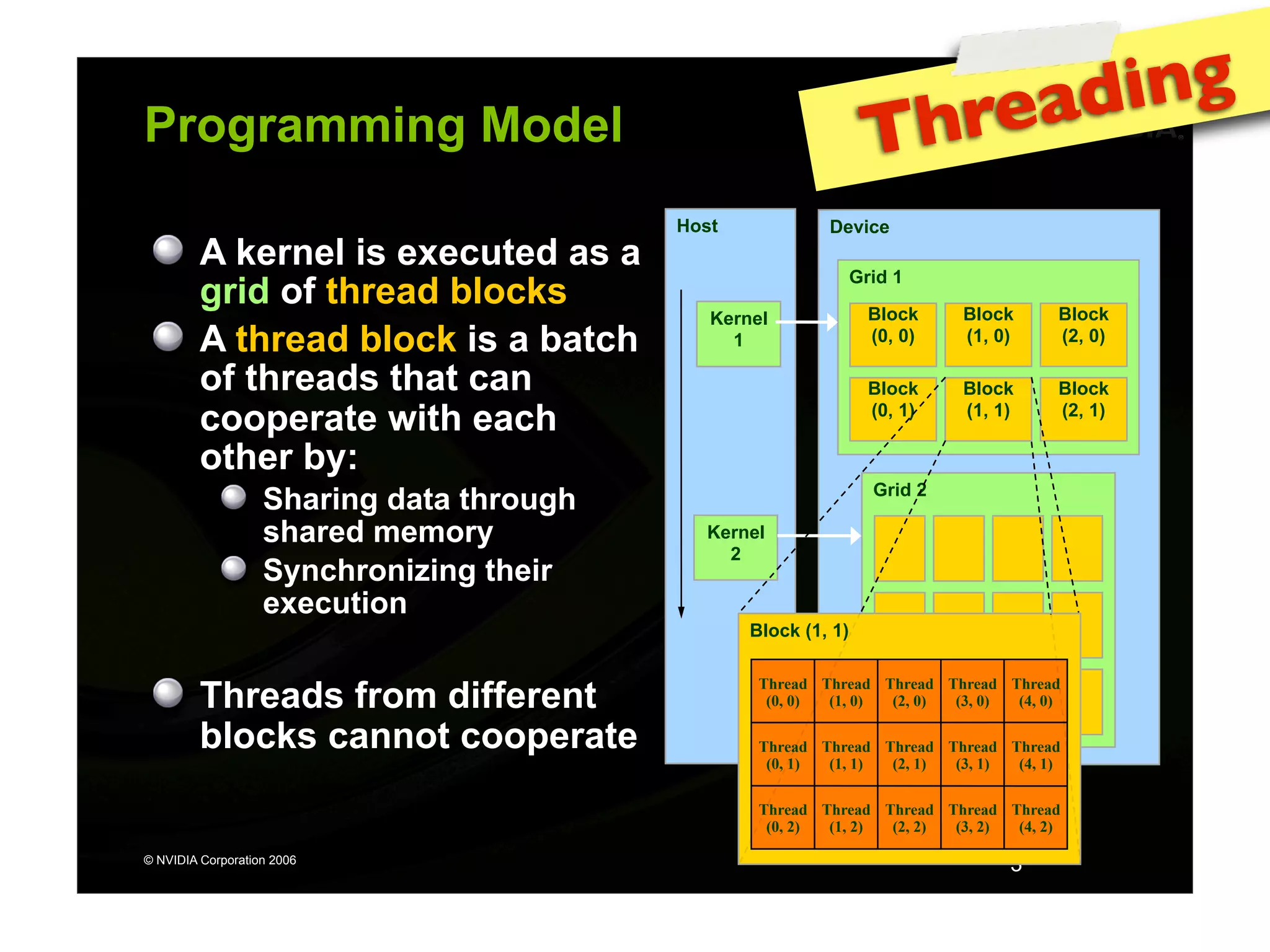
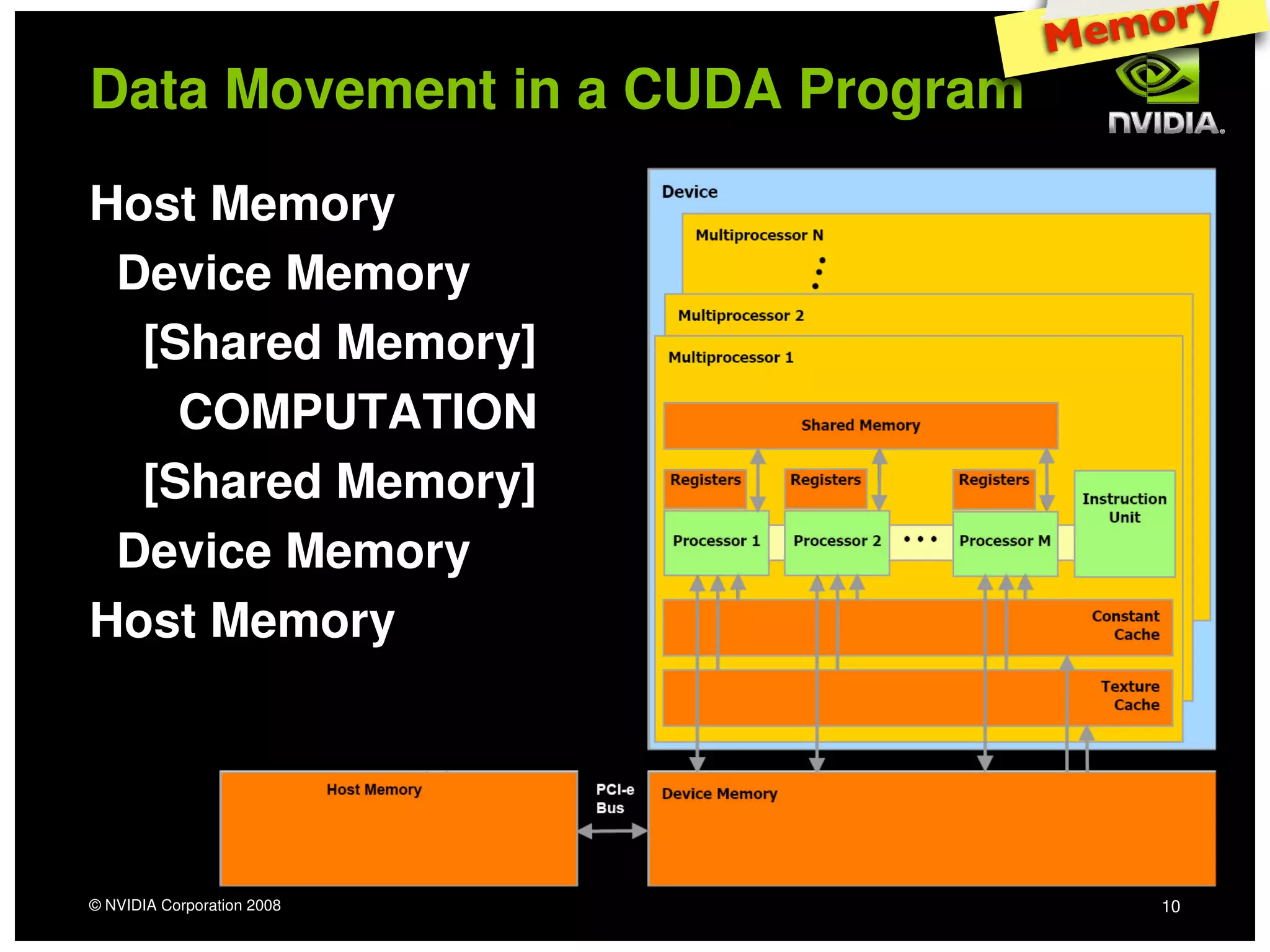









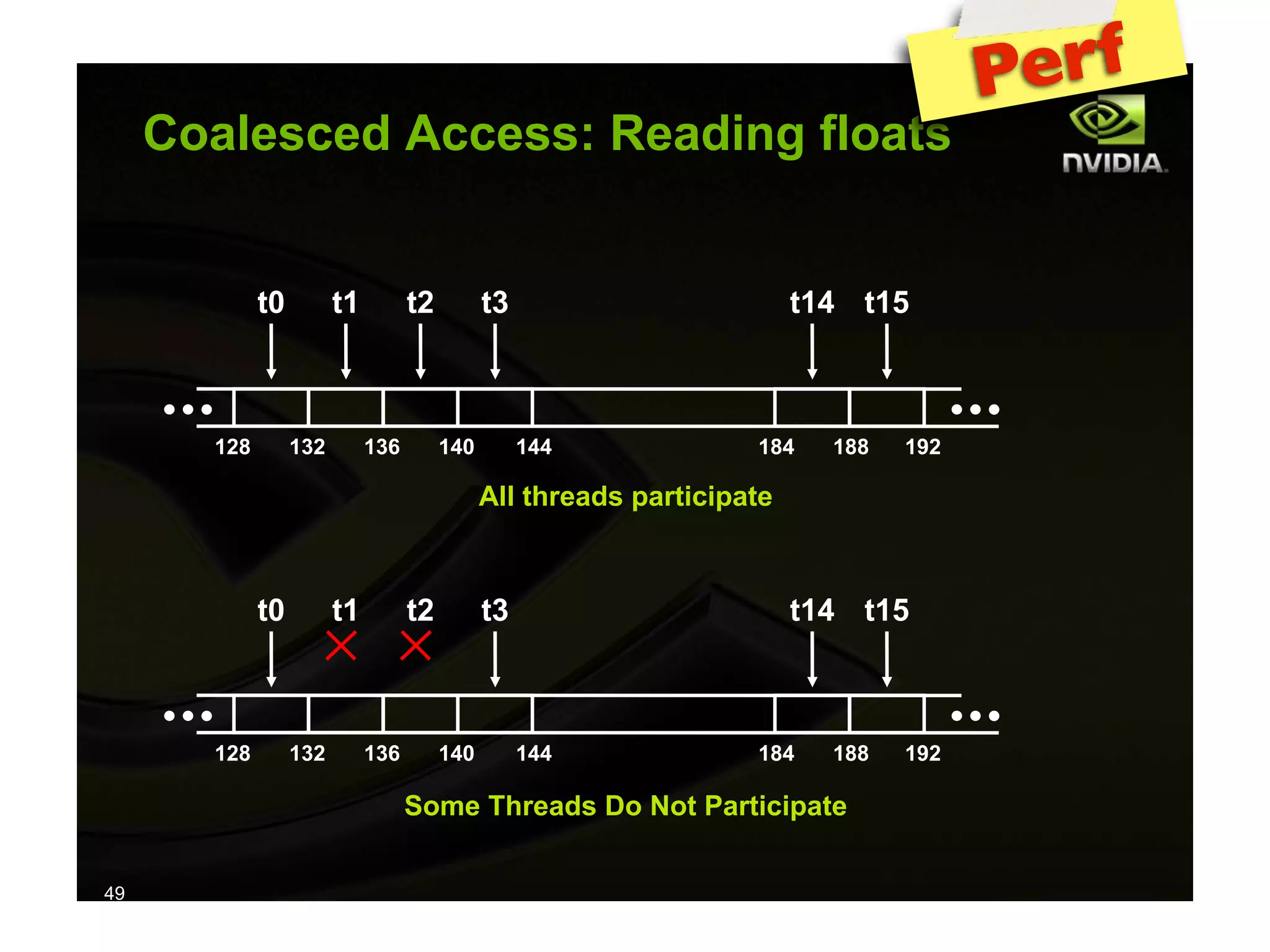
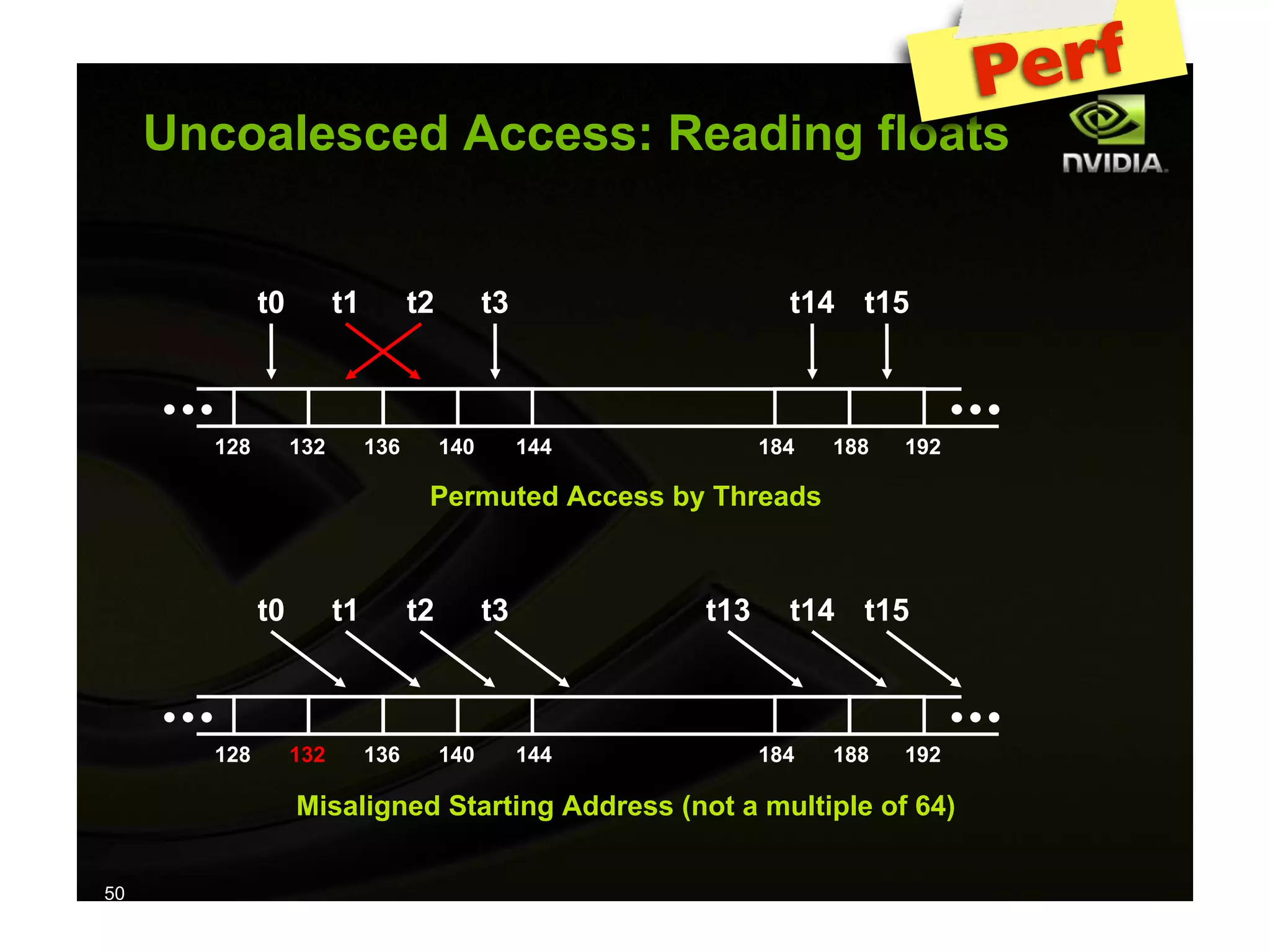




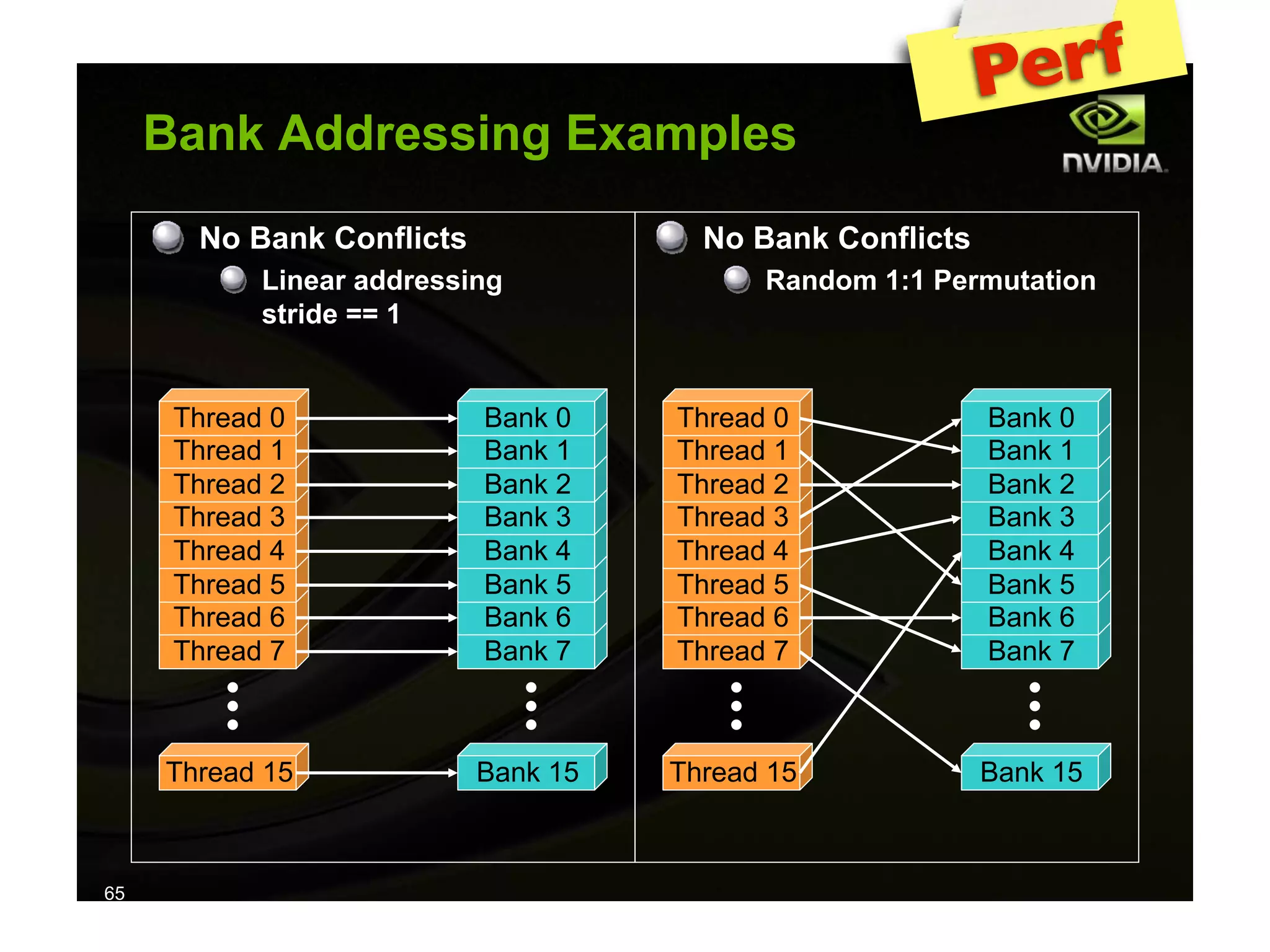
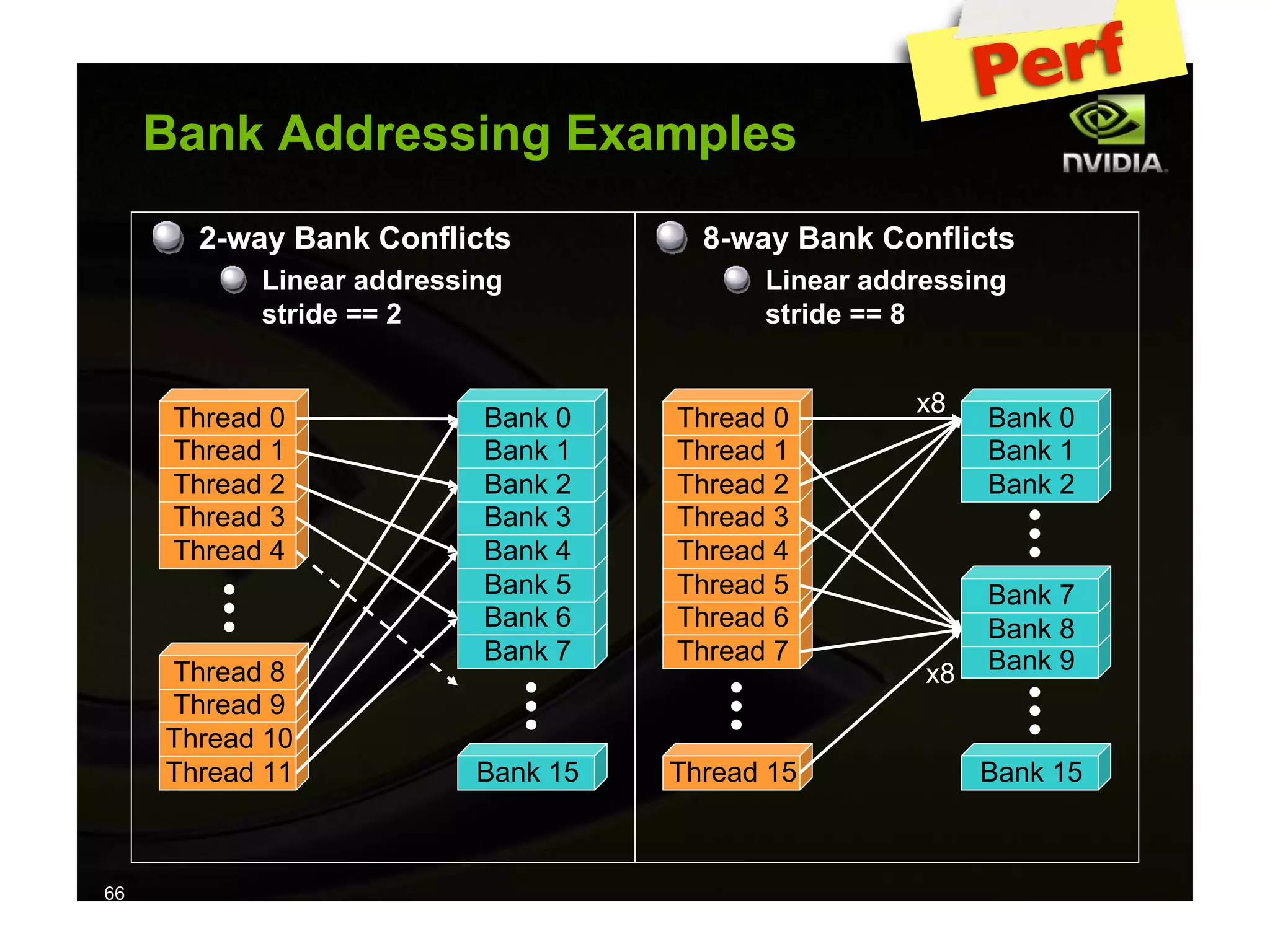






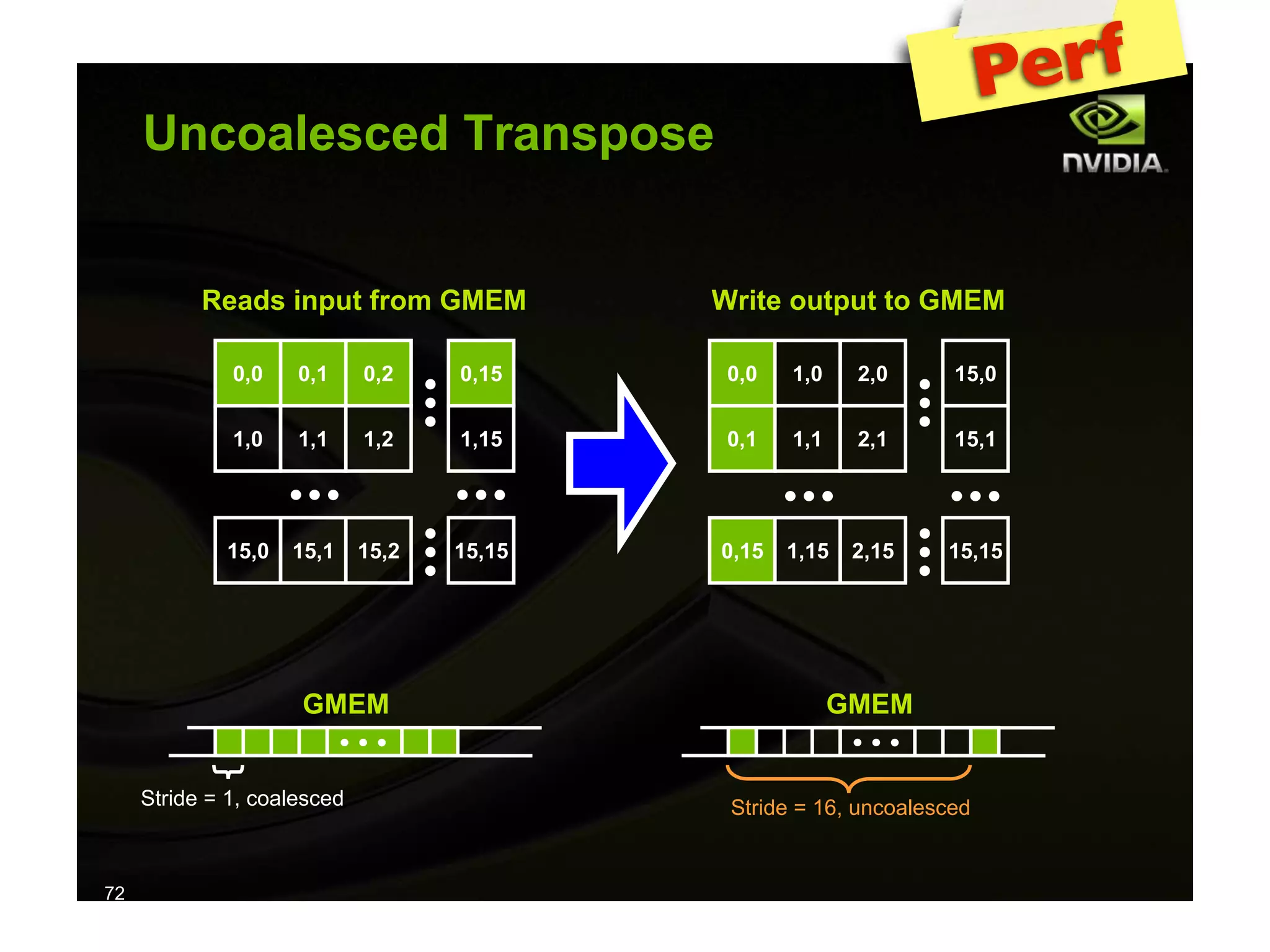

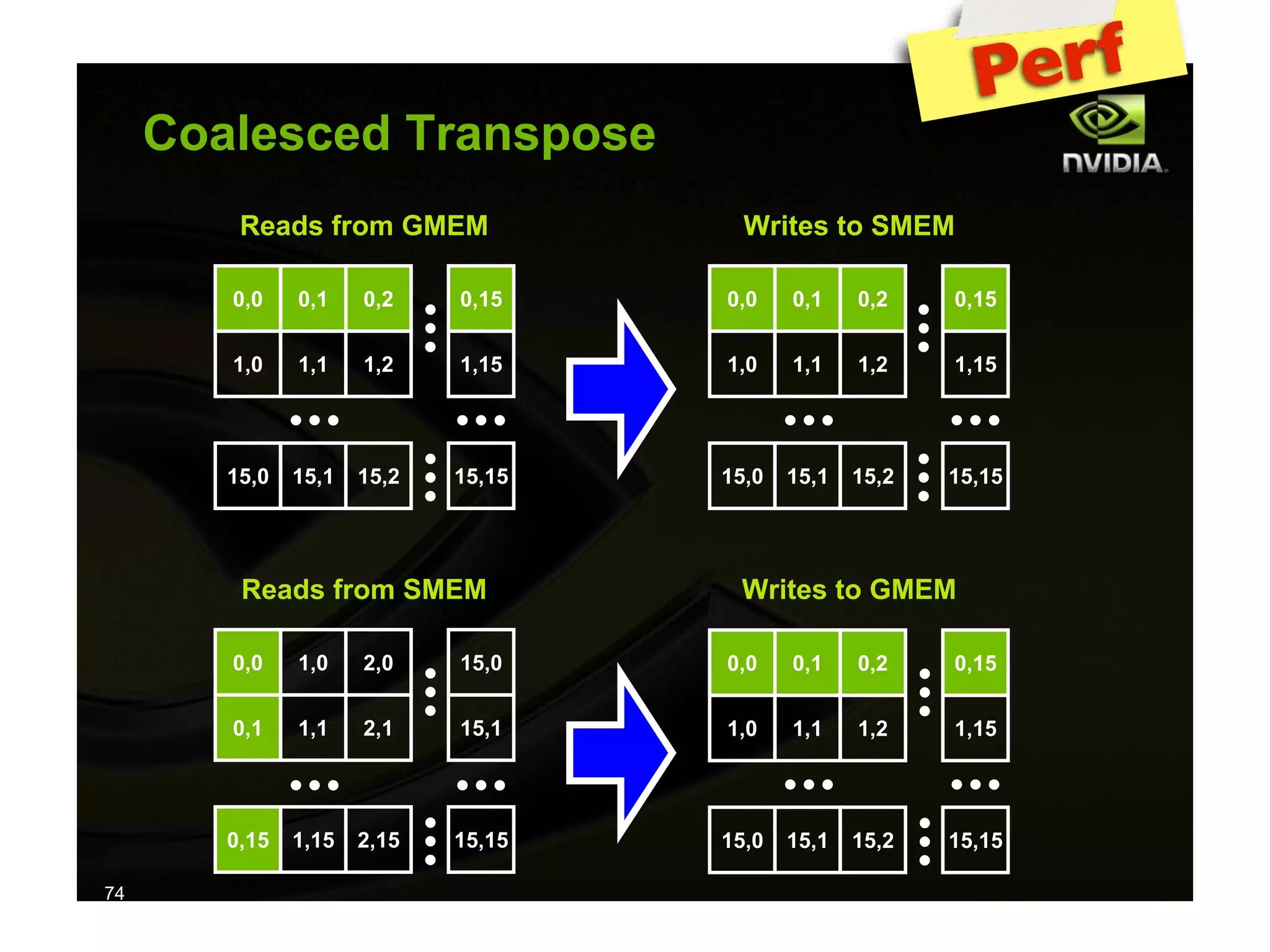


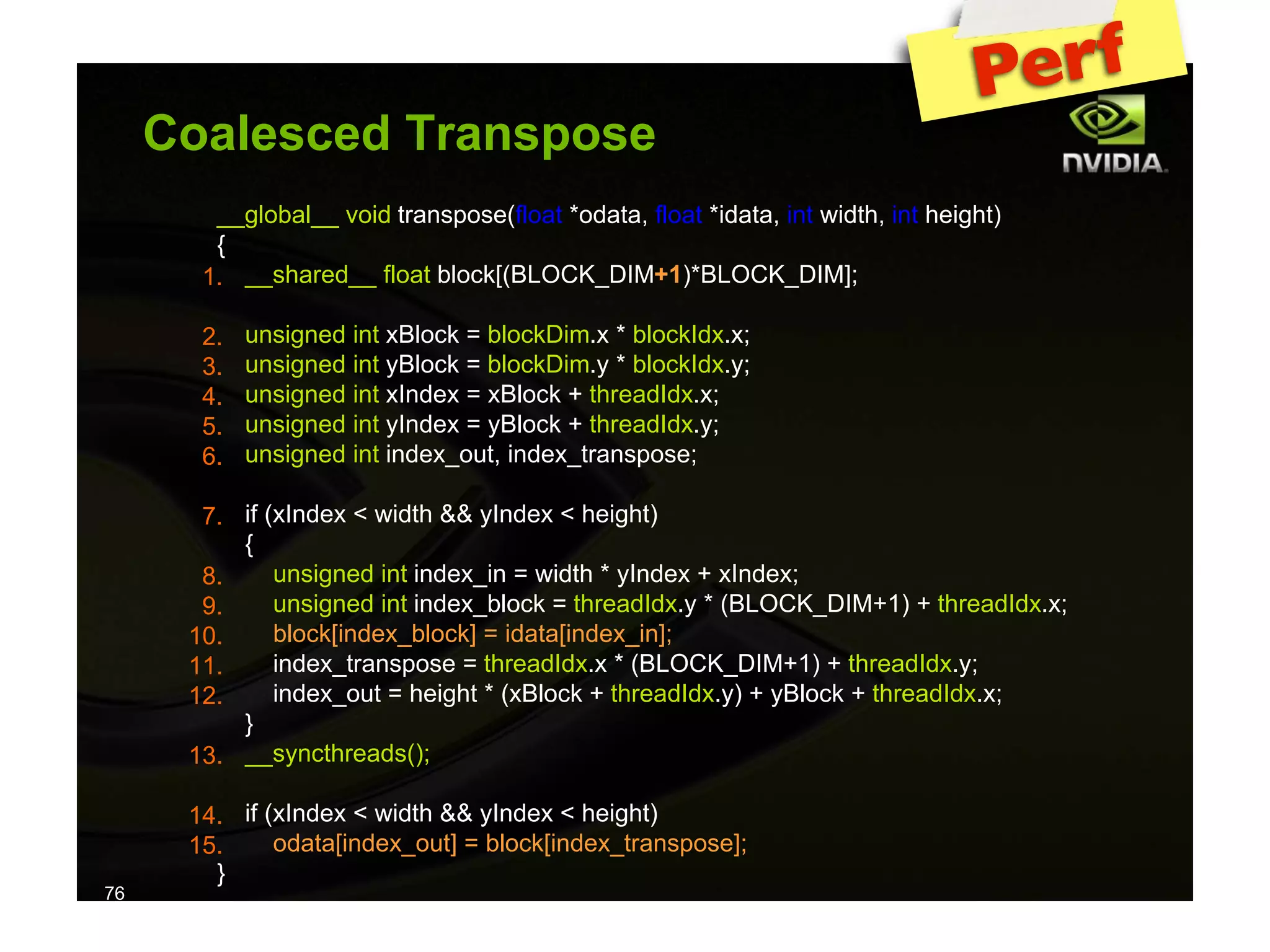







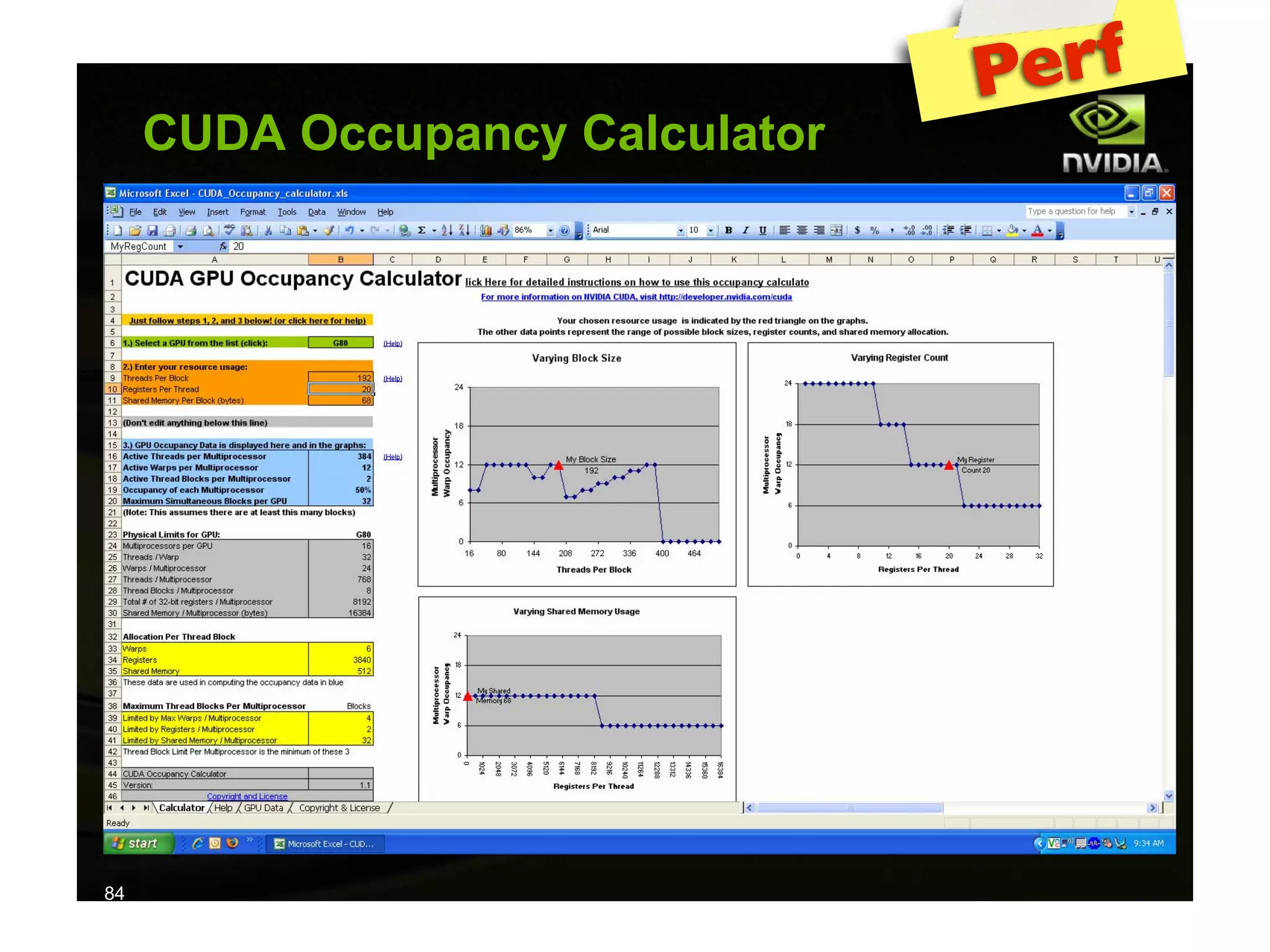





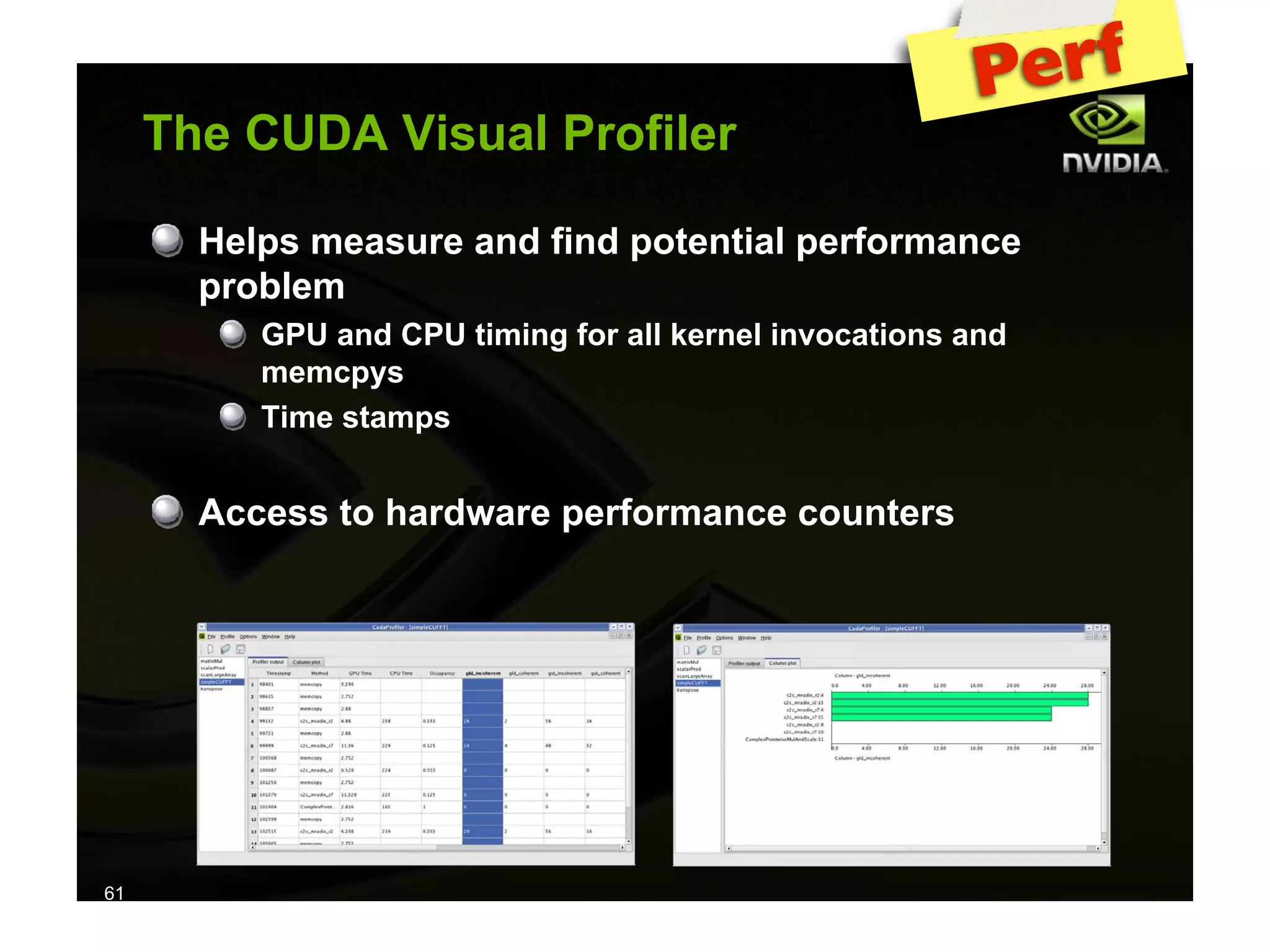
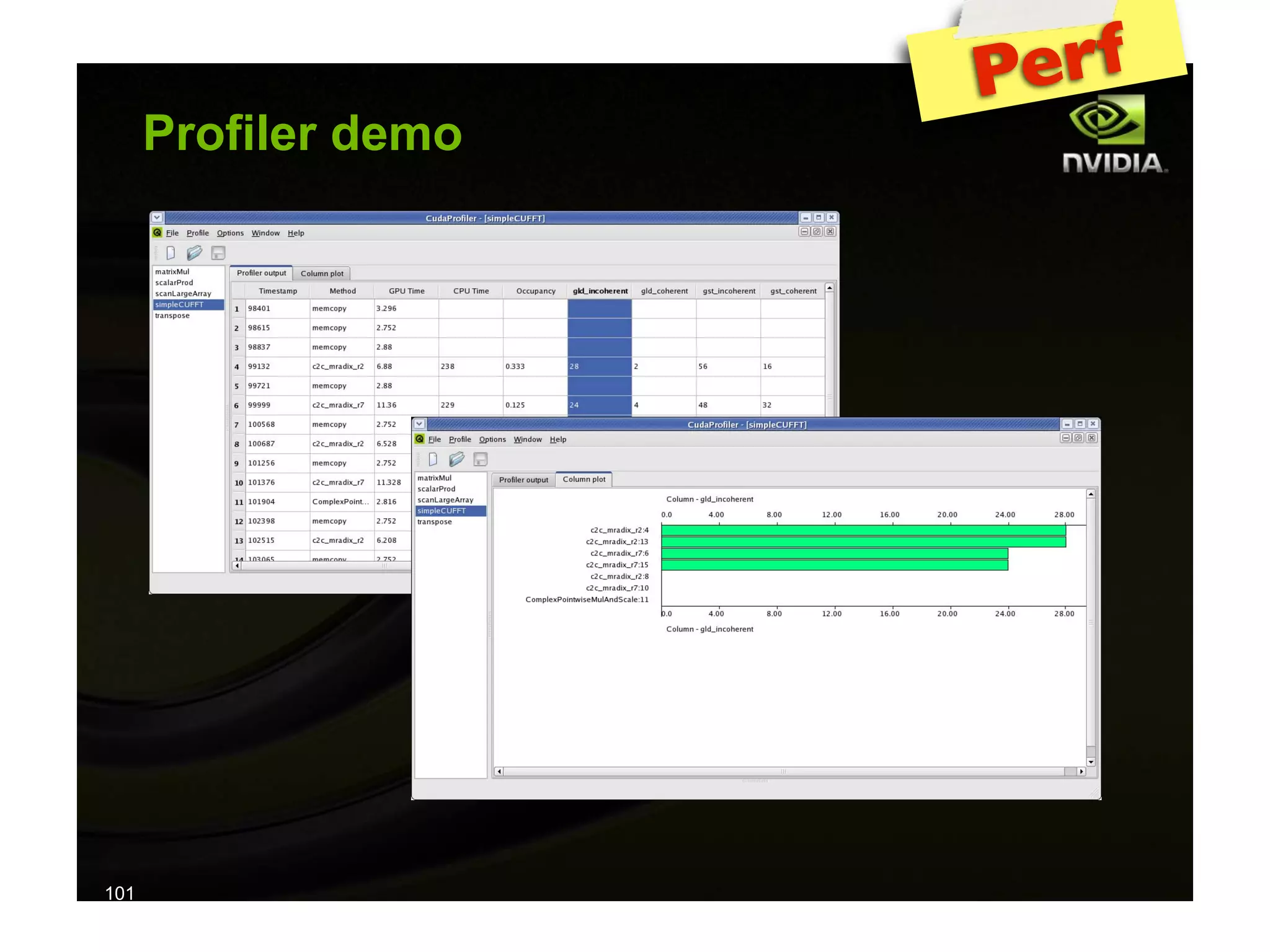





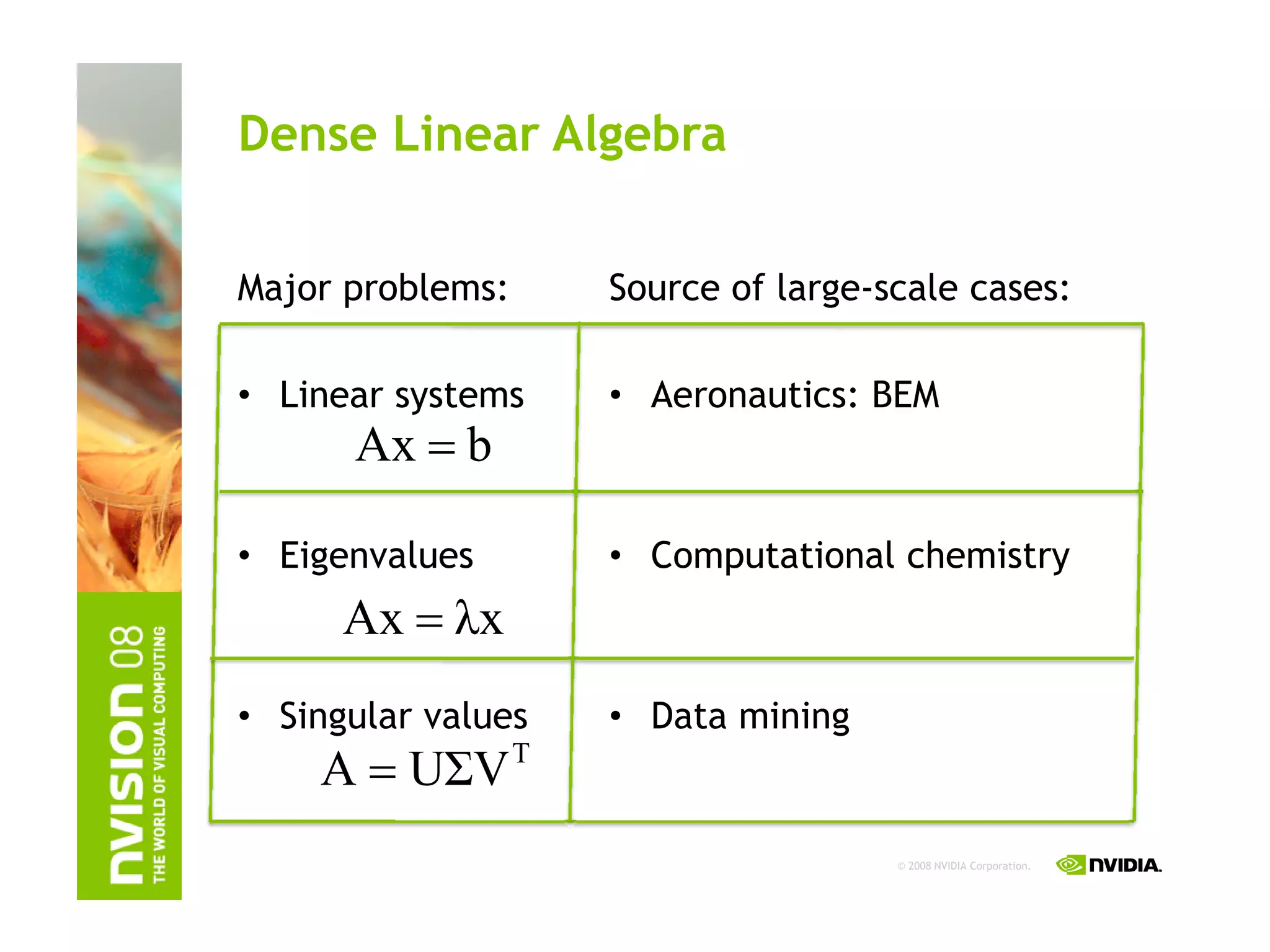


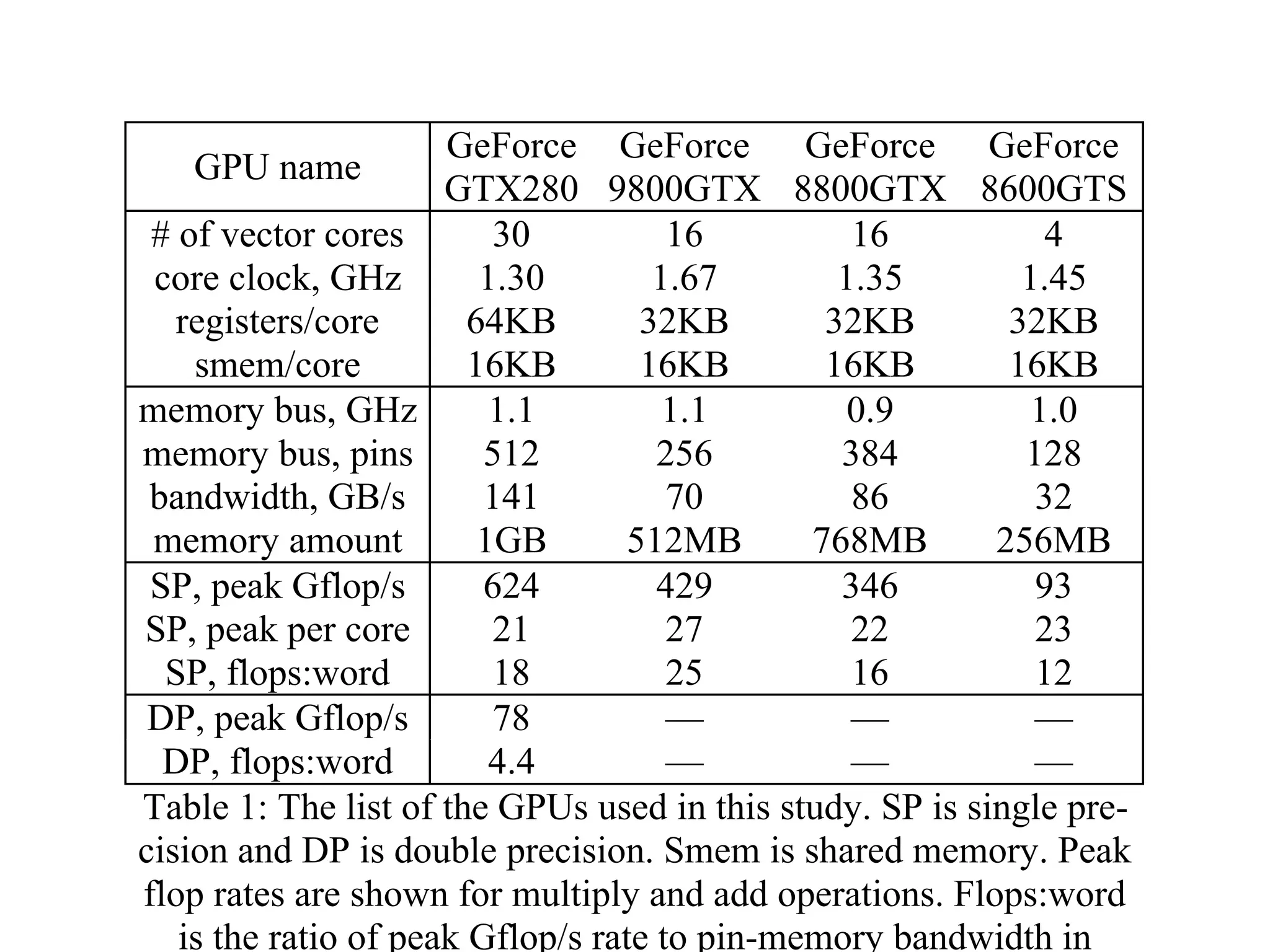
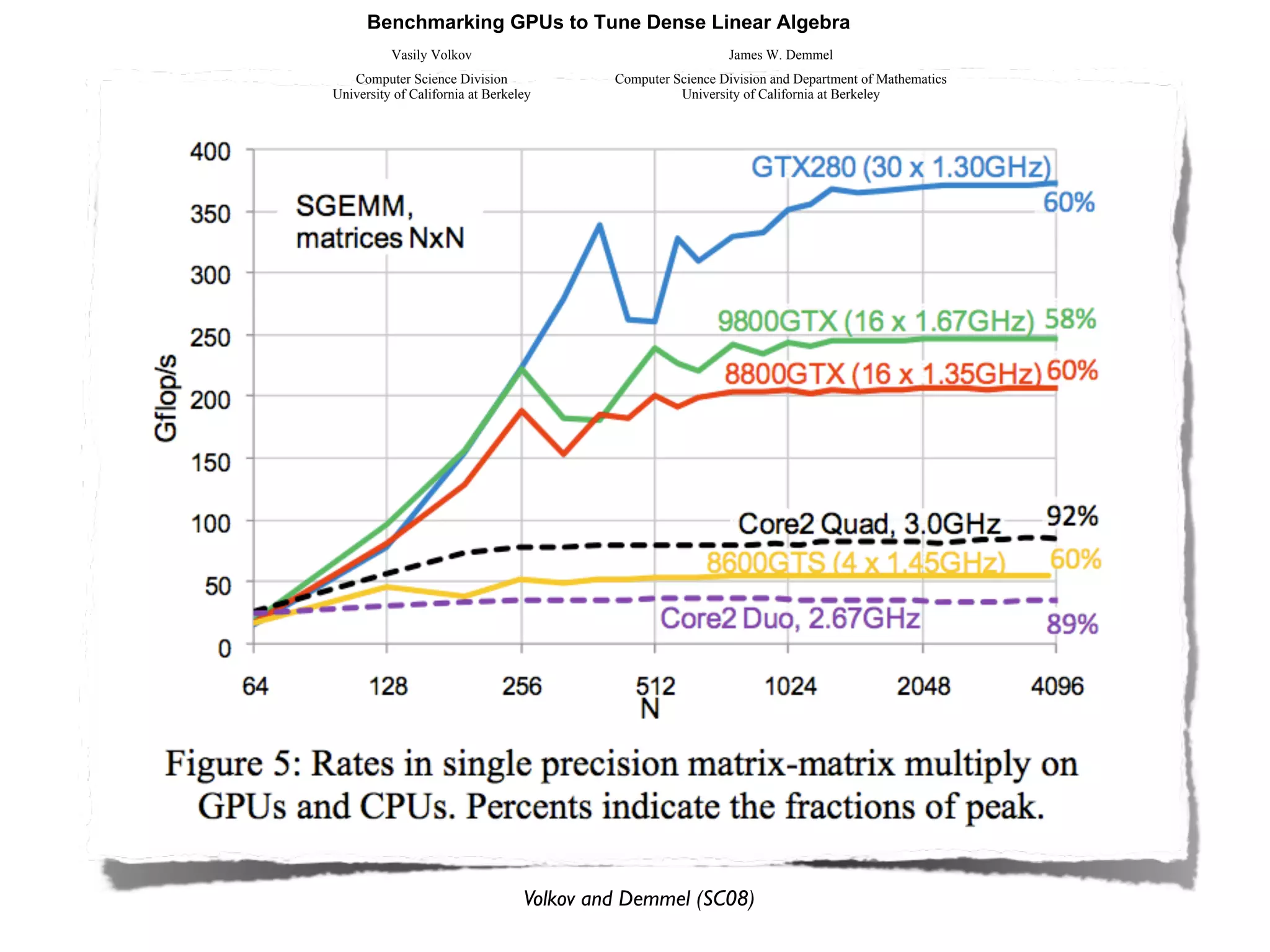
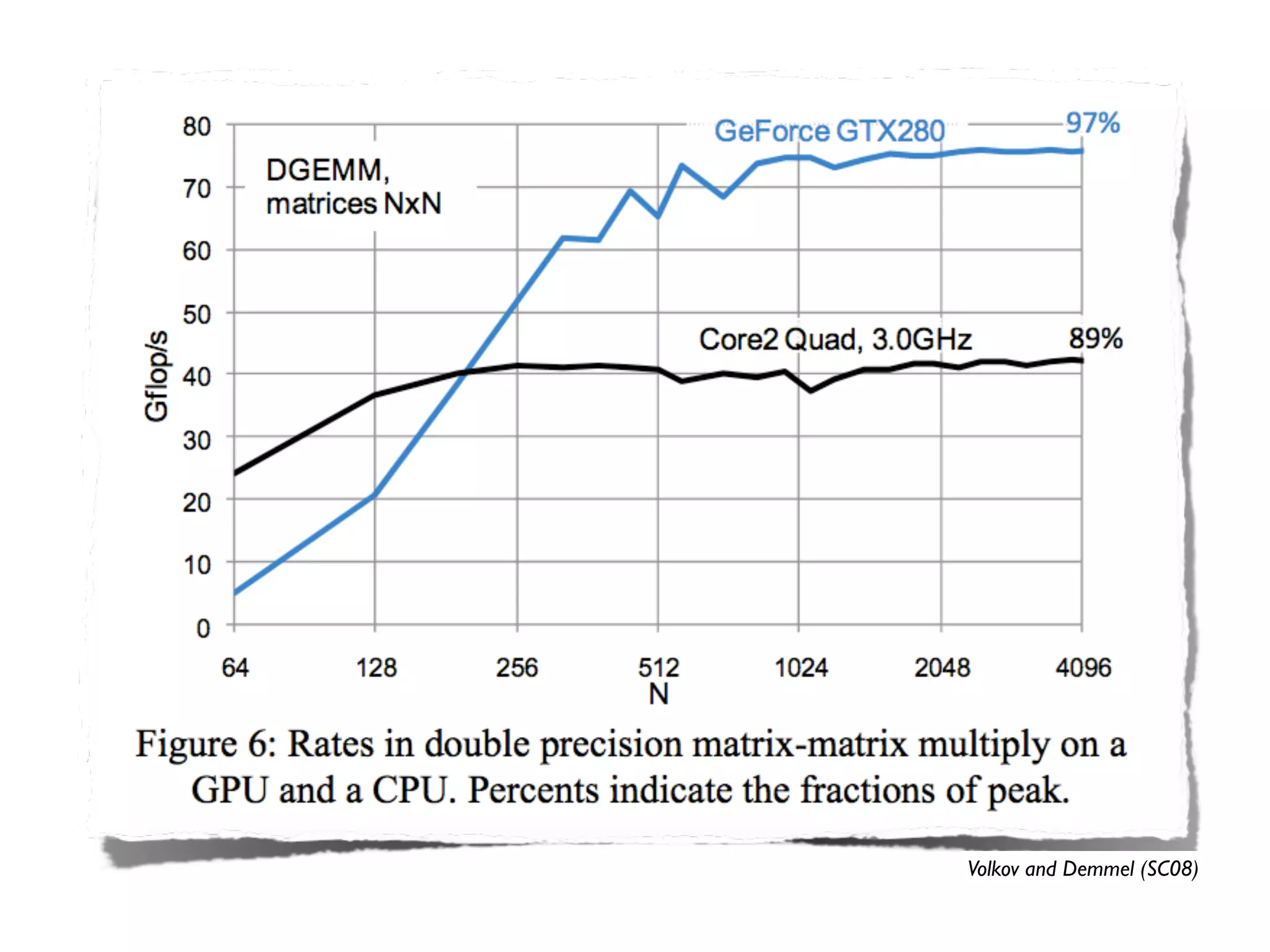
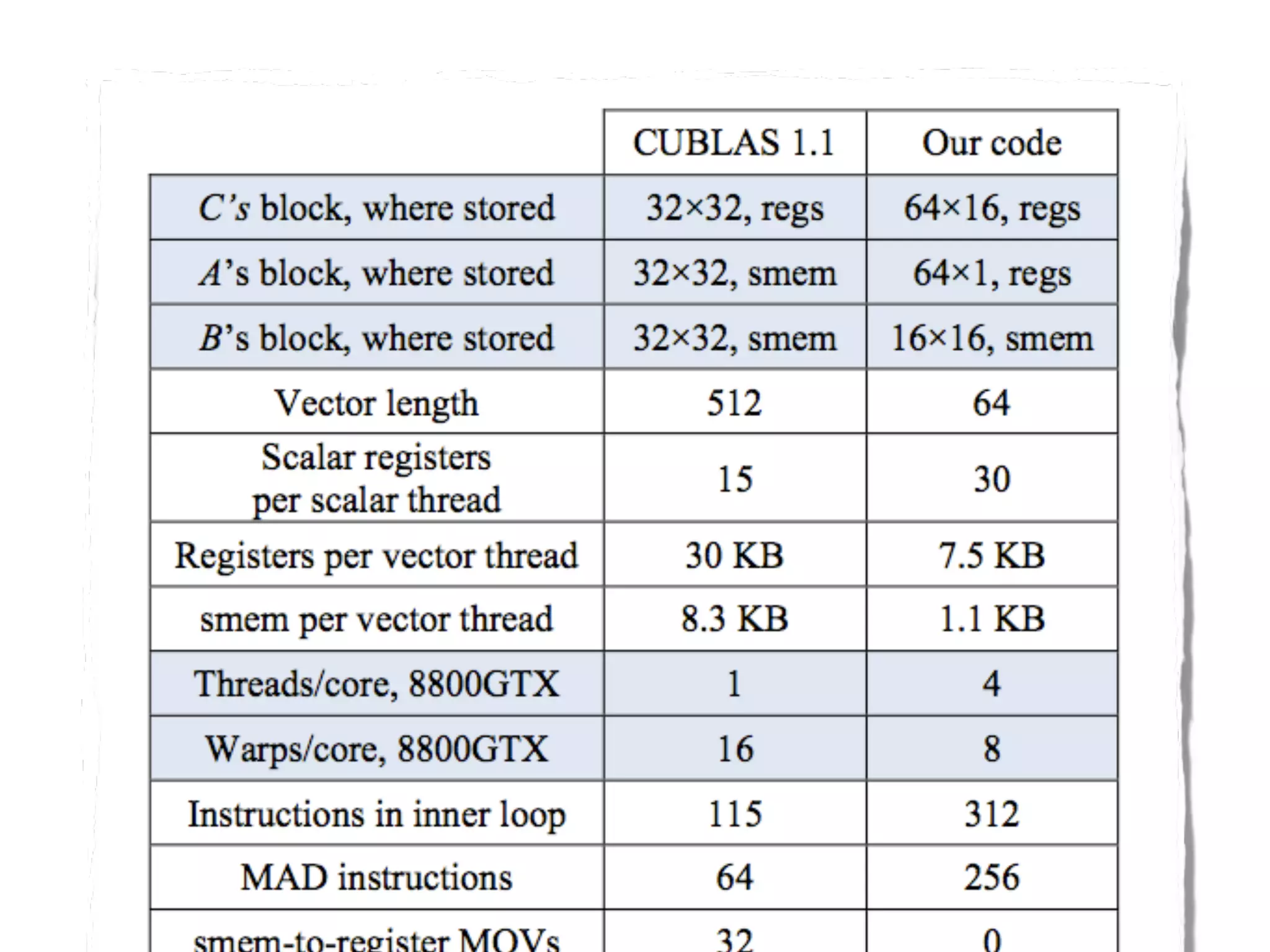
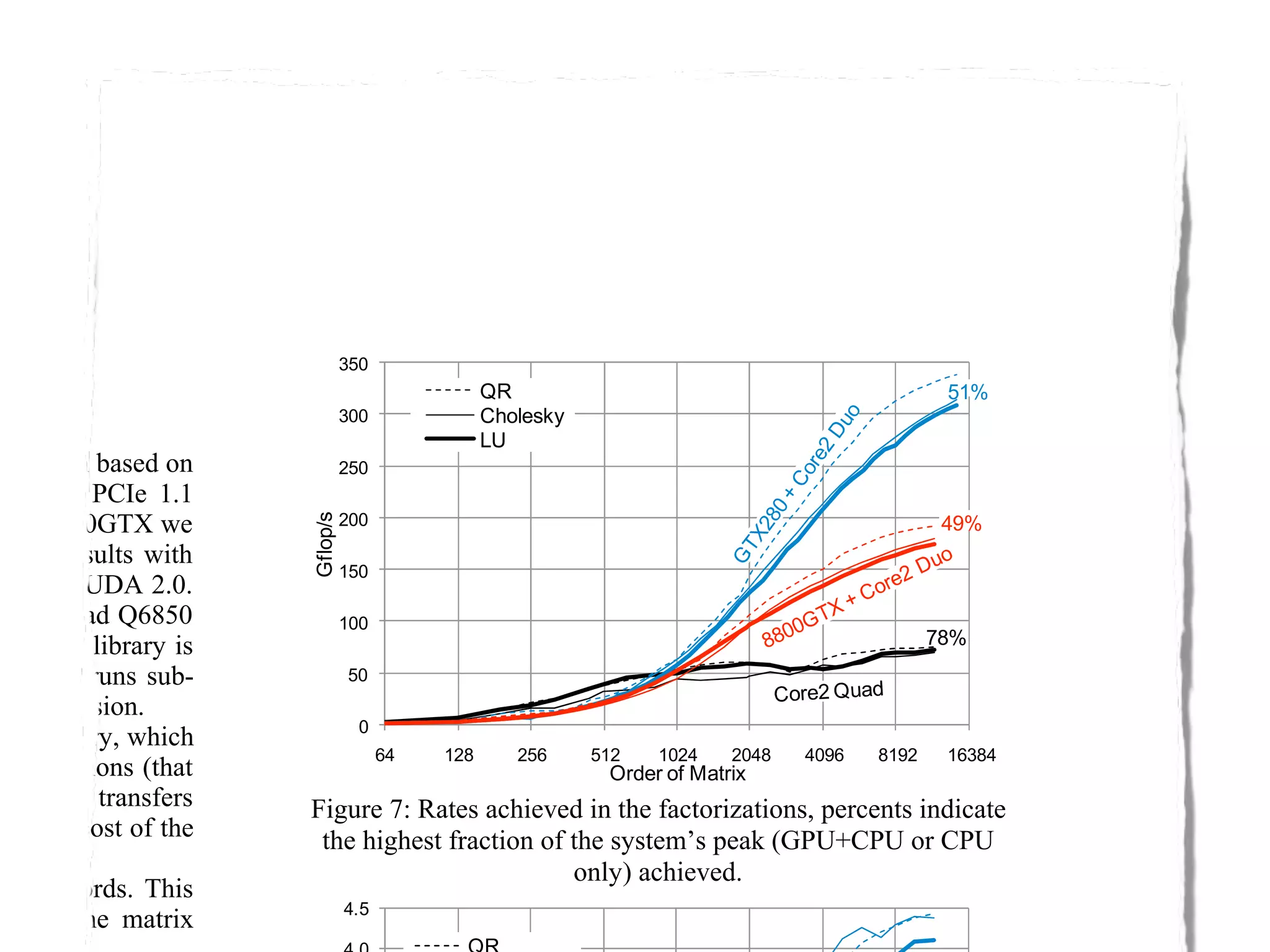





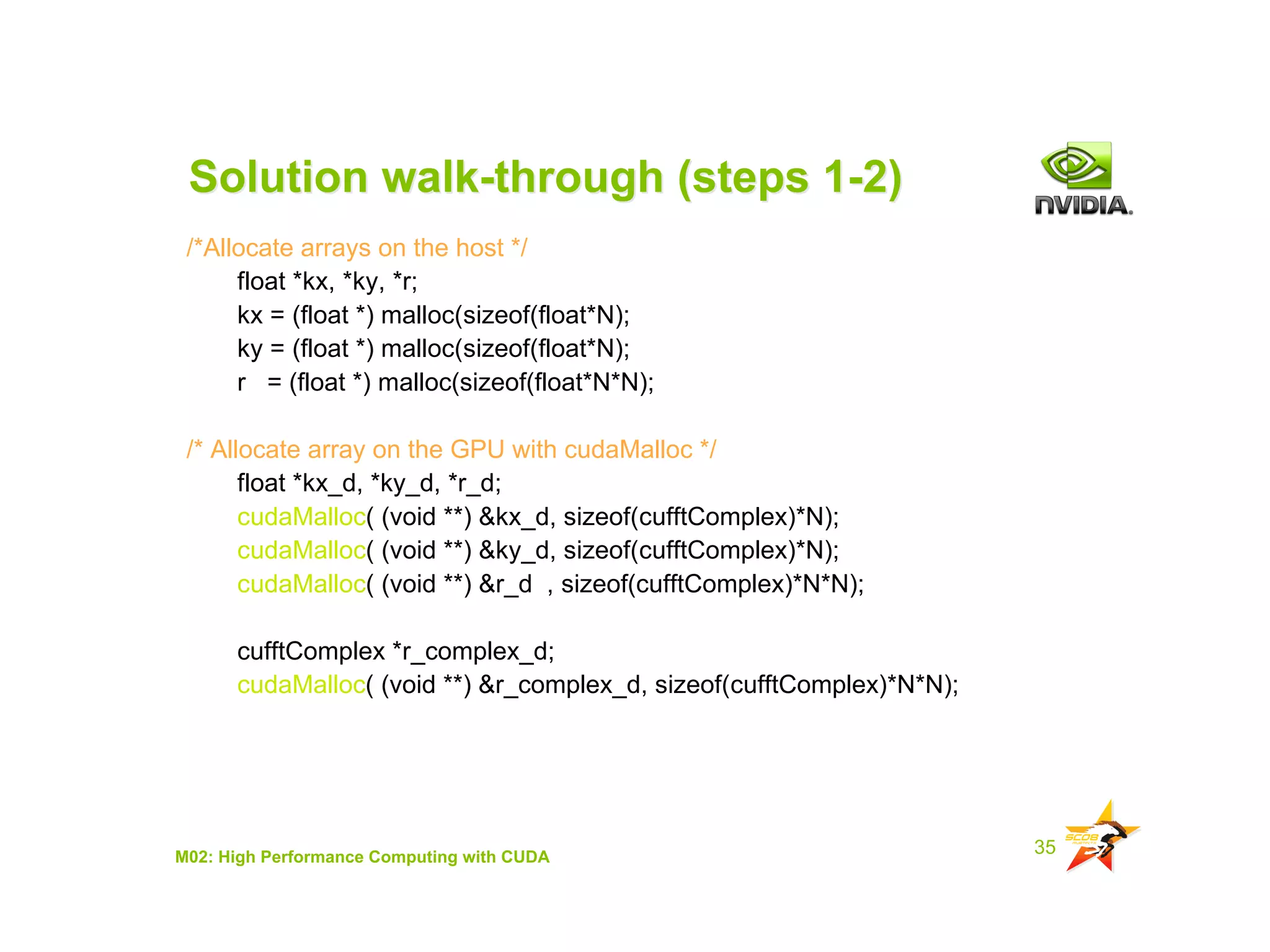

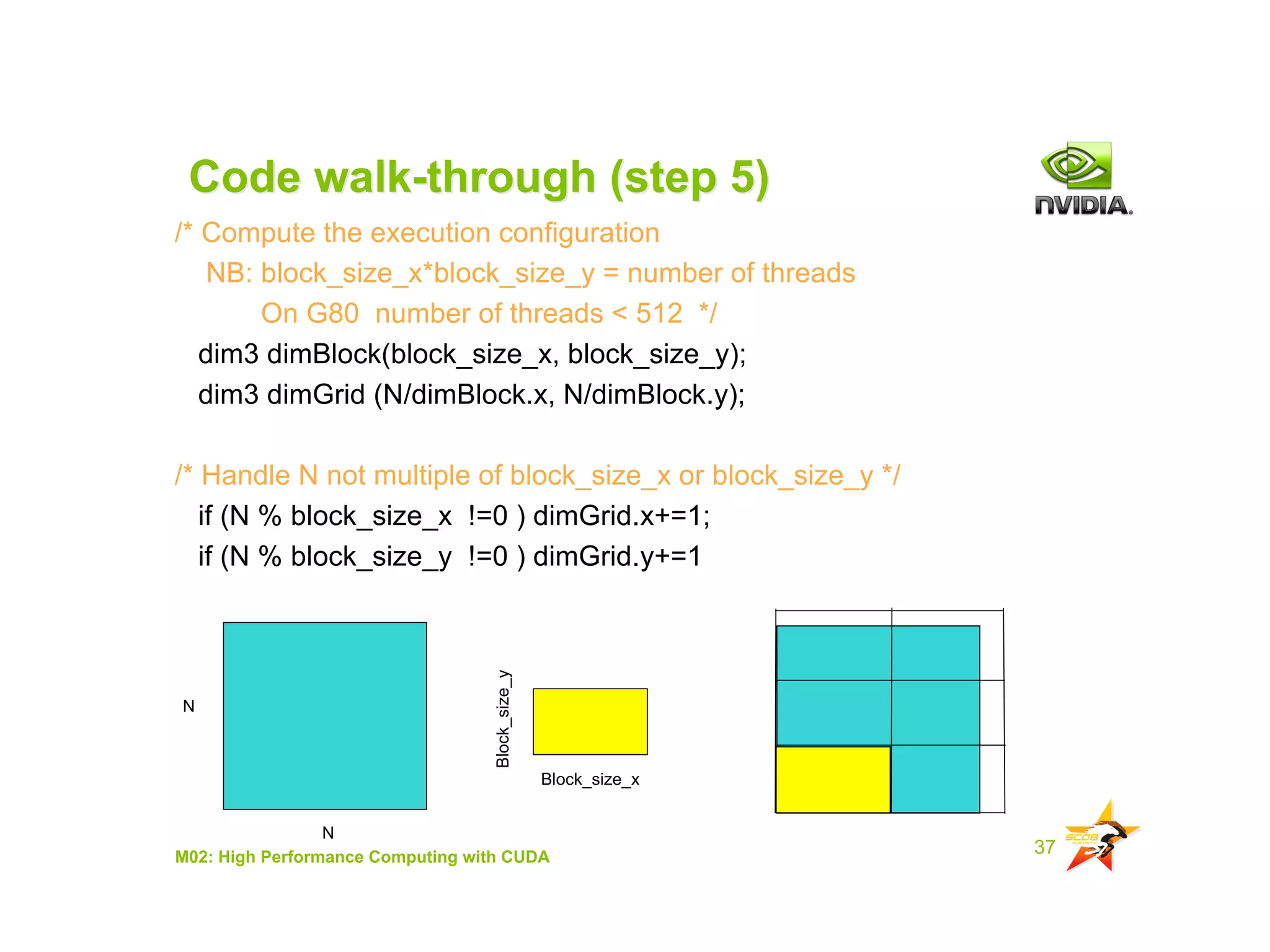


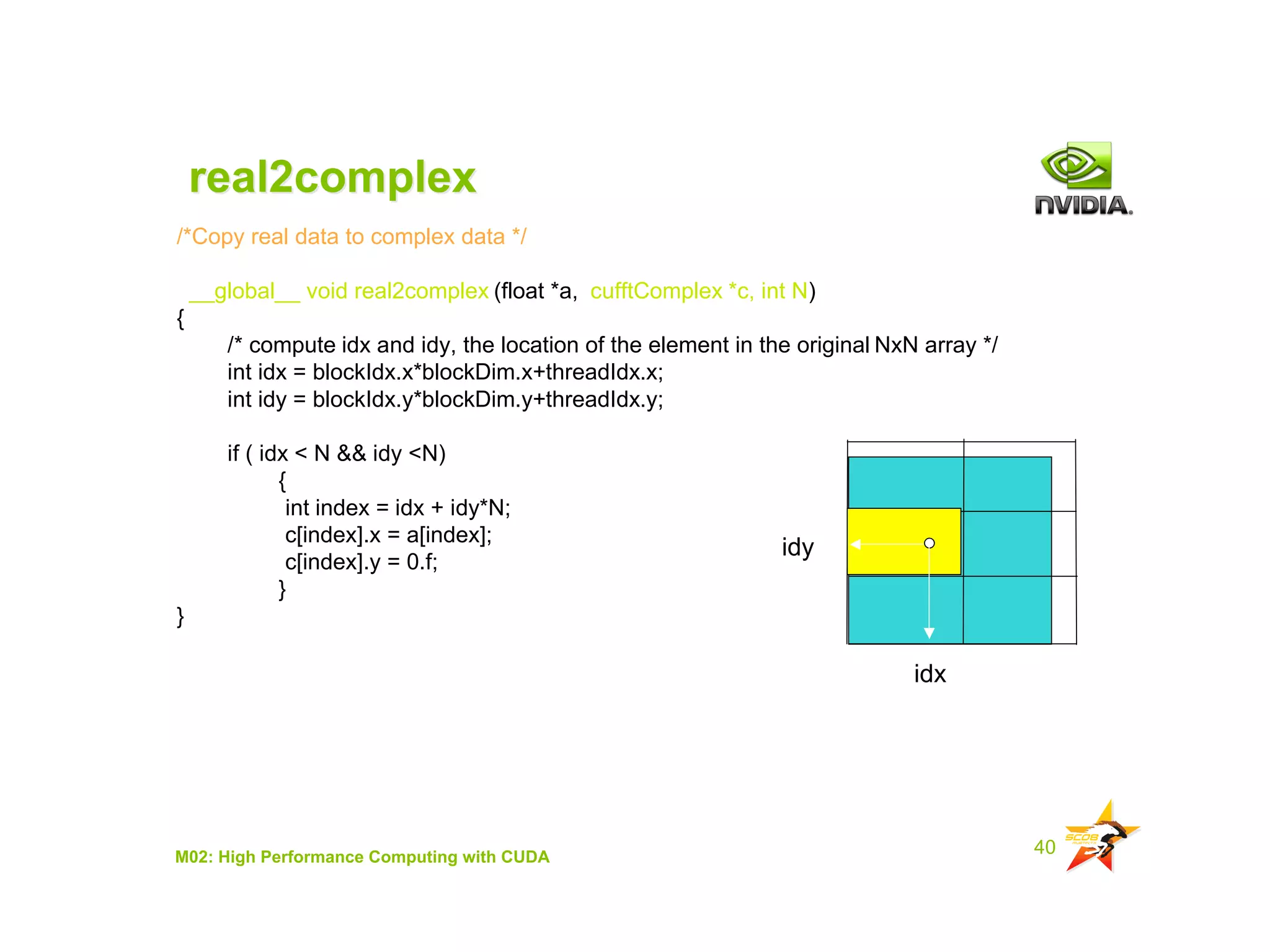





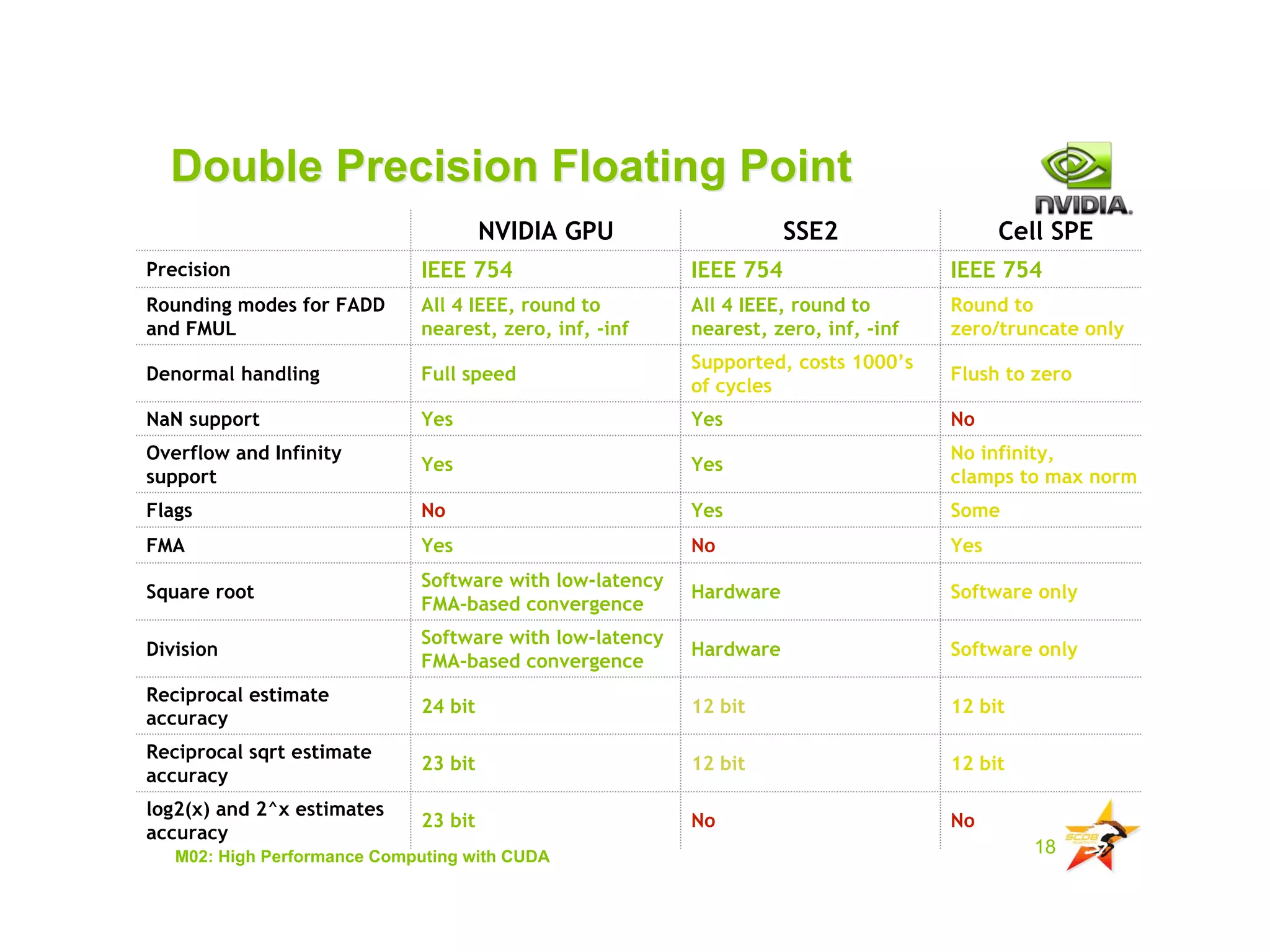
The document provides an overview of programming with CUDA, particularly focusing on texture management and interoperability with OpenGL. It discusses different types of CUDA textures, the steps required to allocate and bind textures, and the integration of CUDA with OpenGL for dynamic texture generation and frame post-processing. Additionally, it covers the use of CUDA libraries like cuBLAS for efficient linear algebra computations on GPUs.

















































![[Harvard CS264] 16 - Managing Dynamic Parallelism on GPUs: A Case Study of Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/managingdynamicparallelism-110430142356-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 15a - The Onset of Parallelism, Changes in Computer Architect...](https://cdn.slidesharecdn.com/ss_thumbnails/drich110413cs264-110428210736-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 15a - Jacket: Visual Computing (James Malcolm, Accelereyes)](https://cdn.slidesharecdn.com/ss_thumbnails/jamesmalcomvisualcomputingcs264-110428210006-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 14 - Dynamic Compilation for Massively Parallel Processors (G...](https://cdn.slidesharecdn.com/ss_thumbnails/gregdiamoscs264lecture-110417212416-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 13 - The R-Stream High-Level Program Transformation Tool / Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/reservoirlabsharvard-presentation-110412184012-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 12 - Irregular Parallelism on the GPU: Algorithms and Data St...](https://cdn.slidesharecdn.com/ss_thumbnails/owens-harvard-110407-110407230512-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11b - Analysis-Driven Performance Optimization with CUDA (Cli...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407230024-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11a - Programming the Memory Hierarchy with Sequoia (Mike Bau...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407225811-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 10b - cl.oquence: High-Level Language Abstractions for Low-Le...](https://cdn.slidesharecdn.com/ss_thumbnails/cl-oquence-cs264-110403182645-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 10a - Easy, Effective, Efficient: GPU Programming in Python w...](https://cdn.slidesharecdn.com/ss_thumbnails/andreas-cs264-110331202547-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 09 - Machine Learning on Big Data: Lessons Learned from Googl...](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 08a - Cloud Computing, Amazon EC2, MIT StarCluster (Justin Ri...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264-intro-to-cloud-computing-110322172806-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 06 - CUDA Ninja Tricks: GPU Scripting, Meta-programming & Aut...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201106-cudaninjasharetmp-110301171948-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 05 - Advanced-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 04 - Intermediate-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201104-cudaintermediatesharetmpopt-110215180915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















