Downloaded 93 times















![19
TENSOR CORE
Mixed Precision Matrix Math - 4x4 matrices
New CUDA TensorOp instructions & data formats
4x4x4 matrix processing array
D[FP32] = A[FP16] * B[FP16] + C[FP32]
Using Tensor cores via
• Volta optimized frameworks and libraries
(cuDNN, CuBLAS, TensorRT, ..)
• CUDA C++ Warp Level Matrix Operations](https://image.slidesharecdn.com/groethnvidiahwswplatformstue170919-191104222203/85/Hardware-Software-Platforms-for-HPC-AI-and-ML-19-320.jpg)
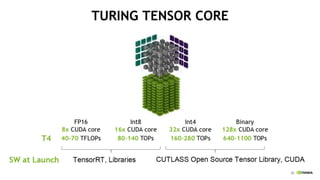

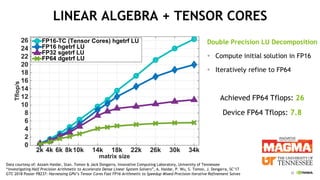





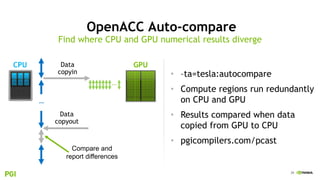




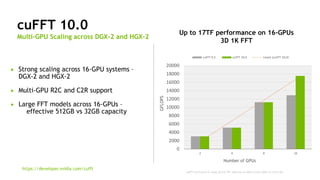
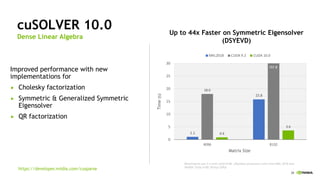




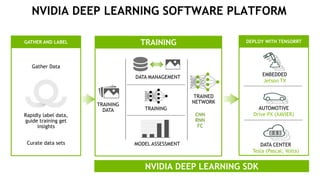
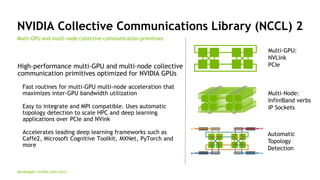
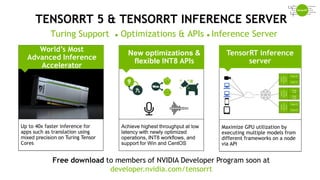

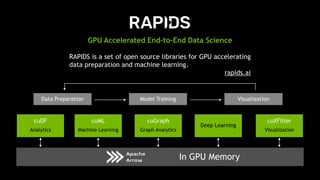

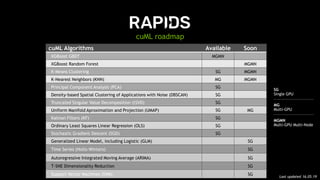

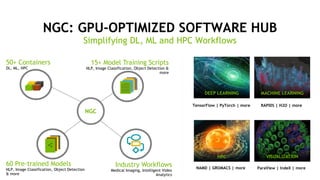



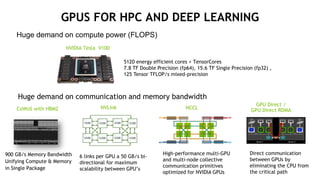
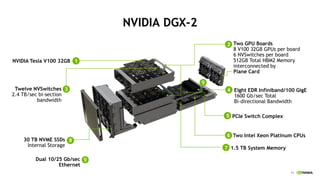
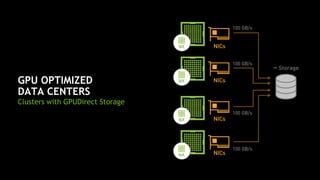
The document provides an overview of NVIDIA's hardware and software solutions for high-performance computing (HPC), artificial intelligence (AI), and machine learning (ML), highlighting the capabilities of Tesla GPUs and various systems. It details the achievements of NVIDIA in powering the world's fastest supercomputers and discusses various NVIDIA products, SDKs, and libraries designed to enhance performance and energy efficiency in computational tasks. Additionally, it mentions innovations like mixed-precision computing, GPU Direct technology, and software ecosystems aimed at optimizing data-intensive workflows.

















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





