The document discusses the principles and practices of scaling machine learning algorithms for big data, drawing lessons from Google's projects. It emphasizes the importance of parallelizing algorithms, distributed learning, and optimization techniques to efficiently handle large datasets. Various strategies, including the use of classifiers and support vector machines, are highlighted for improving machine learning performance in a cloud environment.





![Linear Classifier
The quick brown fox jumped over the lazy dog.
‘a’ ... ‘aardvark’ ... ‘dog’ ... ‘the’ ... ‘montañas’ ...
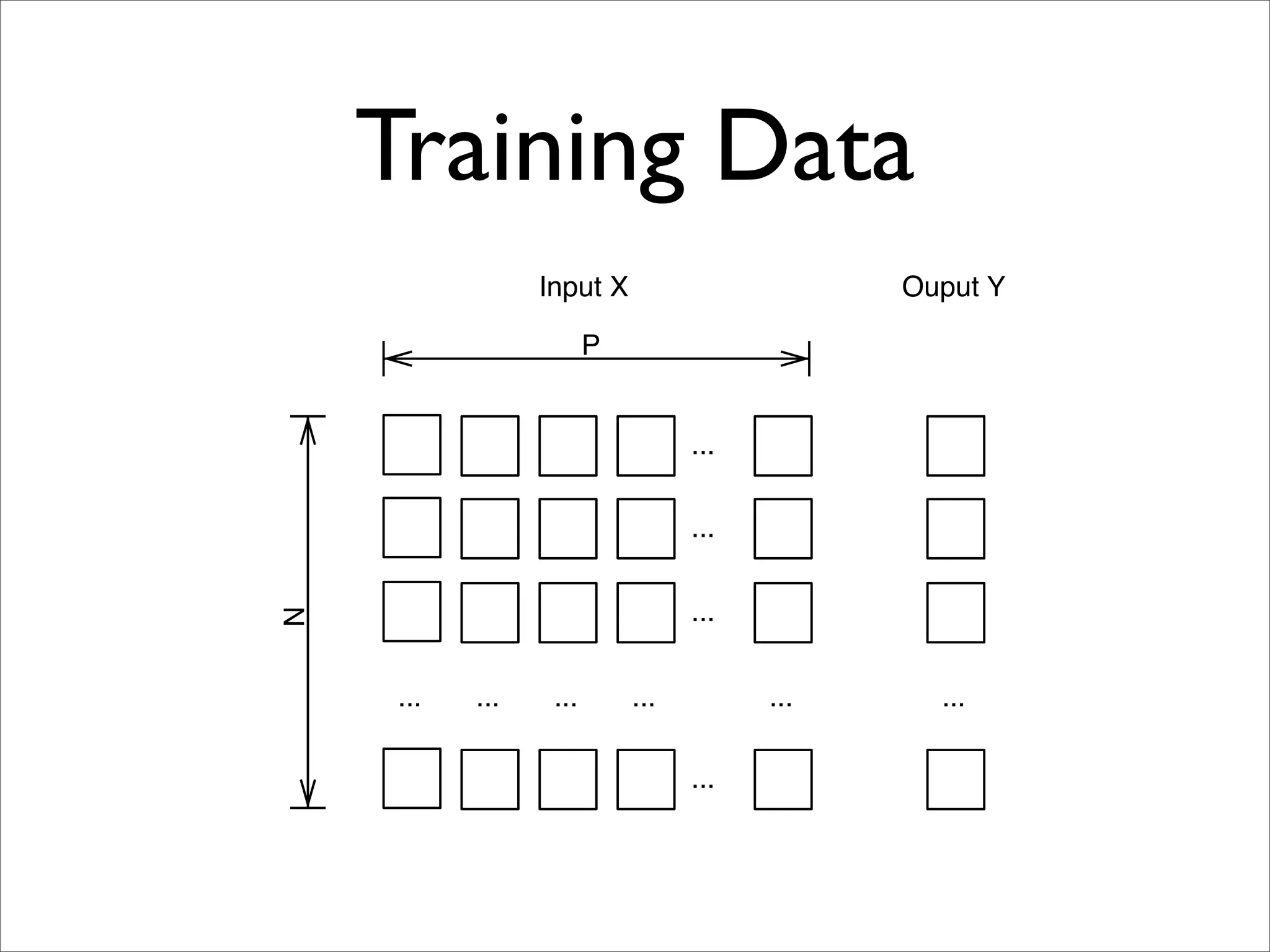
x [ 0, ... 0, ... 1, ... 1, ... 0, ... ]
w [ 0.1, ... 132, ... 150, ... 200, ... -153, ... ]
P
f (x) = w · x = wp ∗ xp
p=1](https://image.slidesharecdn.com/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01/75/Harvard-CS264-09-Machine-Learning-on-Big-Data-Lessons-Learned-from-Google-Projects-Max-Lin-Google-Research-11-2048.jpg)





![Why not Small Data?
[Banko and Brill, 2001]](https://image.slidesharecdn.com/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01/75/Harvard-CS264-09-Machine-Learning-on-Big-Data-Lessons-Learned-from-Google-Projects-Max-Lin-Google-Research-19-2048.jpg)


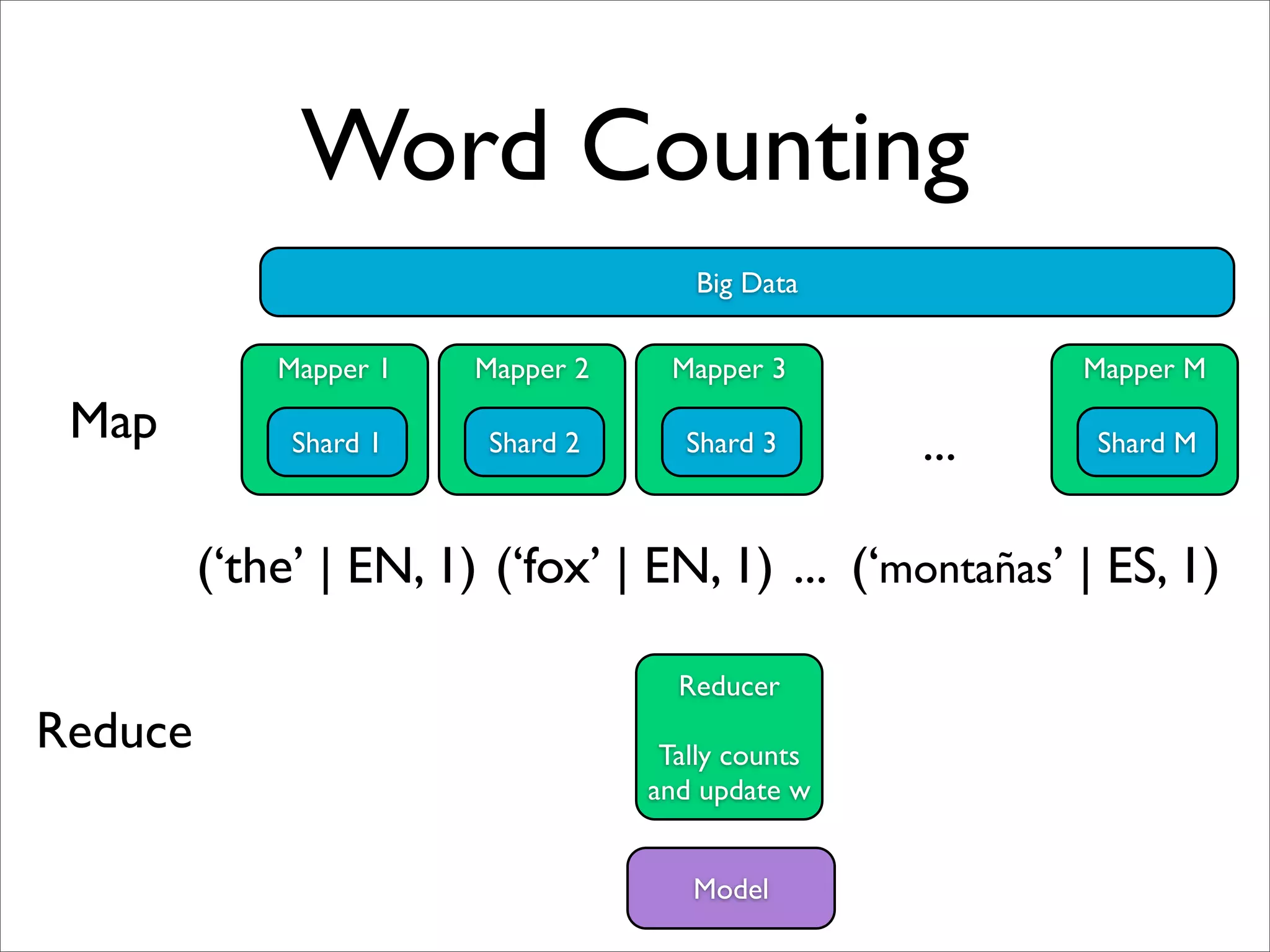
![Word Counting
(‘the|EN’, 1)
X: “The quick brown fox ...”
Map (‘quick|EN’, 1)
Y: EN
(‘brown|EN’, 1)
Reduce [ (‘the|EN’, 1), (‘the|EN’, 1), (‘the|EN’, 1) ]
C(‘the’|EN) = SUM of values = 3
C( the |EN )
w the |EN =
C(EN )](https://image.slidesharecdn.com/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01/75/Harvard-CS264-09-Machine-Learning-on-Big-Data-Lessons-Learned-from-Google-Projects-Max-Lin-Google-Research-22-2048.jpg)







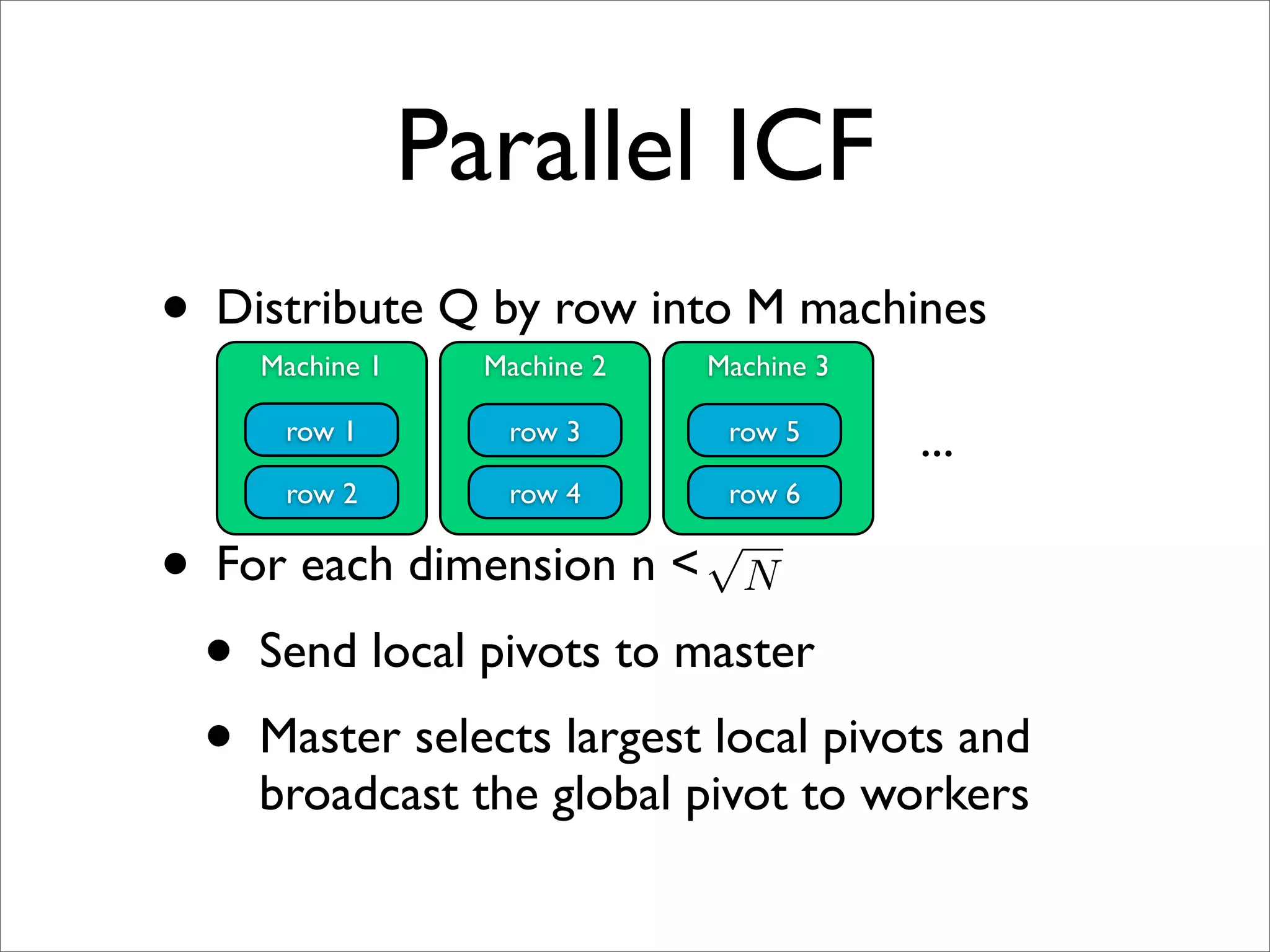
![Parallel SVM [Chang et al, 2007]
• Parallel, row-wise incomplete Cholesky
Factorization for Q
• Parallel interior point method
• Time O(n^3) becomes O(n^2 / M)
√
• Memory O(n^2) becomes O(n N / M)
• Parallel Support Vector Machines (psvm) http://
code.google.com/p/psvm/
• Implement in MPI](https://image.slidesharecdn.com/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01/75/Harvard-CS264-09-Machine-Learning-on-Big-Data-Lessons-Learned-from-Google-Projects-Max-Lin-Google-Research-32-2048.jpg)


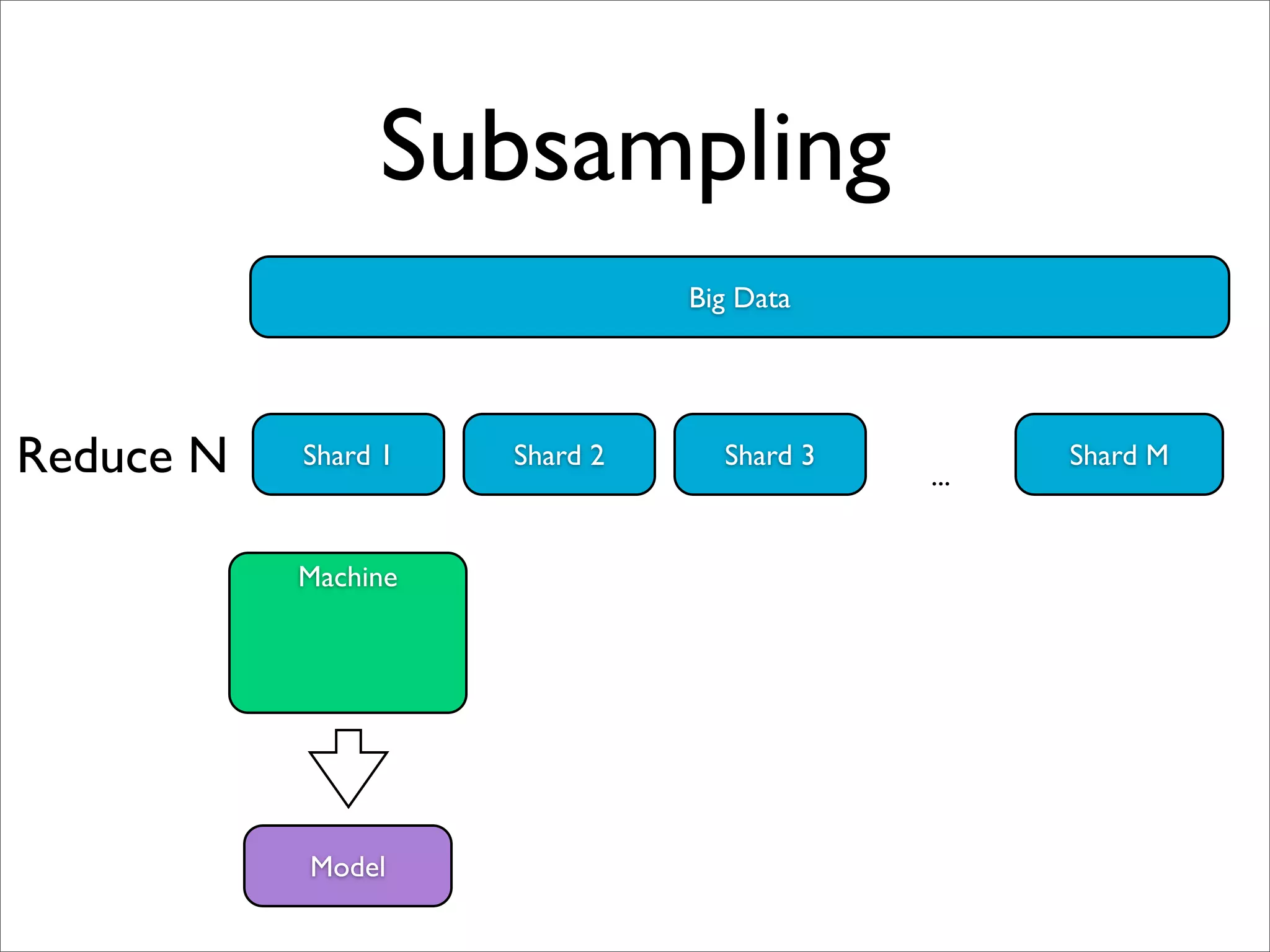
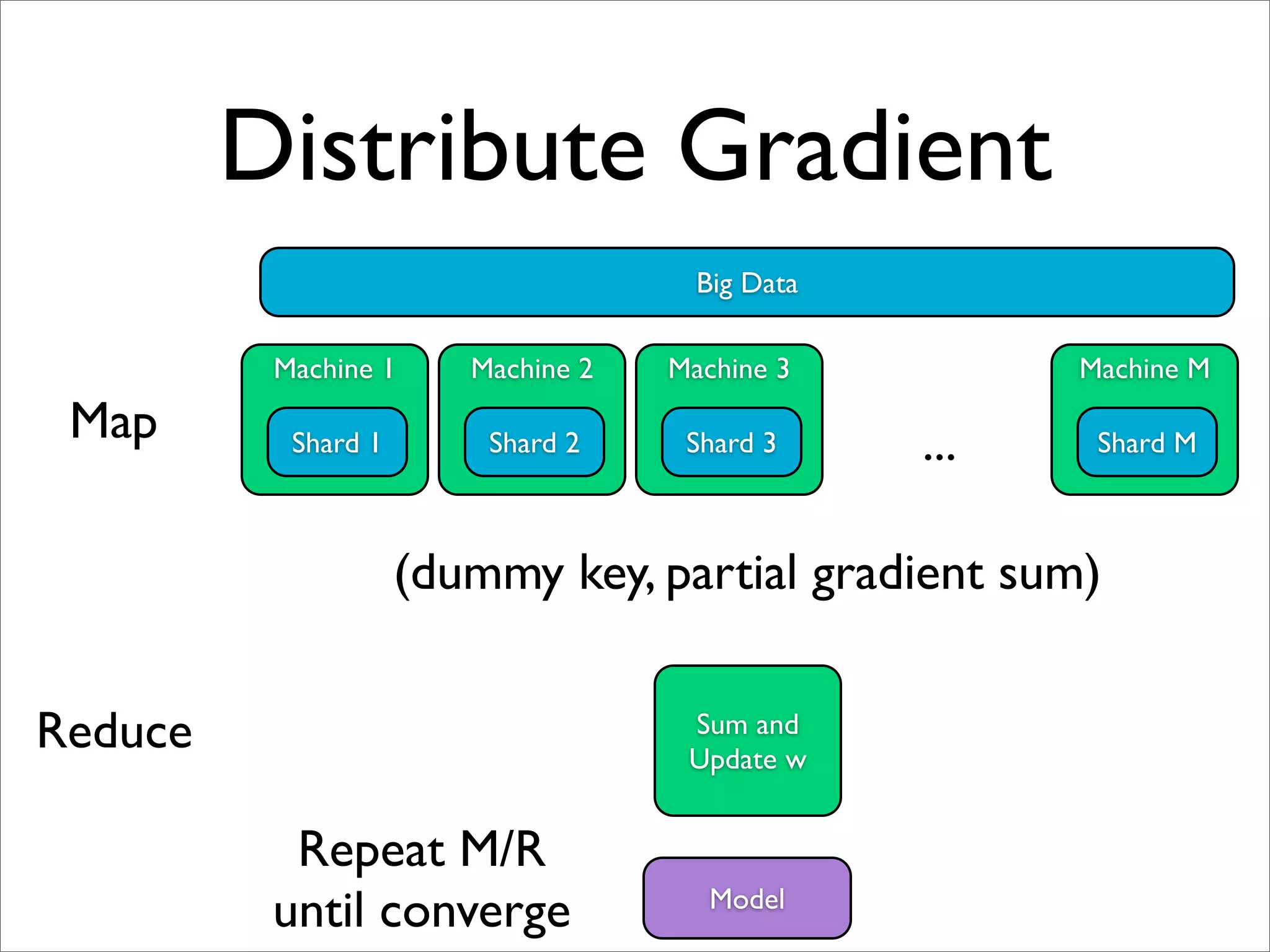
![Parameter Mixture [Mann et al, 2009]
Big Data
Machine 1 Machine 2 Machine 3 Machine M
Map Shard 1 Shard 2 Shard 3 ... Shard M
(dummy key, w1) (dummy key, w2) ...
Reduce Average w
Model](https://image.slidesharecdn.com/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01/75/Harvard-CS264-09-Machine-Learning-on-Big-Data-Lessons-Learned-from-Google-Projects-Max-Lin-Google-Research-38-2048.jpg)

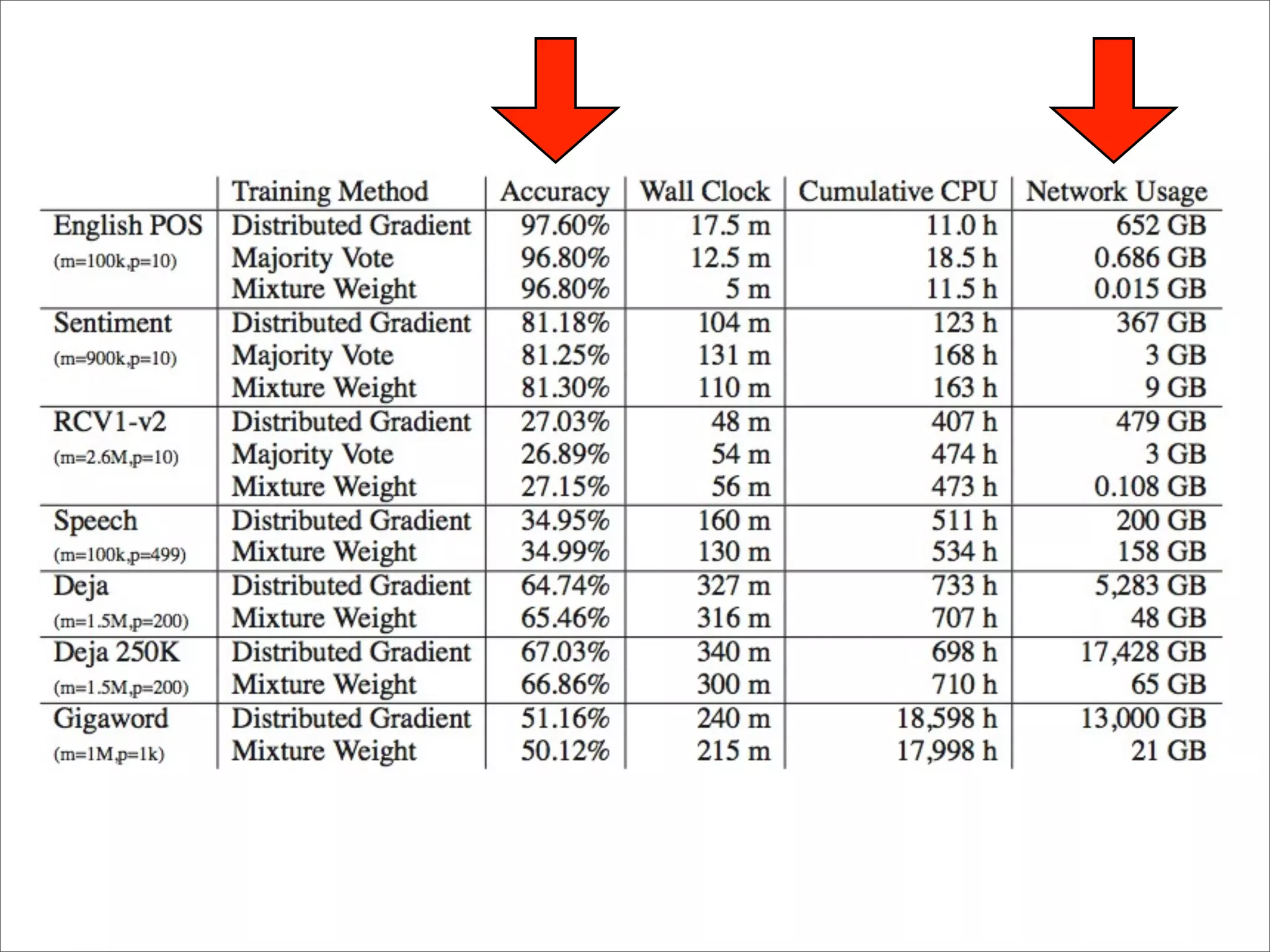
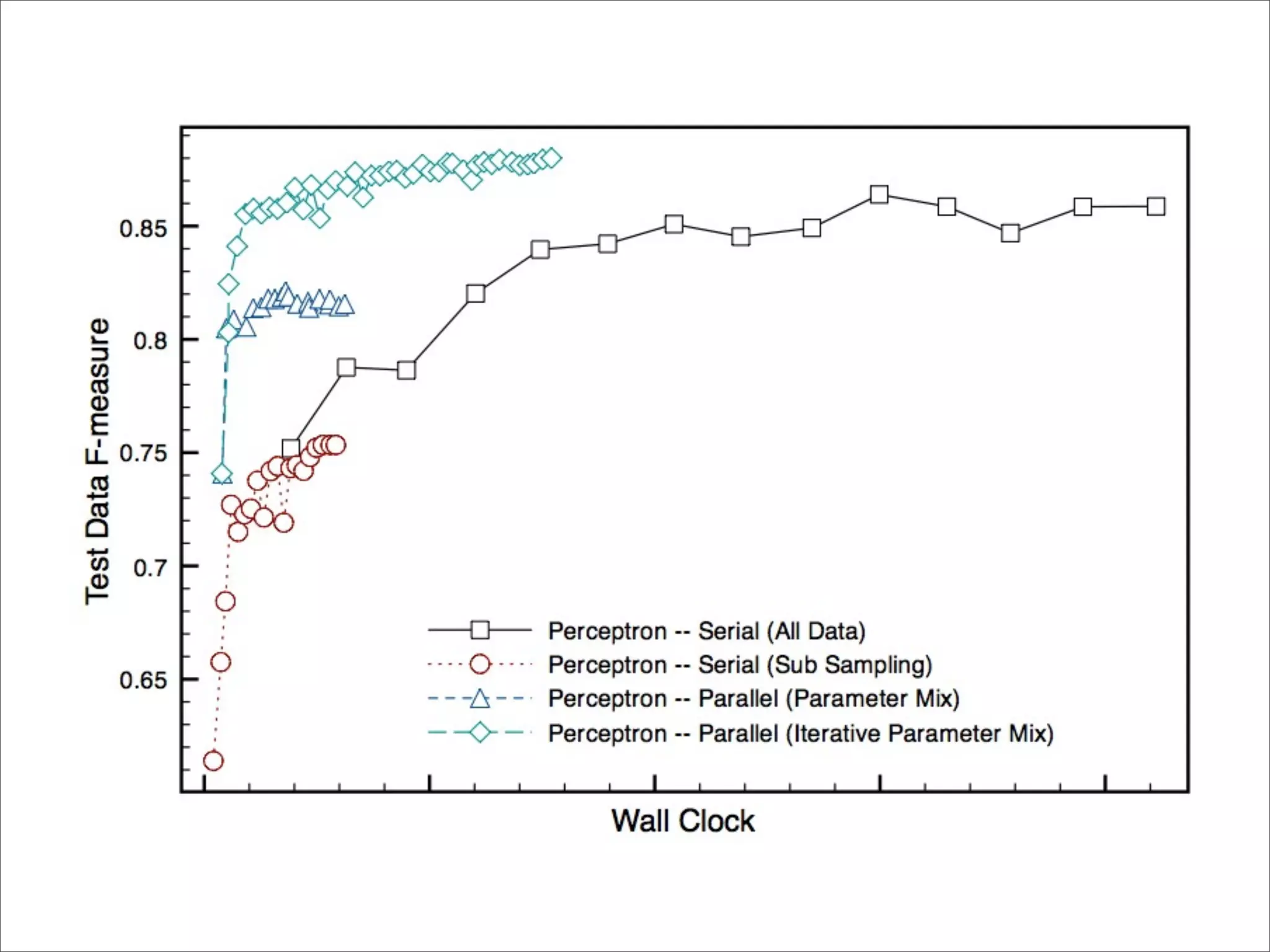
![Iterative Param Mixture [McDonald et al., 2010]
Big Data
Machine 1 Machine 2 Machine 3 Machine M
Map Shard 1 Shard 2 Shard 3 ... Shard M
(dummy key, w1) (dummy key, w2) ...
Reduce
after each Average w
epoch
Model](https://image.slidesharecdn.com/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01/75/Harvard-CS264-09-Machine-Learning-on-Big-Data-Lessons-Learned-from-Google-Projects-Max-Lin-Google-Research-41-2048.jpg)










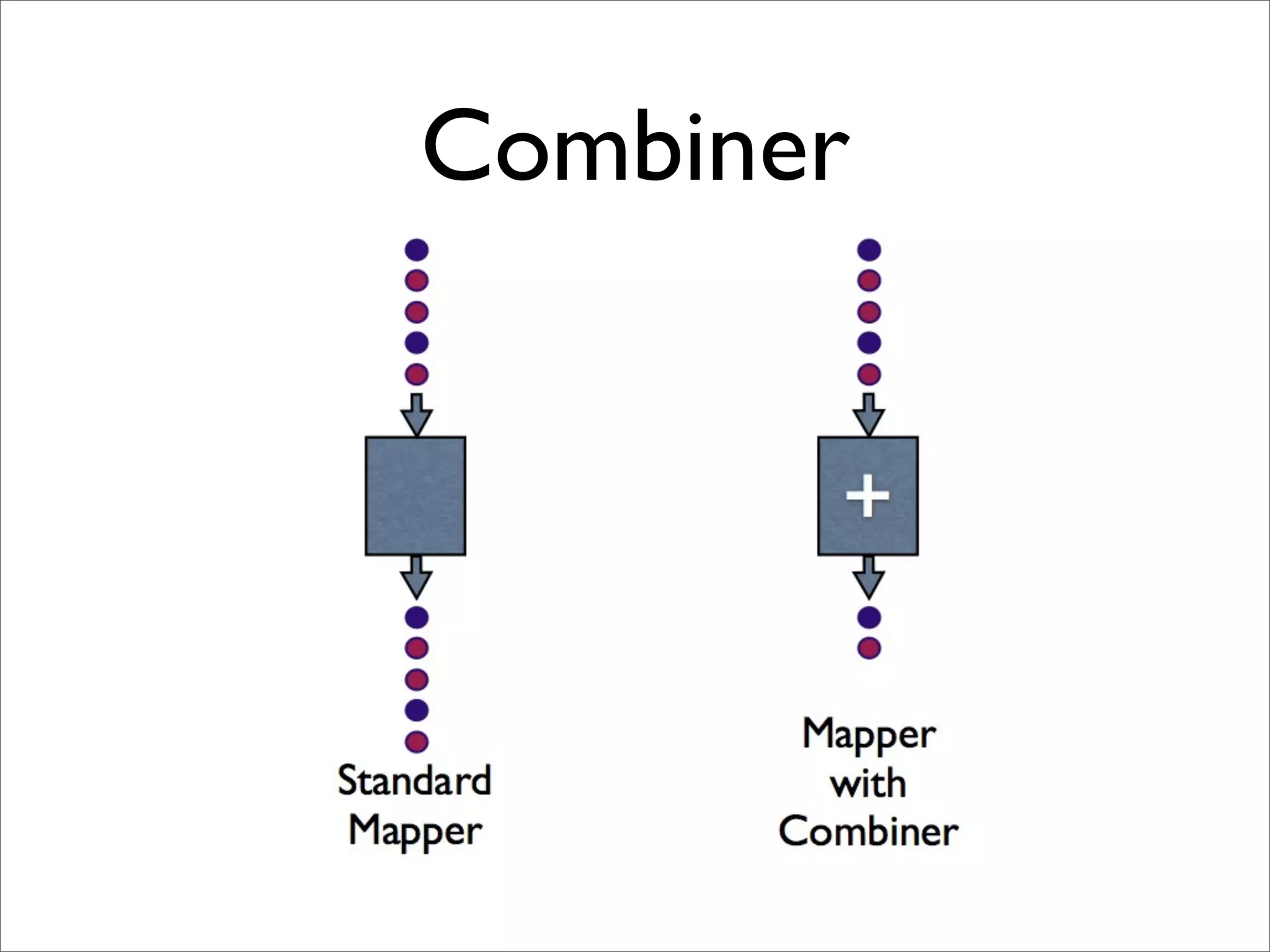
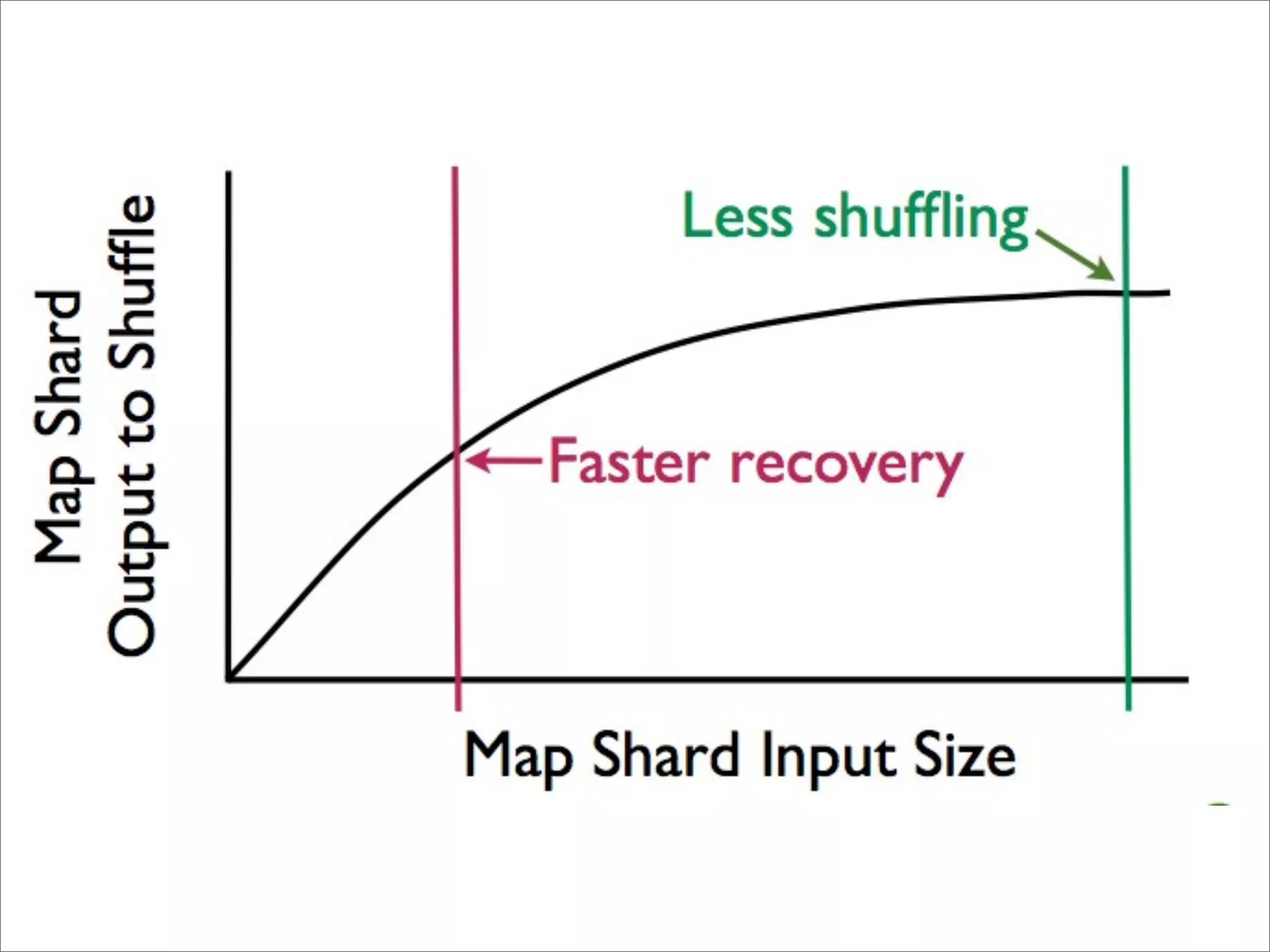
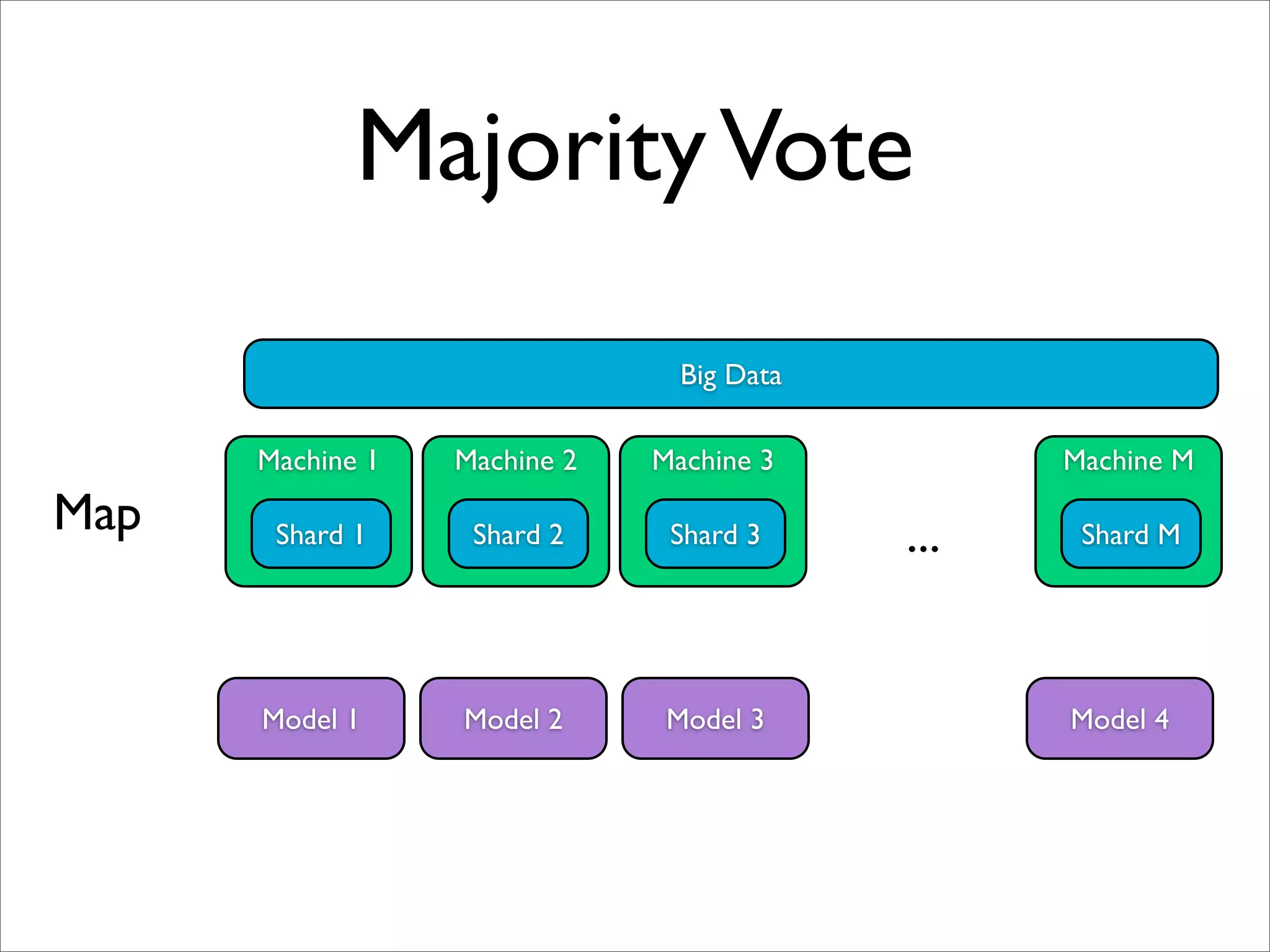
![Multi-shard Combiner
[Chandra et al., 2010]](https://image.slidesharecdn.com/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01/75/Harvard-CS264-09-Machine-Learning-on-Big-Data-Lessons-Learned-from-Google-Projects-Max-Lin-Google-Research-56-2048.jpg)
































![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 16 - Managing Dynamic Parallelism on GPUs: A Case Study of Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/managingdynamicparallelism-110430142356-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 10a - Easy, Effective, Efficient: GPU Programming in Python w...](https://cdn.slidesharecdn.com/ss_thumbnails/andreas-cs264-110331202547-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11a - Programming the Memory Hierarchy with Sequoia (Mike Bau...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407225811-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 12 - Irregular Parallelism on the GPU: Algorithms and Data St...](https://cdn.slidesharecdn.com/ss_thumbnails/owens-harvard-110407-110407230512-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 13 - The R-Stream High-Level Program Transformation Tool / Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/reservoirlabsharvard-presentation-110412184012-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 15a - The Onset of Parallelism, Changes in Computer Architect...](https://cdn.slidesharecdn.com/ss_thumbnails/drich110413cs264-110428210736-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 08a - Cloud Computing, Amazon EC2, MIT StarCluster (Justin Ri...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264-intro-to-cloud-computing-110322172806-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 14 - Dynamic Compilation for Massively Parallel Processors (G...](https://cdn.slidesharecdn.com/ss_thumbnails/gregdiamoscs264lecture-110417212416-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11b - Analysis-Driven Performance Optimization with CUDA (Cli...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407230024-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 15a - Jacket: Visual Computing (James Malcolm, Accelereyes)](https://cdn.slidesharecdn.com/ss_thumbnails/jamesmalcomvisualcomputingcs264-110428210006-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 10b - cl.oquence: High-Level Language Abstractions for Low-Le...](https://cdn.slidesharecdn.com/ss_thumbnails/cl-oquence-cs264-110403182645-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 02 - Parallel Thinking, Architecture, Theory & Patterns](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201102-archtheorypatternshare-110206154047-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 06 - CUDA Ninja Tricks: GPU Scripting, Meta-programming & Aut...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201106-cudaninjasharetmp-110301171948-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 01 - Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201101-introductionshare-110206153841-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Harvard CS264] 04 - Intermediate-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201104-cudaintermediatesharetmpopt-110215180915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 05 - Advanced-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























