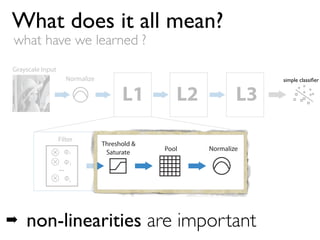
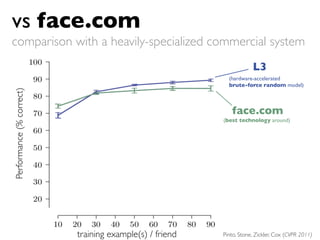
This document discusses using high-performance computing for machine learning tasks like analyzing large convolutional neural networks for visual object recognition. It proposes running hundreds of thousands of large neural network models in parallel on GPUs to more efficiently search the parameter space, beyond what is normally possible with a single graduate student and model. This high-throughput screening approach aims to identify better performing network architectures through exploring a vast number of possible combinations in the available parameter space.




























































![speed
(in billion floating point operations per second)
Q9450 (Matlab/C) [2008] 0.3
Q9450 (C/SSE) [2008] 9.0
7900GTX (OpenGL/Cg) [2006] 68.2
PS3/Cell (C/ASM) [2007] 111.4
8800GTX (CUDA1.x) [2007] 192.7
GTX280 (CUDA2.x) [2008] 339.3
GTX480 (CUDA3.x) [2010] 974.3
(Fermi)
Pinto, Doukhan, DiCarlo, Cox PLoS 2009
Pinto, Cox GPU Comp. Gems 2011](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-61-320.jpg)
![speed
(in billion floating point operations per second)
Q9450 (Matlab/C) [2008] 0.3
Q9450 (C/SSE) [2008] 9.0
7900GTX (OpenGL/Cg) [2006] 68.2
PS3/Cell (C/ASM) [2007] 111.4
8800GTX (CUDA1.x) [2007] 192.7
GTX280 (CUDA2.x) [2008] 339.3
cha n ging...
e
GTX480 (CUDA3.x) [2010]
pe edu p is g a m 974.3
(Fermi)
>1 000X s
Pinto, Doukhan, DiCarlo, Cox PLoS 2009
Pinto, Cox GPU Comp. Gems 2011](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-62-320.jpg)













































![texture<float4, 1, cudaReadModeElementType> tex_float4;
__constant__ float constant[$FILTER_D][$FILTER_W][$N_FILTERS];
#define IMUL(a, b) __mul24(a, b)
plating
Tem
extern "C" {
#for j in xrange($FILTER_H)
__global__ void convolve_beta_j${j}(float4 *input, float4 *output)
{
#set INPUT_BLOCK_W = $BLOCK_W+$FILTER_W-1
__shared__ float shared_in[$INPUT_BLOCK_W][4+1];
// -- input/output offsets
const uint in_idx = (blockIdx.y+$j)*INPUT_W + blockIdx.x*blockDim.x + threadIdx.x;
const uint out_idx = blockIdx.y*OUTPUT_W + blockIdx.x*blockDim.x + threadIdx.x;
float4 input_v4;
// -- load input to shared memory
#for i in xrange($LOAD_ITERATIONS)
#if $i==($LOAD_ITERATIONS-1)
if((threadIdx.x+$BLOCK_W*$i)<$INPUT_BLOCK_W)
#end if
{
input_v4 = tex1Dfetch(tex_float4, in_idx+$BLOCK_W*$i);
shared_in[threadIdx.x+$BLOCK_W*$i][0] = input_v4.x;
shared_in[threadIdx.x+$BLOCK_W*$i][1] = input_v4.y;
shared_in[threadIdx.x+$BLOCK_W*$i][2] = input_v4.z;](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-110-320.jpg)


![Basic GPU Meta-programming System
A Case Study
GPU Meta-Programming:
red Machine Vision
in Biologically-Inspi
s]
[GPU Computing Gem
Pinto N, Cox DD](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-113-320.jpg)
![conv_kernel_4x4x4.cu
conv_kernel_template.cu #include <stdio.h>
texture<float4, 1, cudaReadModeElementType> tex_float4;
__constant__ float constant[4][4][4];
#define IMUL(a, b) __mul24(a, b)
texture<float4, 1, cudaReadModeElementType> tex_float4; extern "C" {
__constant__ float constant[$FILTER_D][$FILTER_W]
[$N_FILTERS]; __global__ void convolve_beta_j0(float4 *input, float4 *output)
{
#define IMUL(a, b) __mul24(a, b)
extern "C" { __shared__ float shared_in[131][4+1];
// -- input/output offsets
#for j in xrange($FILTER_H) const uint in_idx = (blockIdx.y+0)*INPUT_W + blockIdx.x*blockDim.x + threadIdx.x;
const uint out_idx = blockIdx.y*OUTPUT_W + blockIdx.x*blockDim.x + threadIdx.x;
__global__ void convolve_beta_j${j}(float4 *input, float4 float4 input_v4;
*output)
// -- load input to shared memory
{
{
input_v4 = tex1Dfetch(tex_float4, in_idx+128*0);
#set INPUT_BLOCK_W = $BLOCK_W+$FILTER_W-1
shared_in[threadIdx.x+128*0][0] = input_v4.x;
__shared__ float shared_in[$INPUT_BLOCK_W][4+1];
shared_in[threadIdx.x+128*0][1] = input_v4.y;
shared_in[threadIdx.x+128*0][2] = input_v4.z;
shared_in[threadIdx.x+128*0][3] = input_v4.w;
// -- input/output offsets
}
const uint in_idx = (blockIdx.y+$j)*INPUT_W + if((threadIdx.x+128*1)<131)
blockIdx.x*blockDim.x + threadIdx.x; {
const uint out_idx = blockIdx.y*OUTPUT_W +
input_v4 = tex1Dfetch(tex_float4, in_idx+128*1);
blockIdx.x*blockDim.x + threadIdx.x;
shared_in[threadIdx.x+128*1][0] = input_v4.x;
shared_in[threadIdx.x+128*1][1] = input_v4.y;
float4 input_v4;
shared_in[threadIdx.x+128*1][2] = input_v4.z;
shared_in[threadIdx.x+128*1][3] = input_v4.w;
// -- load input to shared memory }
#for i in xrange($LOAD_ITERATIONS) __syncthreads();
#if $i==($LOAD_ITERATIONS-1)
// -- compute dot products
if((threadIdx.x+$BLOCK_W*$i)<$INPUT_BLOCK_W)
float v, w;
#end if
{ float sum0 = 0;
input_v4 = tex1Dfetch(tex_float4, in_idx+$BLOCK_W* float sum1 = 0;
$i); float sum2 = 0;
float sum3 = 0;
shared_in[threadIdx.x+$BLOCK_W*$i][0] = input_v4.x;
shared_in[threadIdx.x+$BLOCK_W*$i][1] = input_v4.y; v = shared_in[threadIdx.x+0][0];
shared_in[threadIdx.x+$BLOCK_W*$i][2] = input_v4.z; w = constant[0][0][0];
shared_in[threadIdx.x+$BLOCK_W*$i][3] = input_v4.w; sum0 += v*w;
} w = constant[0][0][1];
sum1 += v*w;
#end for
w = constant[0][0][2];
sum2 += v*w;
w = constant[0][0][3];
sum3 += v*w;
v = shared_in[threadIdx.x+1][0];
w = constant[0][1][0];
sum0 += v*w;
w = constant[0][1][1];
sum1 += v*w;
w = constant[0][1][2];
sum2 += v*w;
w = constant[0][1][3];
sum3 += v*w;
v = shared_in[threadIdx.x+2][0];
w = constant[0][2][0];
sum0 += v*w;
w = constant[0][2][1];
sum1 += v*w;](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-114-320.jpg)
![conv_kernel_template.cu
texture<float4, 1, cudaReadModeElementType> tex_float4;
__constant__ float constant[$FILTER_D][$FILTER_W]
[$N_FILTERS];
#define IMUL(a, b) __mul24(a, b)
conv_kernel_4x4x4.cu
extern "C" {
#for j in xrange($FILTER_H)
__global__ void convolve_beta_j${j}(float4 *input, float4
20 kB
*output)
{
#set INPUT_BLOCK_W = $BLOCK_W+$FILTER_W-1
__shared__ float shared_in[$INPUT_BLOCK_W][4+1];
// -- input/output offsets
const uint in_idx = (blockIdx.y+$j)*INPUT_W +
blockIdx.x*blockDim.x + threadIdx.x;
const uint out_idx = blockIdx.y*OUTPUT_W +
blockIdx.x*blockDim.x + threadIdx.x;
float4 input_v4;
// -- load input to shared memory
#for i in xrange($LOAD_ITERATIONS)
#if $i==($LOAD_ITERATIONS-1)
if((threadIdx.x+$BLOCK_W*$i)<$INPUT_BLOCK_W)
#end if
$i);
{
input_v4 = tex1Dfetch(tex_float4, in_idx+$BLOCK_W* conv_kernel_8x8x4.cu
shared_in[threadIdx.x+$BLOCK_W*$i][0] = input_v4.x;
shared_in[threadIdx.x+$BLOCK_W*$i][1] = input_v4.y;
shared_in[threadIdx.x+$BLOCK_W*$i][2] = input_v4.z;
shared_in[threadIdx.x+$BLOCK_W*$i][3] = input_v4.w;
}
64 kB
#end for](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-115-320.jpg)



![Smooth syntactic ugliness
Manipulations that are not easily
accessible in CUDA C code:
• fine-controlled loop unrolling / jamming
..)
v = shared_in[threadIdx.x+0][0];
w = constant[0][0][0];
sum0 += v*w;
w = constant[0][0][1];
sum1 += v*w;
w = constant[0][0][2];
sum2 += v*w;
w = constant[0][0][3];
sum3 += v*w;
v = shared_in[threadIdx.x+1][0];
w = constant[0][1][0];
sum0 += v*w;
w = constant[0][1][1];
sum1 += v*w;
w = constant[0][1][2];
sum2 += v*w;
w = constant[0][1][3];
sum3 += v*w;
v = shared_in[threadIdx.x+2][0];
w = constant[0][2][0];
sum0 += v*w;
w = constant[0][2][1];
sum1 += v*w;
w = constant[0][2][2];
sum2 += v*w;
w = constant[0][2][3];
sum3 += v*w;
v = shared_in[threadIdx.x+3][0];
w = constant[0][3][0];
sum0 += v*w;
w = constant[0][3][1];
sum1 += v*w;
w = constant[0][3][2];
sum2 += v*w;
w = constant[0][3][3];
sum3 += v*w;
v = shared_in[threadIdx.x+0][1];
w = constant[1][0][0];
sum0 += v*w;
w = constant[1][0][1];
sum1 += v*w;
w = constant[1][0][2];
sum2 += v*w;
w = constant[1][0][3];
sum3 += v*w;](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-119-320.jpg)

![o t alo ne....
we are n
s for S ignal
Using GPU
elatio n pil ers
Corr ust com
’t tr
itchell
Daniel A. M
Don gmen
The Murch
ode fr
a
ts
ison Widefi
eld Array
c
tical”
e “iden
re thes + g *h;
ompa LOPS
• C
*c +
e*f
770 GF
+ d
b*c grating 8-s
econd snap
shots over
a +=
inte peeling,
roduced by lanking and
b*c;
-2 526 field p d after RFI b
f the J2107 e of the fiel
an image o ht is an imag
S
FLOP
n the left is . On the rig
a += d*c;
Figure 3:
O ing
hout blank
interval wit
20 G
entire time eeled imag
e. noise
the e unp e above the
ntours of th f magnitud
10
along with
co rs o This
at are orde ious data.
a += e*f;
els th dub
ivers at lev ply discard n here
to the rece m will sim tector show
k
ste
ichael hClar
ct in
fl ect or refra real-time sy n-based de
occasion, re s the MWA mple media
integration hich the si
M floor. D
wit
wil
uring deep
l require a
series of d
ata-quality
art.
tests, of w
a += g*h;
n integral p
will form a eenhill
Lincoln Gr
Paul La Plante and
Reference
s
t Boolard
a +=
y, EDGES
Memo, 058
, 2010.
R.J. Cappal
lo, M.F. M
orales, and
ics a ale, d Topics
RFI Statist , C.J. Lonsd l of Selecte
[1] A.E .E. Rogers, , R.J. Sault IE EE Journa
R.B. Wayth eld Array,
. Greenhill, hison Widefi ].
itchell, L.J of the Murc 07.1912 E, 97
[2] D.A. M Time Calib
ration
, [astro-
ph/08 s of the IEE
S.M. O rd, Real- 7 17, 2008 , Proceeding
2 (5), 707– n Overview
1
nuary 201
sday, 27 Ja rocessing, rray: Desig
in Signal P on Widefield A
he Murchis 8]. , Graphics
ale, et al., T 903.182 R.G. Edgar
[3] C.J. Lonsd [ast ro-ph/0 H. Pfister, and Series,
506, 2009, ell, K. Dale, Conference
(8), 1497–1 , D.A. Mitch d Array, ASP
R.B. Wayth on Wide-fiel
Greenhill, the Murchis
IICS‘2011 [4] S.M . Ord, L.J. ata Pro cessing in cal
Units for D Mathemati
Processing 1 radio pola
rimetry. I.
009. aa d
nderstryn20 ing
1
411, 127, 2 .J. Sault, U Janu 6.
. Breg man, and R ursday,.,2117, 137–147, 199
7
alar
amaker, J.D Th pl. Ser
up alogue of sc
[5 ] J.P. H st rophys. S ll-co herency an rophys. Su
ppl.
s, Astron. A . IV. The fu Astron. Ast
foundation polarimetry ric fidelity,
g radio ge and pola
rimet
derstandin](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-121-320.jpg)



![Basic GPU Meta-programming System
A Case Study
GPU Meta-Programming:
red Machine Vision
in Biologically-Inspi
s]
[GPU Computing Gem
Pinto N, Cox DD](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-125-320.jpg)



![version A
conv_kernel_beta_template.cu
...
mad.rn.f32 $r4, s[$ofs3+0x0000], $r4, $r1
mov.b32 $r1, c0[$ofs2+0x0008]
texture<float4, 1, cudaReadModeElementType> tex_float4;
__constant__ float constant[$FILTER_D][$FILTER_W] mad.rn.f32 $r4, s[$ofs3+0x0008], $r1, $r4
[$N_FILTERS];
mov.b32 $r1, c0[$ofs2+0x000c]
#define IMUL(a, b) __mul24(a, b)
extern "C" { mad.rn.f32 $r4, s[$ofs3+0x000c], $r1, $r4
#for j in xrange($FILTER_H) mov.b32 $r1, c0[$ofs2+0x0010]
__global__ void convolve_beta_j${j}(float4 *input, float4
*output)
mad.rn.f32 $r4, s[$ofs3+0x0010], $r1, $r4
{
#set INPUT_BLOCK_W = $BLOCK_W+$FILTER_W-1
__shared__ float shared_in[$INPUT_BLOCK_W][4+1];
...
// -- input/output offsets
const uint in_idx = (blockIdx.y+$j)*INPUT_W +
blockIdx.x*blockDim.x + threadIdx.x;
const uint out_idx = blockIdx.y*OUTPUT_W +
blockIdx.x*blockDim.x + threadIdx.x;
float4 input_v4;
// -- load input to shared memory
#for i in xrange($LOAD_ITERATIONS)
version B
#if $i==($LOAD_ITERATIONS-1)
if((threadIdx.x+$BLOCK_W*$i)<$INPUT_BLOCK_W)
#end if
{
input_v4 = tex1Dfetch(tex_float4, in_idx+$BLOCK_W*
$i);
shared_in[threadIdx.x+$BLOCK_W*$i][0] = input_v4.x;
shared_in[threadIdx.x+$BLOCK_W*$i][1] = input_v4.y;
shared_in[threadIdx.x+$BLOCK_W*$i][2] = input_v4.z;
...
shared_in[threadIdx.x+$BLOCK_W*$i][3] = input_v4.w; mad.rn.f32 $r1, s[$ofs1+0x007c], c0[$ofs1+0x0078], $r1
}
#end for mad.rn.f32 $r1, s[$ofs2+0x0000], c0[$ofs2+0x007c], $r1
mad.rn.f32 $r1, s[$ofs2+0x0008], c0[$ofs2+0x0080], $r1
mad.rn.f32 $r1, s[$ofs2+0x000c], c0[$ofs2+0x0084], $r1
mad.rn.f32 $r1, s[$ofs2+0x0010], c0[$ofs2+0x0088], $r1
...
aster... Why ?
2x f](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-129-320.jpg)

![speed
(in billion floating point operations per second)
Q9450 (Matlab/C) [2008] 0.3
Q9450 (C/SSE) [2008] 9.0
7900GTX (OpenGL/Cg) [2006] 68.2
PS3/Cell (C/ASM) [2007] 111.4
8800GTX (CUDA1.x) [2007] 192.7
GTX280 (CUDA2.x) [2008] 339.3
cha n ging...
e
GTX480 (CUDA3.x) [2010]
pe edu p is g a m 974.3
(Fermi)
>1 000X s
Pinto, Doukhan, DiCarlo, Cox PLoS 2009
Pinto, Cox GPU Comp. Gems 2011](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-131-320.jpg)




















![Empirical Auto-Tuning with Meta-programming
A Case Study
GPU Meta-Programming:
red Machine Vision
in Biologically-Inspi
s]
[GPU Computing Gem
Pinto N, Cox DD](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-152-320.jpg)







![First Last First Last First Last
Affiliation line 1 Affiliation line 1 Affiliation line 1
Fast Machine Learning-based
Affiliation line 2 Affiliation line 2 Affiliation line 2
anon@mail.com anon@mail.com anon@mail.com
ABSTRACT
Runtime Auto-Tuning
designs, the field lacks consensus on exactly how the differ-
The rapidly evolving landscape of multicore architectures ent subsystems (memory, communication and computation)
makes the construction of efficient libraries a daunting task. should be efficiently integrated, modeled and programmed.
A family of methods known collectively as “auto-tuning” has These systems have exhibited varying degrees of memory
emerged to address this challenge. Two major approaches to hierarchy and multi-threading complexity and, as a conse-
auto-tuning are empirical and model-based: empirical auto- quence, they have been increasingly relying on flexible but
tuning is a generic but slow approach that works by mea- low-level software-controlled cache management and paral-
suring runtimes of candidate implementations, model-based lelism [Asanovic et al., 2006] in order to better control and
auto-tuning predicts those runtimes using simplified abstrac- understand the various trade-offs among performance, reli-
tions designed by hand. We show that machine learning ability, energy efficiency, production costs, etc. This evo-
methods for non-linear regression can be used to estimate lution has profoundly altered the landscape of application
timing models from data, capturing the best of both ap- development: programmers are now facing a wide diversity
Machine Learning for Predictive Auto-Tuning with Boosted
proaches. A statistically-derived model offers the speed of of low-level architectural issues that must be carefully bal-
a model-based approach, with the generality and simplicity anced if one is to write code that is both high-performance
of empirical auto-tuning. We validate our approach using and portable.
the filterbank correlation kernel described in Pinto and Cox
Regression Trees
[2012], where we find that 0.1 seconds of hill climbing on 1.1 Motivation
the regression model (“predictive auto-tuning”) can achieve In this rapidly evolving landscape, the construction of gen-
an average of 95% of the speed-up brought by minutes of eral development tools and libraries that fully utilize system
empirical auto-tuning. Our approach is not specific to filter- resources remains a daunting task. Even within special-
bank correlation, nor even to GPU kernel auto-tuning, and ized architectures from the same vendor, such as NVIDIA’s
can be applied to almost any templated-code optimization Graphics Processing Units (GPUs) and the Compute Unified
problem, spanning a wide variety of problem types, kernel Device Architecture (CUDA) [Nickolls et al., 2008, NVIDIA,
types, and platforms. 2011], many developers default to massive amounts of man-
1. INTRODUCTION First Last First Last
ual labor to optimize CUDA code to specific input domains.
In addition, hand-tuning rarely generalizes well to new hard- First Last
Affiliation line 1 Affiliation line 1 Affiliation line 1
ware generations or different input domains, and it can also
Due to power consumption and heat dissipation concerns, be error-prone or far from optimal. One of the reason is that
Affiliation line 2 Affiliation line 2 Affiliation line 2
scientific applications have shifted from computing platforms kernels can produce staggeringly large optimization spaces
where performance had been primarily driven by rises in the [Datta et al., 2008]. The problem is further compounded
anon@mail.com
clock frequency of a single “heavy-weight” processor (with
complex out-of-order control and cache structures) to a plat-
form with ever increasing numbers of “light-weight” cores.
anon@mail.com
by the fact that these spaces can be highly discontinuous
[Ryoo et al., 2008], difficult to explore, and quasi-optimal anon@mail.com
solutions lie at the edge of “performance cliffs” induced by
Interestingly, this shift is now not only relevant to compu- hard device-specific constraints (e.g. register file size or low-
tational sciences but to the development of all computer sys- latency cache size).
James Bergstra
tems: from ubiquitous consumer-facing devices (e.g. phones)
to high-end computer farms for web-scale applications (e.g.
1.2 Auto-Tuning
ABSTRACT
social networks).
Although the future lies in low-power multi-core hardware One strategy for addressing these challenges is to use one
of a variety of automatic methods known collectively as
designs, the field lacks consensus on exactly how the differ-
The rapidly evolving landscape of multicore architectures
Permission to makethe or hard copies of all or part ofof work for
“auto-tuning.” Two major auto-tuning approaches have emer-
ged in the extensive literature covering the subject (see sur-
veys in e.g. [Vuduc et al., 2001, Demmel et al., 2005, Vuduc
makes digital construction this efficient libraries a daunting task.
et al., 2005, Williams, 2008, Datta et al., 2008, Cavazos,
Nicolas Pinto
ent subsystems (memory, communication and computation)
should be efficiently integrated, modeled and programmed.
David Cox
personal or classroom use is granted without fee provided that copies are
2008, Li et al., 2009, Park et al., 2011]): analytical model- These systems have exhibited varying degrees of memory
not A familyfor profit or commercial advantage and that copies
made or distributed of methods known collectively as “auto-tuning” has
driven optimization and empirical optimization [Yotov et al.,
bear this notice and the full citation on the first page. To copy otherwise, to
republish, to post on servers or address this challenge. Two major approaches to
emerged to to redistribute to lists, requires prior specific 2003]. hierarchy and multi-threading complexity and, as a conse-
The model-driven optimization approach uses analytical
permission and/or a fee. quence, they have been increasingly relying on flexible but
auto-tuning are empirical and model-based: empirical auto-
[submitted]
Copyright 20XX ACM X-XXXXX-XX-X/XX/XX ...$10.00. abstractions to model the hardware architectures, in order
tuning is a generic but slow approach that works by mea- low-level software-controlled cache management and paral-
suring runtimes of candidate implementations, model-based lelism [Asanovic et al., 2006] in order to better control and
auto-tuning predicts those runtimes using simplified abstrac- understand the various trade-offs among performance, reli-
tions designed by hand. We show that machine learning ability, energy efficiency, production costs, etc. This evo-
methods for non-linear regression can be used to estimate lution has profoundly altered the landscape of application
timing models from data, capturing the best of both ap- development: programmers are now facing a wide diversity
proaches. A statistically-derived model offers the speed of of low-level architectural issues that must be carefully bal-
anced if one is to write code that is both high-performance](https://image.slidesharecdn.com/2011-12-16hpc-awaremachinelearningandviceversanips2011biglearnshareopt-111217034405-phpapp01/85/High-Performance-Computing-Needs-Machine-Learning-And-Vice-Versa-NIPS-2011-Big-Learning-160-320.jpg)

















![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 16 - Managing Dynamic Parallelism on GPUs: A Case Study of Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/managingdynamicparallelism-110430142356-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 15a - The Onset of Parallelism, Changes in Computer Architect...](https://cdn.slidesharecdn.com/ss_thumbnails/drich110413cs264-110428210736-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 08a - Cloud Computing, Amazon EC2, MIT StarCluster (Justin Ri...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264-intro-to-cloud-computing-110322172806-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 14 - Dynamic Compilation for Massively Parallel Processors (G...](https://cdn.slidesharecdn.com/ss_thumbnails/gregdiamoscs264lecture-110417212416-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 10b - cl.oquence: High-Level Language Abstractions for Low-Le...](https://cdn.slidesharecdn.com/ss_thumbnails/cl-oquence-cs264-110403182645-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 15a - Jacket: Visual Computing (James Malcolm, Accelereyes)](https://cdn.slidesharecdn.com/ss_thumbnails/jamesmalcomvisualcomputingcs264-110428210006-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 09 - Machine Learning on Big Data: Lessons Learned from Googl...](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11a - Programming the Memory Hierarchy with Sequoia (Mike Bau...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407225811-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 10a - Easy, Effective, Efficient: GPU Programming in Python w...](https://cdn.slidesharecdn.com/ss_thumbnails/andreas-cs264-110331202547-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 12 - Irregular Parallelism on the GPU: Algorithms and Data St...](https://cdn.slidesharecdn.com/ss_thumbnails/owens-harvard-110407-110407230512-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 13 - The R-Stream High-Level Program Transformation Tool / Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/reservoirlabsharvard-presentation-110412184012-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11b - Analysis-Driven Performance Optimization with CUDA (Cli...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407230024-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 02 - Parallel Thinking, Architecture, Theory & Patterns](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201102-archtheorypatternshare-110206154047-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Harvard CS264] 01 - Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201101-introductionshare-110206153841-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Harvard CS264] 06 - CUDA Ninja Tricks: GPU Scripting, Meta-programming & Aut...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201106-cudaninjasharetmp-110301171948-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 04 - Intermediate-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201104-cudaintermediatesharetmpopt-110215180915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 05 - Advanced-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
























