This document provides a tutorial introduction to GPGPU computation using NVIDIA CUDA. It begins with a brief overview and warnings about the large numbers involved in GPGPU. The agenda then outlines topics to be covered including general purpose GPU computing using CUDA and optimization topics like memory bandwidth optimization. Key aspects of CUDA programming are introduced like the CUDA memory model, compute capabilities of GPUs, and profiling tools. Examples are provided of simple CUDA kernels and how to configure kernel launches for grids and blocks of threads. Optimization techniques like choosing block/grid sizes to maximize occupancy are also discussed.























![41
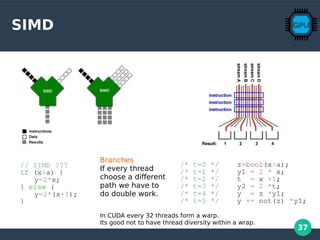
A Simple Cuda Kernel
SAXPY stands for “Single-Precision A·X Plus Y”. It is a function
in the standard Basic Linear Algebra Subroutines (BLAS)library.
SAXPY is a combination of scalar multiplication and vector
addition, and it’s very simple: it takes as input two vectors of
32-bit floats X and Y with N elements each, and a scalar value A.
It multiplies each element X[i] by A and adds the result to Y[i].
__global__
void saxpy(int n, float a, float *x, float *y)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i];
}
// Perform SAXPY on 1M elements
int N = 1<<20;
saxpy<<<<<<40964096, 256, 256>>>>>>(N, 2.0f, d_x, d_y);](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-41-320.jpg)




![49
Calling the Kernel, The hard way
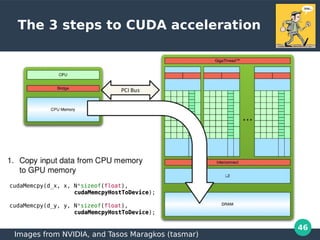
int main(void) {
int N = 1<<20;
float *x, *y, *d_x, *d_y;
x = (float*)malloc(N*sizeof(float));
y = (float*)malloc(N*sizeof(float));
cudaMalloc(&d_x, N*sizeof(float));
cudaMalloc(&d_y, N*sizeof(float));
for (int i = 0; i < N; i++) {x[i] = 1.0f; y[i] = 2.0f;}
cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice);
saxpy<<<(N+255)/256, 256>>>(N, 2.0f, d_x, d_y);
cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost);
float maxError = 0.0f;
for (int i = 0; i < N; i++){ maxError = max(maxError, abs(y[i]-4.0f));}
printf("Max error: %fn", maxError);
cudaFree(d_x); cudaFree(d_y); free(x); free(y);
}](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-49-320.jpg)
![51
Calling the Kernel, The easy way
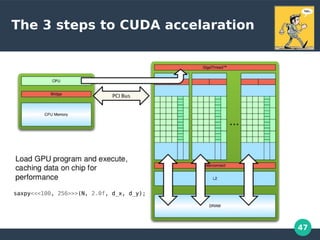
int main(void)
{
int N = 1<<20; // 1M elements
// Allocate Unified Memory -- accessible from CPU or GPU
float *x, *y;
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// Init arrays ....
// Perform SAXPY on 1M elements
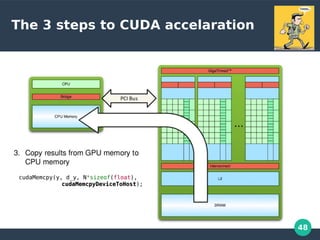
saxpy<<<(N+255)/256, 256>>>(N, 2.0f, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = max(maxError, abs(y[i]-4.0f));
printf("Max error: %fn", maxError);
// Free memory
cudaFree(x);
cudaFree(y);
}
https://devblogs.nvidia.com/even-easier-introduction-cuda/
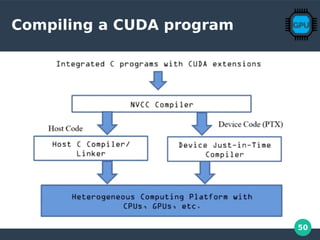
Unified memoryUnified memory
architecturearchitecture
https://devblogs.nvidia.com/unified-memory-in-cuda-6/](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-51-320.jpg)
![54
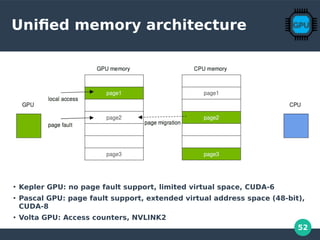
Speedup! Initialize with a Kernel
__global__ void init_kernel(int n, NUMBER *x, NUMBER *y)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) {
x[i] = 1.0f;
y[i] = 2.0f;
}
}
https://devblogs.nvidia.com/unified-memory-cuda-beginners/](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-54-320.jpg)
![55
Speedup! The fastest
__global__
void barrier_kernel(int n, NUMBER a, NUMBER *x, NUMBER *y)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) { y[i] = a*x[i] + y[i];
x[i] = 1.0f;
y[i] = 2.0f;
// Not really need it here
__syncthreads();
y[i] = a*x[i] + y[i];
}
}
https://devblogs.nvidia.com/unified-memory-cuda-beginners/](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-55-320.jpg)


![62
An OpenCL Kernel
●
The Kernel
__kernel void vector_add(__global const int *A, __global const int *B, __global int *C) {
// Get the index of the current element to be processed
int i = get_global_id(0);
// Do the operation
C[i] = A[i] + B[i];
}
// 100 Lines of Code
// Create a program from the kernel source
cl_program program = clCreateProgramWithSource(context, 1,
(const char **)&source_str, (const size_t *)&source_size, &ret);
// Build the program
ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
// Create the OpenCL kernel
cl_kernel kernel = clCreateKernel(program, "vector_add", &ret);
// Set the arguments of the kernel
ret = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&a_mem_obj);
ret = clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&b_mem_obj);
ret = clSetKernelArg(kernel, 2, sizeof(cl_mem), (void *)&c_mem_obj);
// Execute the OpenCL kernel on the list
size_t global_item_size = LIST_SIZE; // Process the entire lists
size_t local_item_size = 64; // Divide work items into groups of 64
ret = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL,
&global_item_size, &local_item_size, 0, NULL, NULL);
https://www.eriksmistad.no/getting-started-with-opencl-and-gpu-computing/
●
The Setup
– AMD SDK
– Intel OpenCL
SDK
– Cuda
– Xilinx
SDAccel
●
The Driver](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-62-320.jpg)

![64
Alternative Ways to SAXPY
Thrust & cuBLAS
using thrust::placeholders;
int N = 1<<20;
thrust::host_vector x(N), y(N);
...
// alloc and copy host to device
thrust::device_vector d_x = x;
thrust::device_vector d_y = y;
// Perform SAXPY C++ STLC++ STL Way
thrust::transform(d_x.begin(), d_x.end(),
d_y.begin(), d_y.begin(), 2.0f * _1 + _2);
// copy results to the host vector
y = d_y;
int N = 1<<20;
cublasInit();
cublasSetVector(N, sizeof(x[0]), x, 1, d_x, 1);
cublasSetVector(N, sizeof(y[0]), y, 1, d_y, 1);
// Perform SAXPY on 1M elements
cublasSaxpy(N, 2.0, d_x, 1, d_y, 1);
cublasGetVector(N, sizeof(y[0]), d_y, 1, y, 1);
cublasShutdown();
https://devblogs.nvidia.com/six-ways-saxpy/
ThrustThrust](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-64-320.jpg)
![65
Open ACC
void
saxpy(int n, float a, float * restrict x,
float * restrict y) {
#pragma acc kernels
for (int i = 0; i < n; ++i)
y[i] = a*x[i] + y[i];
}
...
// Perform SAXPY on 1M elements
// Looks like a normal C call
saxpy(1<<20, 2.0, x, y);
#pragma acc kernels
#pragma acc parallel
#pragma acc data
#pragma acc loop
#pragma acc cache
#pragma acc update
#pragma acc declare
#pragma acc wait
https://www.openacc.org/
●
Directive based
●
Cray, Nvidia, PGI
●
Extension of openMP
– Will be merged](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-65-320.jpg)
![66
Even More Ways to SAXPY
Python & Fortran
module mymodule contains
attributes(global) subroutine saxpy(n, a, x, y)
real :: x(:), y(:), a
integer :: n, i
attributes(value) :: a, n
i = threadIdx%x+(blockIdx%x-1)*blockDim%x
if (i<=n) y(i) = a*x(i)+y(i)
end subroutine saxpy
end module mymodule
program main
use cudafor; use mymodule
real, device :: x_d(2**20), y_d(2**20)
x_d = 1.0, y_d = 2.0
! Perform SAXPY on 1M elements
call saxpy<<<4096, 256>>>(2**20, 2.0, x_d, y_d)
end program main
from copperhead import *
import numpy as np
@cu
def saxpy(a, x, y):
return [a * xi + yi for xi, yi in zip(x, y)]
x = np.arange(2**20, dtype=np.float32)
y = np.arange(2**20, dtype=np.float32)
with places.gpu0:
gpu_result = saxpy(2.0, x, y)
with places.openmp:
cpu_result = saxpy(2.0, x, y)
https://devblogs.nvidia.com/six-ways-saxpy/
Copperhead (Python)Copperhead (Python) FortranFortran](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-66-320.jpg)

![68
Matrix Transpose Problem
10 n-1
// CPU code
void transpose_CPU(float in[], float
out[]{
for(int j=0; j < N; j++)
for(int i=0; i < N; i++)
// out(j,i) = in(i,j)
out[j + i*N] = in[i + j*N];
}
// Single Thread
__global__ void
transpose_serial(float in[], float out[])
{
for(int j=0; j < N; j++)
for(int i=0; i < N; i++)
out[j + i*N] = in[i + j*N];
}
transpose_serial<<<1,1>>>(d_in, d_out);
N = 1024
https://devblogs.nvidia.com/efficient-matrix-transpose-cuda-cc/
1 Thread
2 Inner Loops
No parallelism](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-68-320.jpg)
![69
Matrix Transpose Problem
Some Parallelism
10 n-1
// 1 Thread per row
__global__ void
transpose_parallel_per_row(float in[], float out[])
{
int i = threadIdx.x;
for(int j=0; j < N; j++)
// out(j,i) = in(i,j)
out[j + i*N] = in[i + j*N];
}
transpose_parallel_per_row<<<1,N>>>(d_in, d_out);
Why not :transpose_parallel_per_row<<<N,1>>>(d_in, d_out)??
1 Block
1024 Threads
1 Loop
Some Parallelism](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-69-320.jpg)
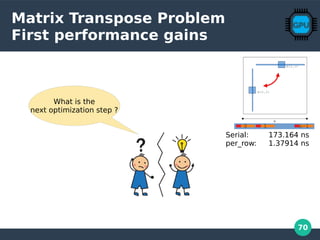
![71
Matrix Transpose Problem
Going full parallel
__global__ void
transpose_parallel_per_element(float in[], float out[]) {
int i = blockIdx.x * K + threadIdx.x;
int j = blockIdx.y * K + threadIdx.y;
out[j + i*N] = in[i + j*N];
}
dim3 blocks(N/K,N/K);
dim3 threads(K,K);
transpose_parallel_per_element<<<blocks,threads>>>(d_in, d_out);
Warning: Maximum parallelism not always gives the best performance
32 X 32 Blocks
32 X 32 Threads/Block
Maximum parallelism
No Loops](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-71-320.jpg)




![79
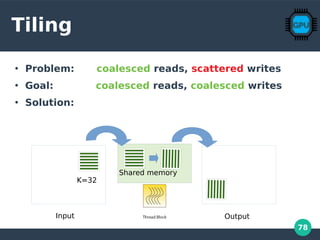
Tilling Code
const int N= 1024; // matrix size is NxN
const int K= 32; // tile size is KxK
__global__ void
transpose_parallel_per_element_tiled(float in[], float out[])
{
// (i,j) locations of the tile corners for input & output matrices:
int in_corner_i = blockIdx.x * K, in_corner_j = blockIdx.y * K;
int out_corner_i = blockIdx.y * K, out_corner_j = blockIdx.x * K;
int x = threadIdx.x, y = threadIdx.y;
__shared__ float tile[K][K];
// coalesced read from global mem, TRANSPOSED write into shared mem:
tile[y][x] = in[(in_corner_i + x) + (in_corner_j + y)*N];
__syncthreads();
// read from shared mem, coalesced write to global mem:
out[(out_corner_i + x) + (out_corner_j + y)*N] = tile[x][y];
}
dim3 blocks16x16(N/K,N/K); // blocks per grid
dim3 threads16x16(K,K); // threads per block
transpose_parallel_per_element_tiled<<<blocks,threads>>>(d_in, d_out);
// to be launched with one thread per element, in (tilesize)x(tilesize) threadblocks
// thread blocks read & write tiles, in coalesced fashion
// adjacent threads read adjacent input elements, write adjacent output elmts
Shared
synchonize](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-79-320.jpg)



![83
Tilling Code
const int N= 1024;
const int K= 32;
__global__ void
transpose_parallel_per_element_tiled(float in[], float out[])
{
// (i,j) locations of the tile corners for input & output matrices:
int in_corner_i = blockIdx.x * K, in_corner_j = blockIdx.y * K;
int out_corner_i = blockIdx.y * K, out_corner_j = blockIdx.x * K;
int x = threadIdx.x, y = threadIdx.y;
__shared__ float tile[K][K];
// coalesced read from global mem, TRANSPOSED write into shared mem:
tile[y][x] = in[(in_corner_i + x) + (in_corner_j + y)*N];
__syncthreads();
// read from shared mem, coalesced write to global mem:
out[(out_corner_i + x) + (out_corner_j + y)*N] = tile[x][y];
}
dim3 blocks16x16(N/K,N/K); // blocks per grid
dim3 threads16x16(K,K); // threads per block
transpose_parallel_per_element_tiled<<<blocks,threads>>>(d_in, d_out);
Shared
synchonize
Increase number of blocks per streaming processor
Reduce number of threads
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-83-320.jpg)

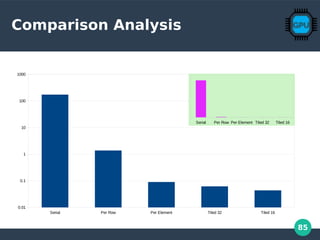
![86
Memory Coalescing
in transpose_parallel_per_element
10 n-1
const int N= 1024; // matrix size is NxN
const int K= 32; // tile size is KxK
__global__ void
transpose_parallel_per_element(float in[], float out[])
{
int i = blockIdx.x * K + threadIdx.x;
int j = blockIdx.y * K + threadIdx.y;
out[j + i*N] = in[i + j*N];
}
32X32
BAD!
BAD!
N = 1024
N = 1024
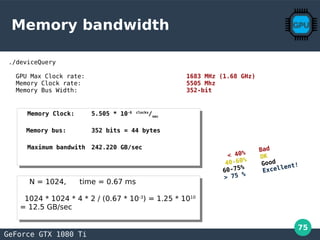
Most GPU codes are bandwith limitedMost GPU codes are bandwith limited
copy
shared memory copy
naive transpose
coalesced transpose
conflict-free transpose
0 50 100 150 200 250 300 350 400
< 40%
Bad
40-60%
OK
60-75%
Good
> 75 %
Excellent!](https://image.slidesharecdn.com/gpu-perf-presentation-190314164200-200106165805/85/GPGPU-Computation-86-320.jpg)

























![[PPT] _ Unit 2 _ Complete PPT.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pptunit2completeppt-220516115836-332a1107-thumbnail.jpg?width=640&height=640&fit=bounds)