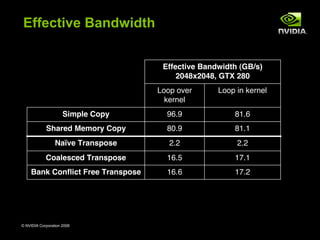
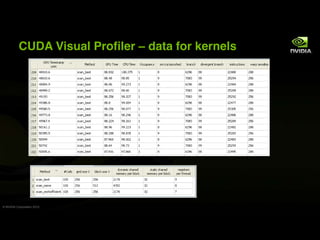
The document discusses optimizations for memory and communication in massively parallel computing. It recommends caching data in faster shared memory to reduce loads and stores to global device memory. This can improve performance by avoiding non-coalesced global memory accesses. The document provides an example of coalescing writes for a matrix transpose by first loading data into shared memory and then writing columns of the tile to global memory in contiguous addresses.























![Matrix Copy Kernel
__global__ void copy(float *odata, float *idata, int width,
int height)
{
int xIndex = blockIdx.x * TILE_DIM + threadIdx.x;
int yIndex = blockIdx.y * TILE_DIM + threadIdx.y;
int index = xIndex + width*yIndex;
for (int i = 0; i < TILE_DIM; i += BLOCK_ROWS) {
odata[index+i*width] = idata[index+i*width];
}
TILE_DIM = 32
}
BLOCK_ROWS = 8
idata odata
32x32 tile
32x8 thread block
idata and odata
in global memory
Elements copied by a half-warp of threads
© NVIDIA Corporation 2008 25](https://image.slidesharecdn.com/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02/85/Harvard-CS264-05-Advanced-level-CUDA-Programming-24-320.jpg)
![Matrix Copy Kernel Timing
Measure elapsed time over loop
Looping/timing done in two ways:
Over kernel launches (nreps = 1)
Includes launch/indexing overhead
Within the kernel over loads/stores (nreps > 1)
Amortizes launch/indexing overhead
__global__ void copy(float *odata, float* idata, int width,
int height, int nreps)
{
int xIndex = blockIdx.x * TILE_DIM + threadIdx.x;
int yIndex = blockIdx.y * TILE_DIM + threadIdx.y;
int index = xIndex + width*yIndex;
for (int r = 0; r < nreps; r++) {
for (int i = 0; i < TILE_DIM; i += BLOCK_ROWS) {
odata[index+i*width] = idata[index+i*width];
}
}
}
© NVIDIA Corporation 2008 26](https://image.slidesharecdn.com/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02/85/Harvard-CS264-05-Advanced-level-CUDA-Programming-25-320.jpg)
![Naïve Transpose
Similar to copy
Input and output matrices have different indices
__global__ void transposeNaive(float *odata, float* idata, int width,
int height, int nreps)
{
int xIndex = blockIdx.x * TILE_DIM + threadIdx.x;
int yIndex = blockIdx.y * TILE_DIM + threadIdx.y;
int index_in = xIndex + width * yIndex;
int index_out = yIndex + height * xIndex;
for (int r=0; r < nreps; r++) {
for (int i=0; i<TILE_DIM; i+=BLOCK_ROWS) {
odata[index_out+i] = idata[index_in+i*width];
}
} idata odata
}
© NVIDIA Corporation 2008 27](https://image.slidesharecdn.com/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02/85/Harvard-CS264-05-Advanced-level-CUDA-Programming-26-320.jpg)























![Coalescing through shared memory
__global__ void transposeCoalesced(float *odata, float *idata, int width,
int height, int nreps)
{
__shared__ float tile[TILE_DIM][TILE_DIM];
int xIndex = blockIdx.x * TILE_DIM + threadIdx.x;
int yIndex = blockIdx.y * TILE_DIM + threadIdx.y;
int index_in = xIndex + (yIndex)*width;
xIndex = blockIdx.y * TILE_DIM + threadIdx.x;
yIndex = blockIdx.x * TILE_DIM + threadIdx.y;
int index_out = xIndex + (yIndex)*height;
for (int r=0; r < nreps; r++) {
for (int i=0; i<TILE_DIM; i+=BLOCK_ROWS) {
tile[threadIdx.y+i][threadIdx.x] = idata[index_in+i*width];
}
__syncthreads();
for (int i=0; i<TILE_DIM; i+=BLOCK_ROWS) {
odata[index_out+i*height] = tile[threadIdx.x][threadIdx.y+i];
}
}
}
© NVIDIA Corporation 2008 36](https://image.slidesharecdn.com/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02/85/Harvard-CS264-05-Advanced-level-CUDA-Programming-50-320.jpg)








![Bank Conflicts in Transpose
32x32 shared memory tile of floats
Data in columns k and k+16 are in same bank
16-way bank conflict reading half columns in tile
Solution - pad shared memory array
__shared__ float tile[TILE_DIM][TILE_DIM+1];
Q: How to avoid bank conflicts ?
Data in anti-diagonals are in same bank
idata odata
tile
© NVIDIA Corporation 2008 43](https://image.slidesharecdn.com/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02/85/Harvard-CS264-05-Advanced-level-CUDA-Programming-59-320.jpg)
![Bank Conflicts in Transpose
32x32 shared memory tile of floats
Data in columns k and k+16 are in same bank
16-way bank conflict reading half columns in tile
Solution - pad shared memory array
__shared__ float tile[TILE_DIM][TILE_DIM+1];
Data in anti-diagonals are in same bank
idata odata
tile
© NVIDIA Corporation 2008 43](https://image.slidesharecdn.com/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02/85/Harvard-CS264-05-Advanced-level-CUDA-Programming-60-320.jpg)









![Diagonal Transpose
__global__ void transposeDiagonal(float *odata, float *idata, int width,
int height, int nreps)
{
__shared__ float tile[TILE_DIM][TILE_DIM+1];
int blockIdx_y = blockIdx.x; Add lines to map diagonal
int blockIdx_x = (blockIdx.x+blockIdx.y)%gridDim.x; to Cartesian coordinates
int xIndex = blockIdx_x * TILE_DIM + threadIdx.x;
int yIndex = blockIdx_y * TILE_DIM + threadIdx.y;
int index_in = xIndex + (yIndex)*width;
Replace
xIndex = blockIdx_y * TILE_DIM + threadIdx.x;
yIndex = blockIdx_x * TILE_DIM + threadIdx.y; blockIdx.x
int index_out = xIndex + (yIndex)*height; with
blockIdx_x,
for (int r=0; r < nreps; r++) { blockIdx.y
for (int i=0; i<TILE_DIM; i+=BLOCK_ROWS) { with
tile[threadIdx.y+i][threadIdx.x] = idata[index_in+i*width]; blockIdx_y
}
__syncthreads();
for (int i=0; i<TILE_DIM; i+=BLOCK_ROWS) {
odata[index_out+i*height] = tile[threadIdx.x][threadIdx.y+i];
}
}
}
© NVIDIA Corporation 2008 49](https://image.slidesharecdn.com/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02/85/Harvard-CS264-05-Advanced-level-CUDA-Programming-71-320.jpg)

























![Register Dependency
Read-after-write register dependency
Instruction’s result can be read ~24 cycles later
Scenarios: CUDA: PTX:
x = y + 5; add.f32 $f3, $f1, $f2
z = x + 3; add.f32 $f5, $f3, $f4
s_data[0] += 3; ld.shared.f32 $f3, [$r31+0]
add.f32 $f3, $f3, $f4
To completely hide the latency:
Run at least 192 threads (6 warps) per multiprocessor
At least 25% occupancy (1.0/1.1), 18.75% (1.2/1.3)
Threads do not have to belong to the same thread block
© NVIDIA Corporation 2008 62](https://image.slidesharecdn.com/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02/85/Harvard-CS264-05-Advanced-level-CUDA-Programming-97-320.jpg)























































































![[05][cuda 및 fermi 최적화 기술] hryu optimization](https://cdn.slidesharecdn.com/ss_thumbnails/05cudafermihryuoptimization-110106231451-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11a - Programming the Memory Hierarchy with Sequoia (Mike Bau...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407225811-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 02 - Parallel Thinking, Architecture, Theory & Patterns](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201102-archtheorypatternshare-110206154047-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 16 - Managing Dynamic Parallelism on GPUs: A Case Study of Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/managingdynamicparallelism-110430142356-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 04 - Intermediate-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201104-cudaintermediatesharetmpopt-110215180915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 06 - CUDA Ninja Tricks: GPU Scripting, Meta-programming & Aut...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201106-cudaninjasharetmp-110301171948-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 10a - Easy, Effective, Efficient: GPU Programming in Python w...](https://cdn.slidesharecdn.com/ss_thumbnails/andreas-cs264-110331202547-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 09 - Machine Learning on Big Data: Lessons Learned from Googl...](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 08a - Cloud Computing, Amazon EC2, MIT StarCluster (Justin Ri...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264-intro-to-cloud-computing-110322172806-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11b - Analysis-Driven Performance Optimization with CUDA (Cli...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407230024-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 13 - The R-Stream High-Level Program Transformation Tool / Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/reservoirlabsharvard-presentation-110412184012-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 15a - The Onset of Parallelism, Changes in Computer Architect...](https://cdn.slidesharecdn.com/ss_thumbnails/drich110413cs264-110428210736-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 12 - Irregular Parallelism on the GPU: Algorithms and Data St...](https://cdn.slidesharecdn.com/ss_thumbnails/owens-harvard-110407-110407230512-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 14 - Dynamic Compilation for Massively Parallel Processors (G...](https://cdn.slidesharecdn.com/ss_thumbnails/gregdiamoscs264lecture-110417212416-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 10b - cl.oquence: High-Level Language Abstractions for Low-Le...](https://cdn.slidesharecdn.com/ss_thumbnails/cl-oquence-cs264-110403182645-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 15a - Jacket: Visual Computing (James Malcolm, Accelereyes)](https://cdn.slidesharecdn.com/ss_thumbnails/jamesmalcomvisualcomputingcs264-110428210006-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















