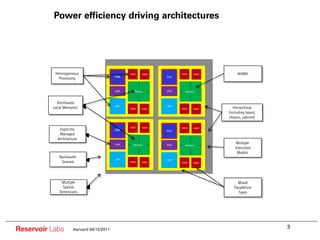
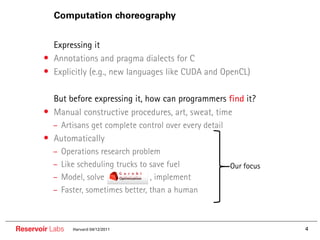
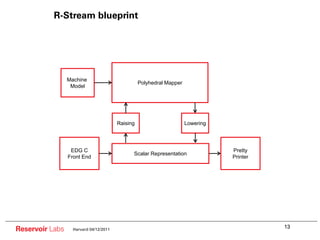
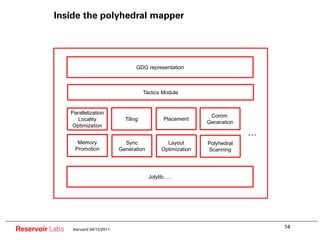
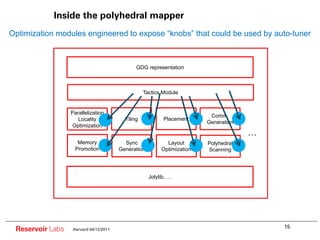
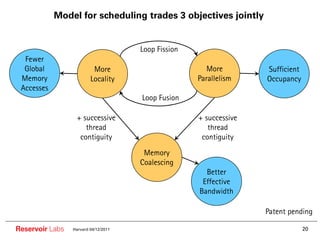
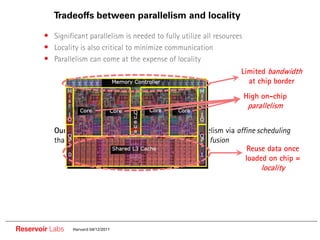
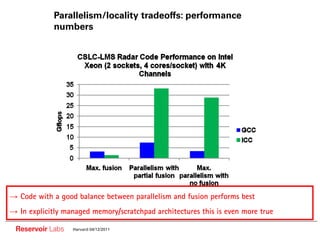
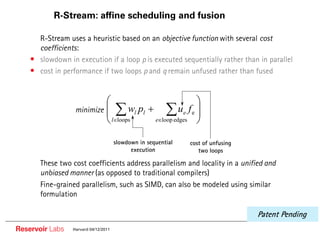
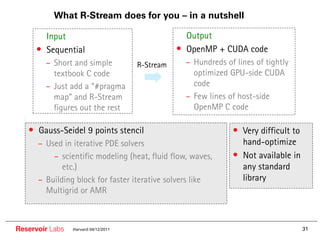
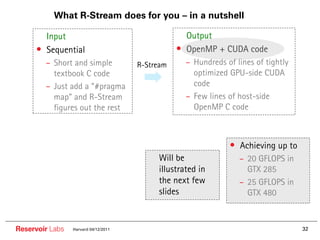
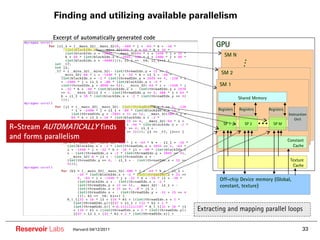
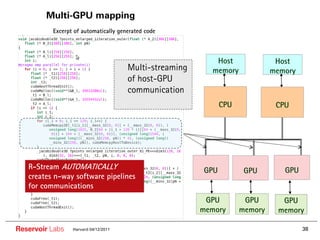
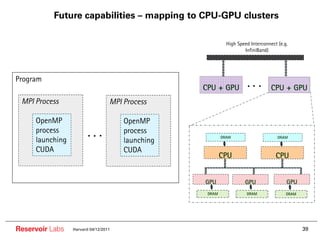
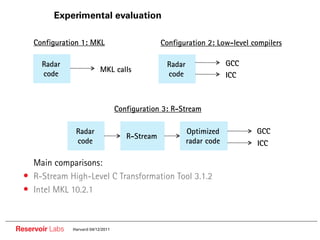
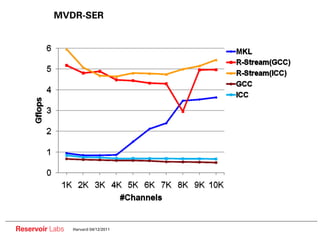
The document describes the R-Stream high-level program transformation tool. It provides an overview of R-Stream, walks through the compilation process, and discusses performance results. R-Stream uses the polyhedral model to perform program transformations like loop transformations, fusion, distribution and tiling to optimize for parallelism and locality. It models the target machine and uses this to inform the mapping of operations to resources like GPUs.



![Enabling technology is new compiler math
Uniform Recurrence Equations [Karp et al. 1970]
Many: Lamport, Allen/Kennedy,
Banerjee, Irigoin, Wolfe/Lam, Pugh, Pingali, e
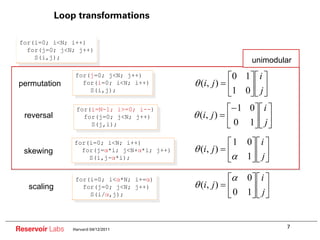
Loop Transformations and Parallelization [1970-]
Vectorization, SMP, locality optimizations
Dependence summary: direction/distance vectors
Unimodular transformations
Systolic Array Mapping Mostly linear-algebraic
Many: Feautrier, Darte, Vivien, Wilde, Rajopadhye, etc,....
Exact dependence analysis
Polyhedral Model [1980-] General affine transformations
Loop synthesis via polyhedral scanning
New computational techniques based
on polyhedral representations
Reservoir Labs Harvard 04/12/2011
9](https://image.slidesharecdn.com/reservoirlabsharvard-presentation-110412184012-phpapp02/85/Harvard-CS264-13-The-R-Stream-High-Level-Program-Transformation-Tool-Programming-GPUs-without-Writing-a-Line-of-CUDA-Nicolas-Vasilache-Reservoir-Labs-9-320.jpg)
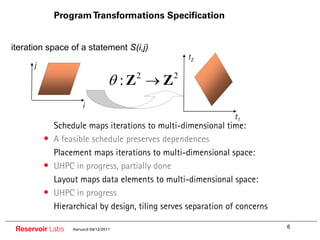
![R-Stream model: polyhedra
n = f();
for (i=5; i<= n; i+=2) {
A[i][i] = A[i][i]/B[i];
for (j=0; j<=i; j++) {
if (j<=10) {
…… A[i+2j+n][i+3]……
}
}
{i, j Z2 | k Z ,5 i n;0 j i; j i ; i 2k 1}
i
A0 1 2 1 0
j
A1 1 0 0 3 Affine and non-affine transformations
n Order and place of operations and data
1 0 0 0 1
1
Loop code represented (exactly or conservatively) with polyhedrons
High-level, mathematical view of a mapping
But targets concrete properties: parallelism, locality, memory footprint
Reservoir Labs Harvard 04/12/2011 10](https://image.slidesharecdn.com/reservoirlabsharvard-presentation-110412184012-phpapp02/85/Harvard-CS264-13-The-R-Stream-High-Level-Program-Transformation-Tool-Programming-GPUs-without-Writing-a-Line-of-CUDA-Nicolas-Vasilache-Reservoir-Labs-10-320.jpg)


![Optimization with BLAS vs. global optimization
Numerous cache misses
/* Global Optimization*/
/* Optimization with BLAS */ doall loop { Can parallelize
for loop { Outer loop(s) …… outer loop(s)
…… for loop {
Retrieve data Z from disk ……
BLAS call 1
…… Store data Z back to disk [read from Z]
Retrieve data Z from disk !!! Loop fusion
BLAS call 2 VS. ……
…… [write to Z] can
…… …… improve
BLAS call n [read from Z] locality
…… }
} ……
}
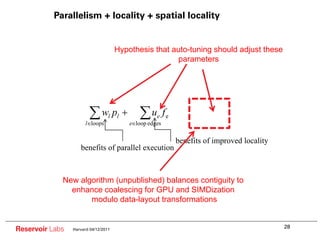
Global optimization can expose better parallelism and locality
Reservoir Labs Harvard 04/12/2011](https://image.slidesharecdn.com/reservoirlabsharvard-presentation-110412184012-phpapp02/85/Harvard-CS264-13-The-R-Stream-High-Level-Program-Transformation-Tool-Programming-GPUs-without-Writing-a-Line-of-CUDA-Nicolas-Vasilache-Reservoir-Labs-21-320.jpg)
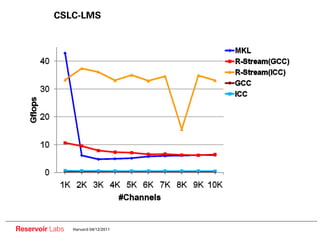
![Parallelism/locality tradeoff example
Array z gets expanded, to
Maximum distribution destroys locality
introduce another level of
parallelism
/* doall (i=0; i<400; i++)
* Original code: doall (j=0; j<3997; j++)
* Simplified CSLC LMS z_e[j][i]=0
*/ doall (i=0; i<400; i++)
for (k=0; k<400; k++) { doall (j=0; j<3997; j++)
Max. parallelism
for (i=0; i<3997; i++) { for (k=0; k<4000; k++)
(no fusion)
z[i]=0; z_e[j][i]=z_e[j][i]+B[j][k]*x[i][k];
for (j=0; j<4000; j++) doall (i=0; i<3997; i++)
z[i]= z[i]+B[i][j]*x[k][j]; for (j=0; j<400; j++)
} w[i]=w[i]+z_e[i][j];
for (i=0; i<3997; i++) doall (i=0; i<3997; i++)
w[i]=w[i]+z[i]; Data
z[i] = z_e[i][399];
} accumulation
2 levels of parallelism, but poor data reuse (on array z_e)
Reservoir Labs Harvard 04/12/2011](https://image.slidesharecdn.com/reservoirlabsharvard-presentation-110412184012-phpapp02/85/Harvard-CS264-13-The-R-Stream-High-Level-Program-Transformation-Tool-Programming-GPUs-without-Writing-a-Line-of-CUDA-Nicolas-Vasilache-Reservoir-Labs-23-320.jpg)
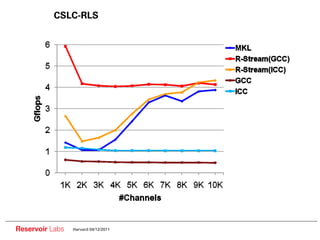
![Parallelism/locality tradeoff example (cont.)
Aggressive loop fusion destroys
parallelism (i.e., only 1 degree
/*
of parallelism)
* Original code:
* Simplified CSLC LMS
*/ doall (i=0; i<3997; i++)
for (k=0; k<400; k++) { for (j=0; j<400; j++) {
for (i=0; i<3997; i++) {
Max. fusion z[i]=0;
z[i]=0; for (k=0; k<4000; k++)
for (j=0; j<4000; j++) z[i]=z[i]+B[i][k]*x[j][k];
z[i]= z[i]+B[i][j]*x[k][j]; w[i]=w[i]+z[i];
} }
for (i=0; i<3997; i++)
w[i]=w[i]+z[i];
}
Very good data reuse (on array z), but only 1 level of parallelism
Reservoir Labs Harvard 04/12/2011](https://image.slidesharecdn.com/reservoirlabsharvard-presentation-110412184012-phpapp02/85/Harvard-CS264-13-The-R-Stream-High-Level-Program-Transformation-Tool-Programming-GPUs-without-Writing-a-Line-of-CUDA-Nicolas-Vasilache-Reservoir-Labs-24-320.jpg)
![Parallelism/locality tradeoff example (cont.)
Partial fusion doesn’t
Expansion of array z decrease parallelism
/*
* Original code: doall (i=0; i<3997; i++) {
* Simplified CSLC LMS doall (j=0; j<400; j++) {
*/ z_e[i][j]=0;
for (k=0; k<400; k++) { for (k=0; k<4000; k++)
z_e[i][j]=z_e[i][j]+B[i][k]*x[j][k];
for (i=0; i<3997; i++) { Parallelism with
}
z[i]=0; partial fusion
for (j=0; j<4000; j++) for (j=0; j<400; j++)
z[i]= z[i]+B[i][j]*x[k][j]; w[i]=w[i]+z_e[i][j];
} }
doall (i=0; i<3997; i++)
for (i=0; i<3997; i++) Data
z[i]=z_e[i][399];
w[i]=w[i]+z[i]; accumulation
}
2 levels of parallelism with good data reuse (on array z_e)
Reservoir Labs Harvard 04/12/2011](https://image.slidesharecdn.com/reservoirlabsharvard-presentation-110412184012-phpapp02/85/Harvard-CS264-13-The-R-Stream-High-Level-Program-Transformation-Tool-Programming-GPUs-without-Writing-a-Line-of-CUDA-Nicolas-Vasilache-Reservoir-Labs-25-320.jpg)





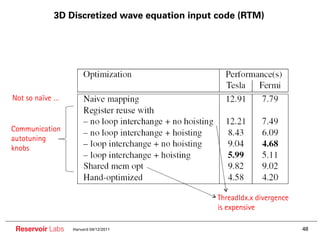
![3D Discretized wave equation input code (RTM)
•• #pragma rstream map
•• void RTM_3D(double (*U1)[Y][X], double (*U2)[Y][X], double (*V)[Y][X],
•• int pX, int pY, int pZ) {
•• double temp;
•• int i, j, k;
•• for (k=4; k<pZ-4; k++) {
•• for (j=4; j<pY-4; j++) {
•• for (i=4; i<pX-4; i++) {
•• temp = C0 * U2[k][j][i] +
•• C1 * (U2[k-1][j][i] + U2[k+1][j][i] +
•• U2[k][j-1][i] + U2[k][j+1][i] +
•• U2[k][j][i-1] + U2[k][j][i+1]) +
•• C2 * (U2[k-2][j][i] + U2[k+2][j][i] +
•• U2[k][j-2][i] + U2[k][j+2][i] + 25-point 8th
•• U2[k][j][i-2] + U2[k][j][i+2]) + order (in space)
•• C3 * (U2[k-3][j][i] + U2[k+3][j][i] +
•• U2[k][j-3][i] + U2[k][j+3][i] +
stencil
•• U2[k][j][i-3] + U2[k][j][i+3]) +
•• C4 * (U2[k-4][j][i] + U2[k+4][j][i] +
•• U2[k][j-4][i] + U2[k][j+4][i] +
•• U2[k][j][i-4] + U2[k][j][i+4]);
•• U1[k][j][i] =
•• 2.0f * U2[k][j][i] - U1[k][j][i] +
•• V[k][j][i] * temp;
•• } } } }
Reservoir Labs Harvard 04/12/2011 47](https://image.slidesharecdn.com/reservoirlabsharvard-presentation-110412184012-phpapp02/85/Harvard-CS264-13-The-R-Stream-High-Level-Program-Transformation-Tool-Programming-GPUs-without-Writing-a-Line-of-CUDA-Nicolas-Vasilache-Reservoir-Labs-47-320.jpg)




















![Cascading[1]](https://cdn.slidesharecdn.com/ss_thumbnails/cascading1-100122135856-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Harvard CS264] 15a - Jacket: Visual Computing (James Malcolm, Accelereyes)](https://cdn.slidesharecdn.com/ss_thumbnails/jamesmalcomvisualcomputingcs264-110428210006-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 15a - The Onset of Parallelism, Changes in Computer Architect...](https://cdn.slidesharecdn.com/ss_thumbnails/drich110413cs264-110428210736-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 10b - cl.oquence: High-Level Language Abstractions for Low-Le...](https://cdn.slidesharecdn.com/ss_thumbnails/cl-oquence-cs264-110403182645-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 16 - Managing Dynamic Parallelism on GPUs: A Case Study of Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/managingdynamicparallelism-110430142356-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 14 - Dynamic Compilation for Massively Parallel Processors (G...](https://cdn.slidesharecdn.com/ss_thumbnails/gregdiamoscs264lecture-110417212416-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 08a - Cloud Computing, Amazon EC2, MIT StarCluster (Justin Ri...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264-intro-to-cloud-computing-110322172806-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 12 - Irregular Parallelism on the GPU: Algorithms and Data St...](https://cdn.slidesharecdn.com/ss_thumbnails/owens-harvard-110407-110407230512-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Harvard CS264] 11b - Analysis-Driven Performance Optimization with CUDA (Cli...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407230024-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11a - Programming the Memory Hierarchy with Sequoia (Mike Bau...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407225811-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 10a - Easy, Effective, Efficient: GPU Programming in Python w...](https://cdn.slidesharecdn.com/ss_thumbnails/andreas-cs264-110331202547-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 09 - Machine Learning on Big Data: Lessons Learned from Googl...](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Harvard CS264] 02 - Parallel Thinking, Architecture, Theory & Patterns](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201102-archtheorypatternshare-110206154047-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Harvard CS264] 06 - CUDA Ninja Tricks: GPU Scripting, Meta-programming & Aut...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201106-cudaninjasharetmp-110301171948-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 05 - Advanced-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 04 - Intermediate-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201104-cudaintermediatesharetmpopt-110215180915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 01 - Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201101-introductionshare-110206153841-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




























