Downloaded 189 times


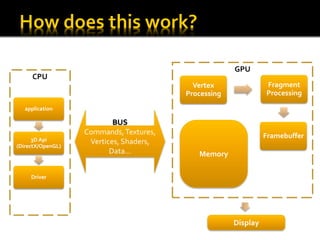


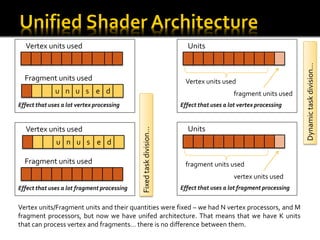
















The document outlines an overview of GPU architecture and processing techniques, emphasizing the evolution from fixed vertex and fragment units to unified architectures that allow flexible processing. It discusses various computing models such as SISD, SIMD, and MIMD, and highlights the potential of GPUs for general-purpose computing across diverse fields including physics, financial modeling, and AI. Additionally, it provides optimization tips for programming on GPUs and references tools for debugging and performance analysis.
















































![Empty Base Class Optimisation, [[no_unique_address]] and other C++20 Attributes](https://cdn.slidesharecdn.com/ss_thumbnails/emptybaseattributespublic-200727061030-thumbnail.jpg?width=640&height=640&fit=bounds)


























