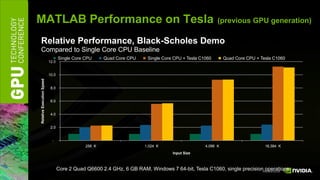
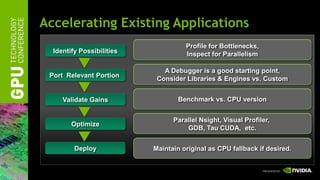
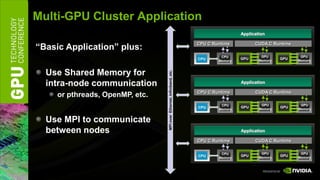
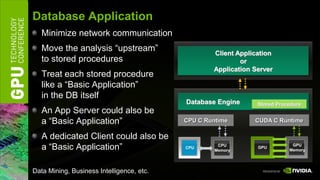
The document discusses GPU computing software and development tools from NVIDIA. It provides an overview of language and API options for GPU computing like CUDA, OpenCL, and DirectCompute. It also describes development tools like the CUDA toolkit, Parallel Nsight debugger, and Visual Profiler for optimizing GPU applications. Foundation libraries and common design patterns are also covered to help developers leverage GPUs effectively.










![Example: Implicit Parallel Languages
PGI Accelerator Compilers
SUBROUTINE SAXPY (A,X,Y,N) compile
INTEGER N
REAL A,X(N),Y(N)
!$ACC REGION
DO I = 1, N Host x64 asm File Auto-generated GPU code
X(I) = A*X(I) + Y(I)
saxpy_: typedef struct dim3{ unsigned int x,y,z; }dim3;
ENDDO … typedef struct uint3{ unsigned int x,y,z; }uint3;
!$ACC END REGION movl (%rbx), %eax extern uint3 const threadIdx, blockIdx;
END movl %eax, -4(%rbp) extern dim3 const blockDim, gridDim;
call __pgi_cu_init static __attribute__((__global__)) void
pgicuda(
. . .
link
call
…
call
__pgi_cu_function
__pgi_cu_alloc
+ __attribute__((__shared__)) int tc,
__attribute__((__shared__)) int i1,
__attribute__((__shared__)) int i2,
__attribute__((__shared__)) int _n,
… __attribute__((__shared__)) float* _c,
__attribute__((__shared__)) float* _b,
call __pgi_cu_upload
__attribute__((__shared__)) float* _a )
… { int i; int p1; int _i;
call __pgi_cu_call i = blockIdx.x * 64 + threadIdx.x;
if( i < tc ){
…
_a[i+i2-1] = ((_c[i+i2-1]+_c[i+i2-1])+_b[i+i2-1]);
call __pgi_cu_download
_b[i+i2-1] = _c[i+i2];
… _i = (_i+1);
p1 = (p1-1);
Unified } }
a.out
… no change to existing makefiles, scripts, IDEs,
execute
programming environment, etc.](https://image.slidesharecdn.com/01gpuapimillerlanguagestools-110106231409-phpapp01/85/01-gpu-api-miller-languages-tools-11-320.jpg)

![Example: Language Integration
CUDA C: C with a few keywords
void saxpy_serial(int n, float a, float *x, float *y)
{
for (int i = 0; i < n; ++i)
y[i] = a*x[i] + y[i];
}
Standard C Code
// Invoke serial SAXPY kernel
saxpy_serial(n, 2.0, x, y);
__global__ void saxpy_parallel(int n, float a, float *x, float *y)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i]; CUDA C Code
}
// Invoke parallel SAXPY kernel with 256 threads/block
int nblocks = (n + 255) / 256;
saxpy_parallel<<<nblocks, 256>>>(n, 2.0, x, y);](https://image.slidesharecdn.com/01gpuapimillerlanguagestools-110106231409-phpapp01/85/01-gpu-api-miller-languages-tools-13-320.jpg)


















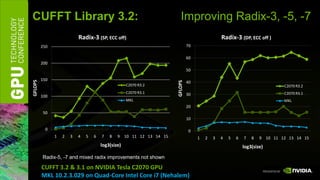
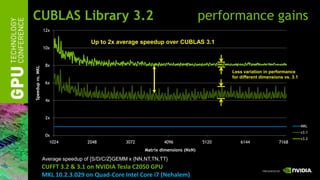





























































![[05][cuda 및 fermi 최적화 기술] hryu optimization](https://cdn.slidesharecdn.com/ss_thumbnails/05cudafermihryuoptimization-110106231451-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








![[03 2][gpu용 개발자 도구 - parallel nsight 및 axe] gateau parallel-nsight](https://cdn.slidesharecdn.com/ss_thumbnails/03-2gpu-parallelnsightaxegateauparallelnsight-110106231414-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









