Downloaded 22 times






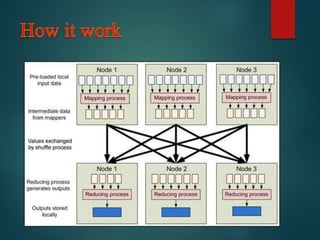



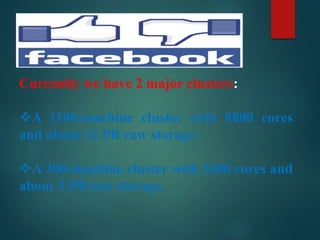


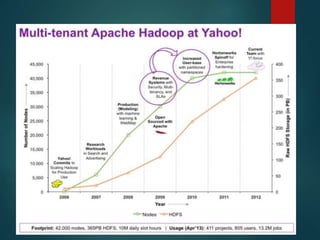






This document discusses Hadoop, an open-source software framework for distributed storage and processing of large datasets across clusters of computers. It describes key Hadoop components like HDFS for distributed file storage and MapReduce for distributed processing. Several companies that use Hadoop at large scale are mentioned, including Yahoo, Amazon and Facebook. Applications of Hadoop in healthcare for storing and analyzing large amounts of medical data are discussed. The document concludes that Hadoop is well-suited for big data applications due to its scalability, fault tolerance and cost effectiveness.