Download to read offline





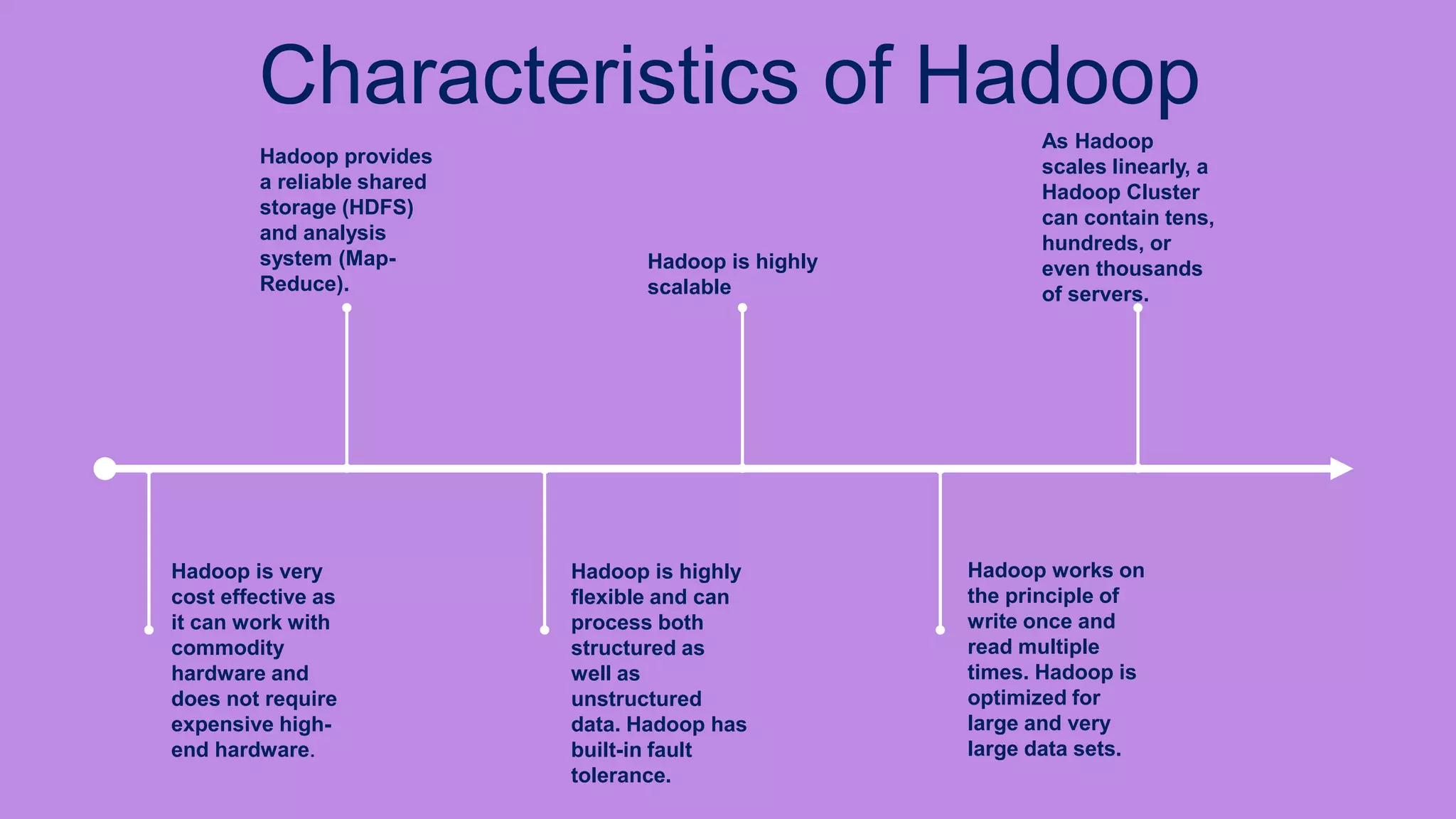
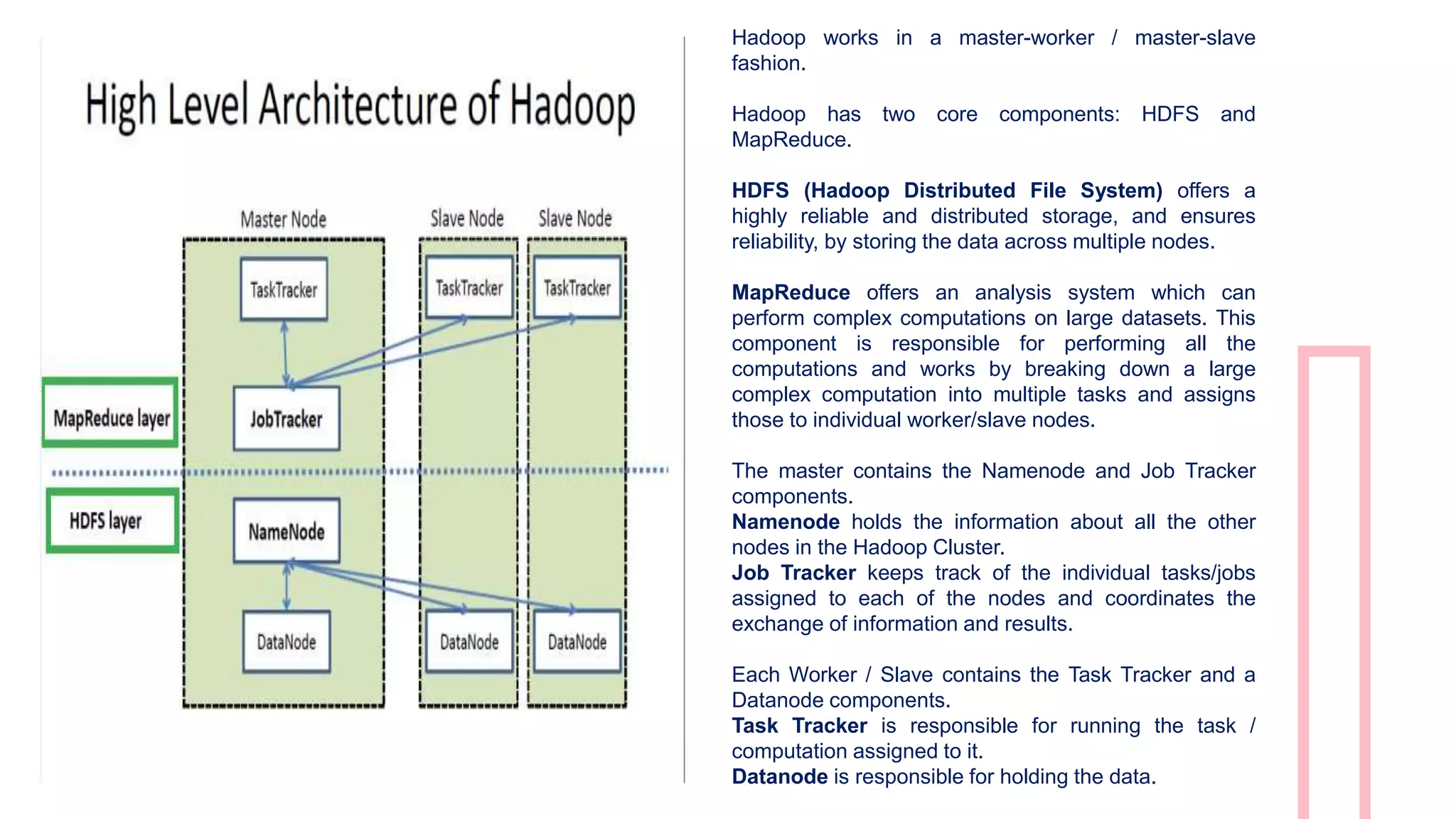
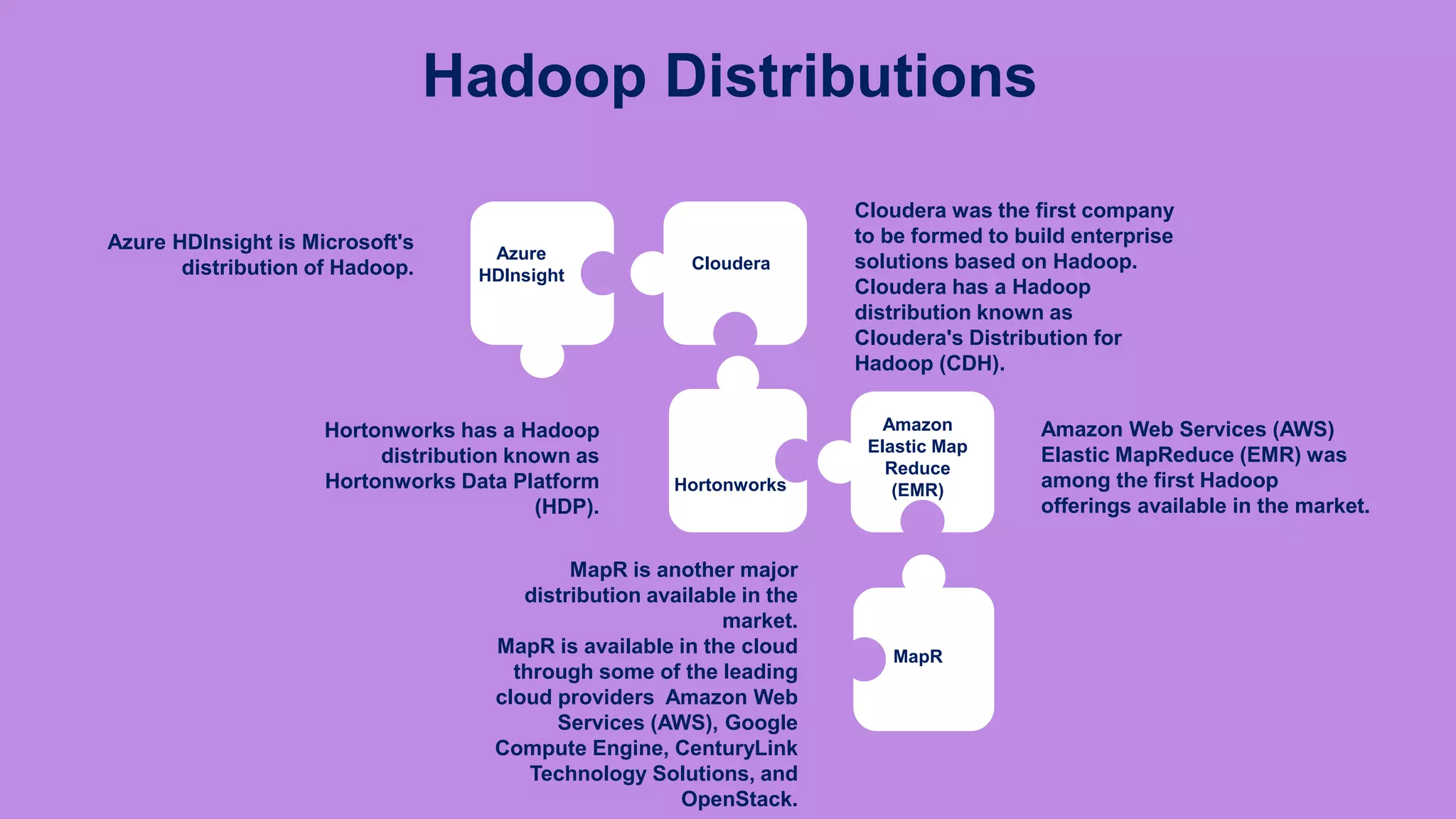



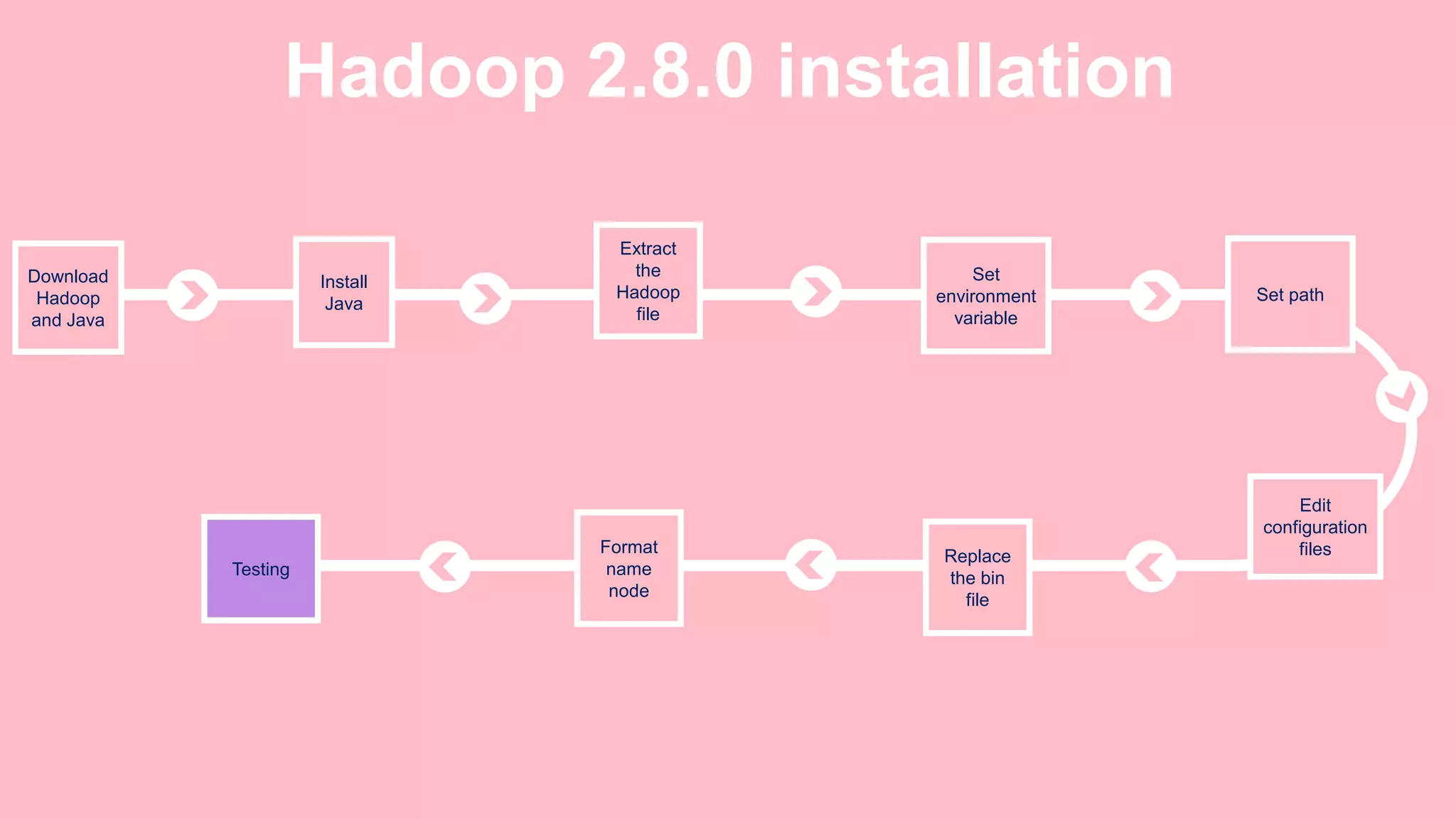
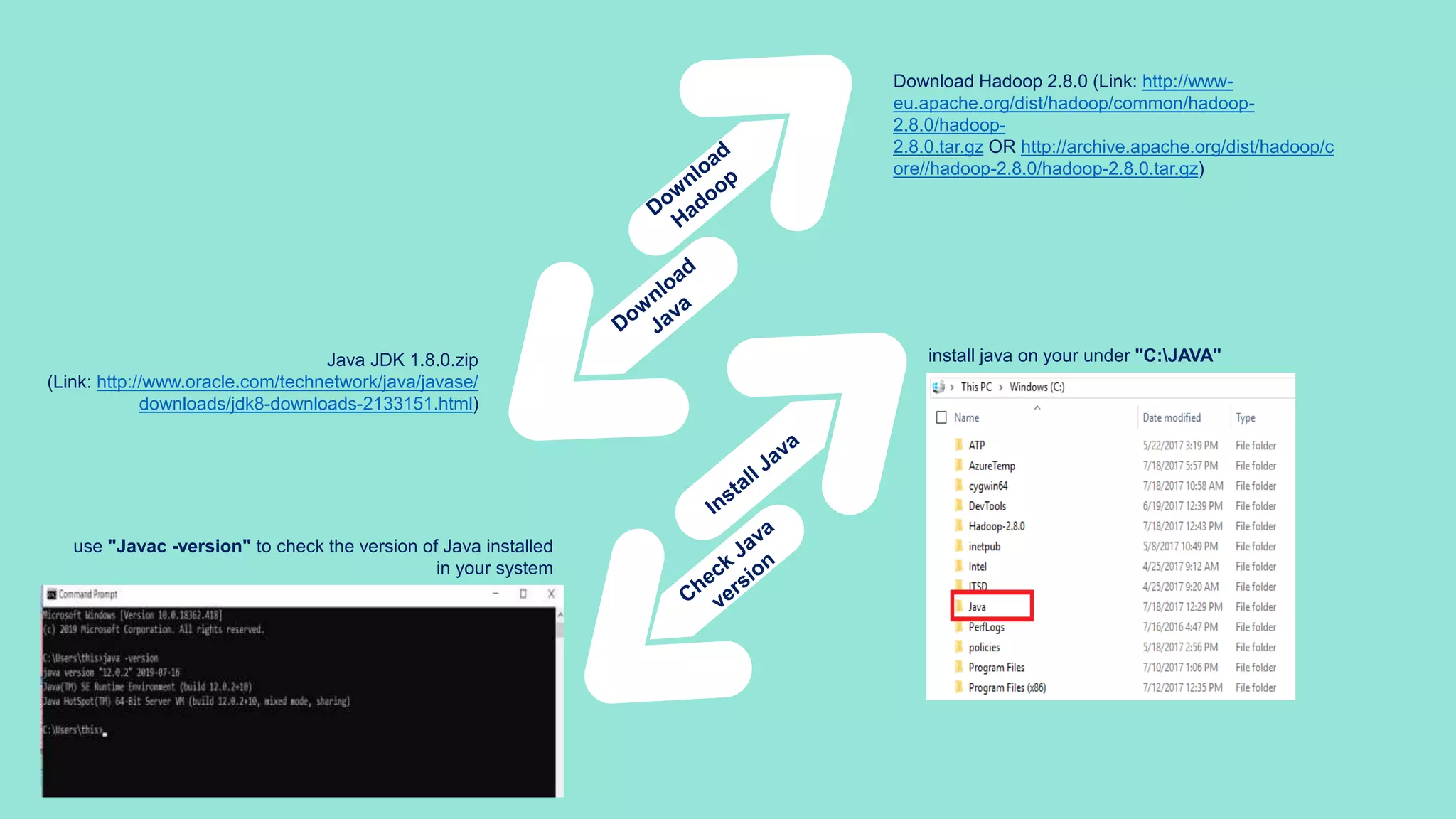



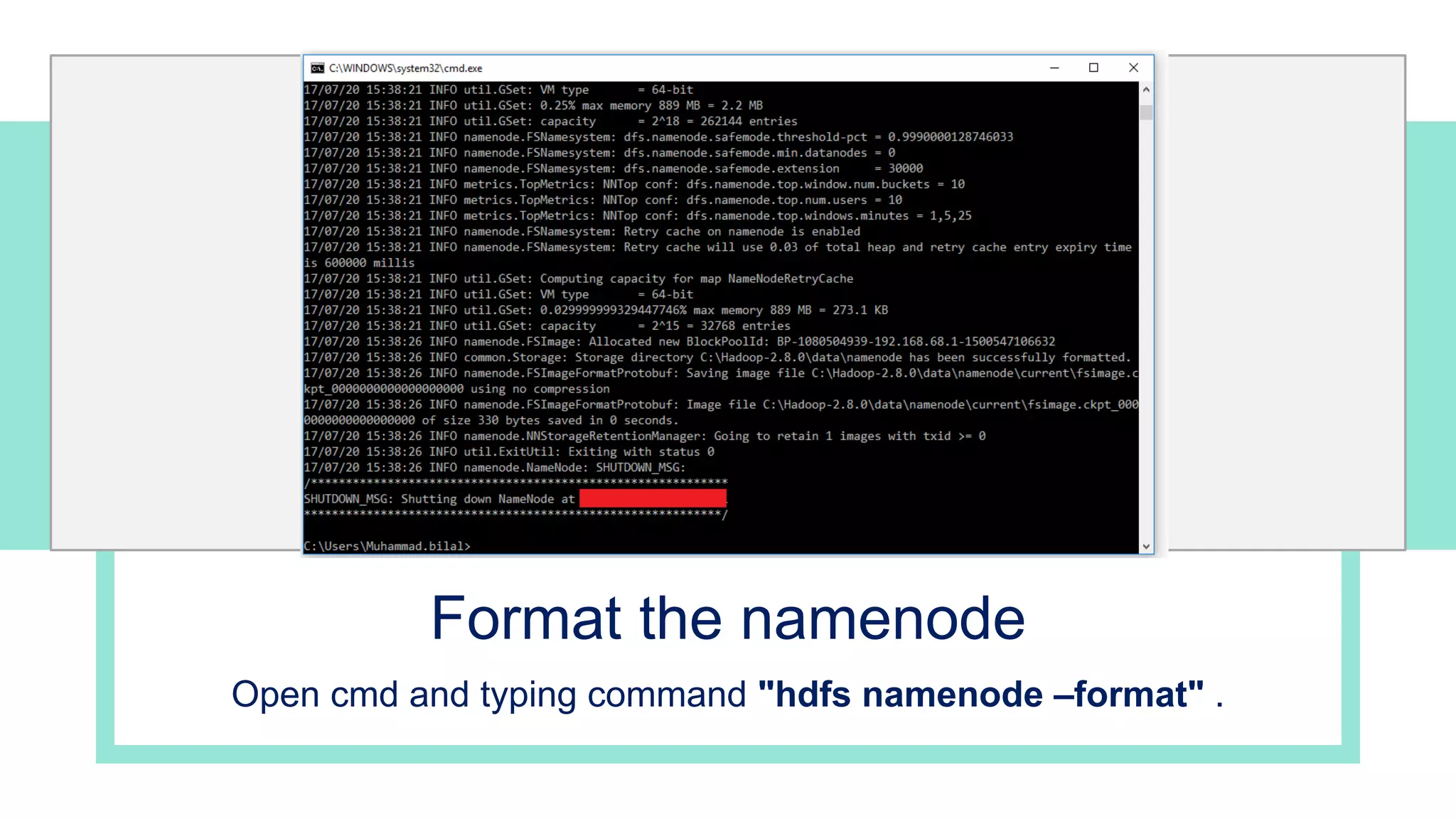
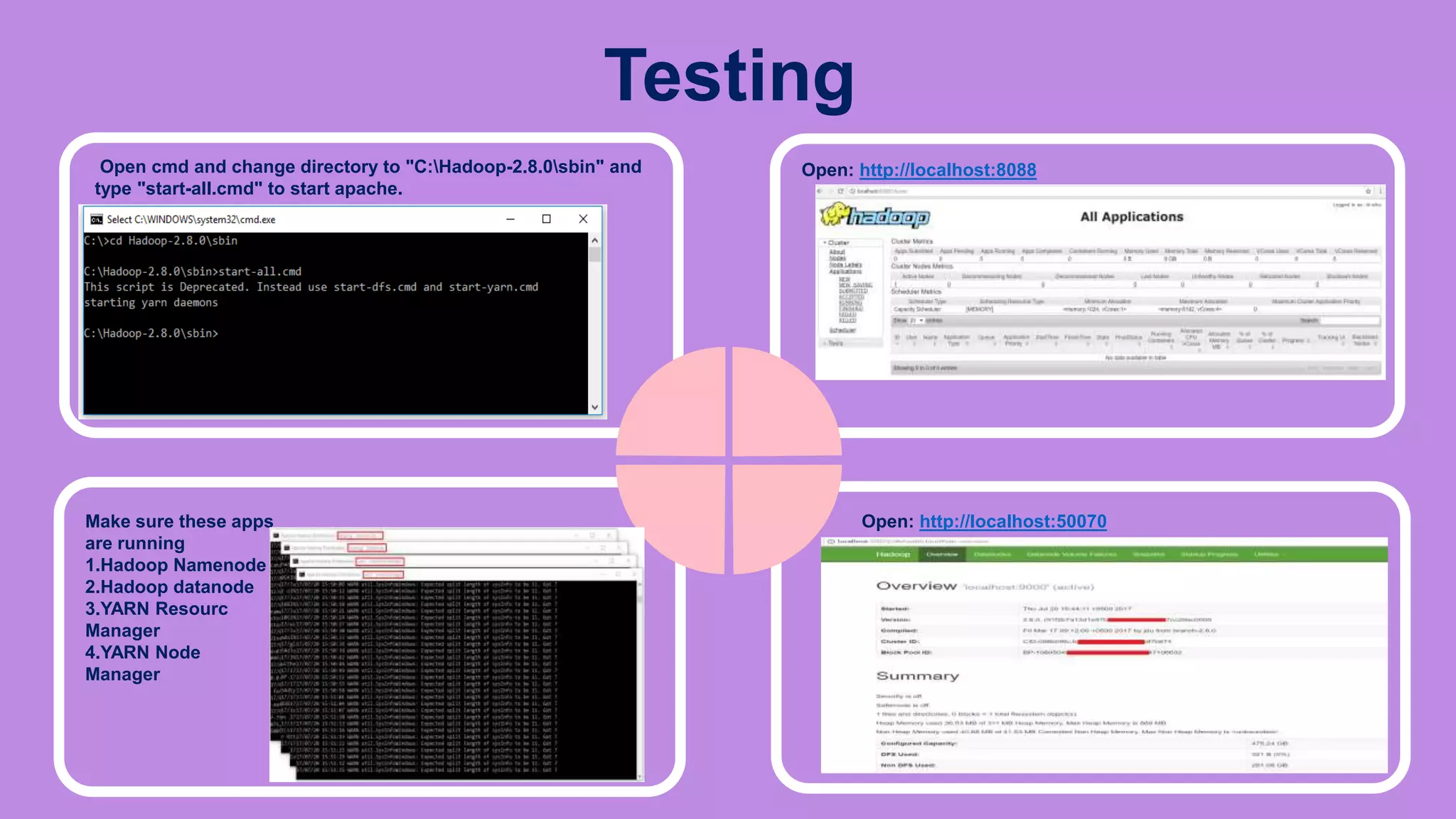
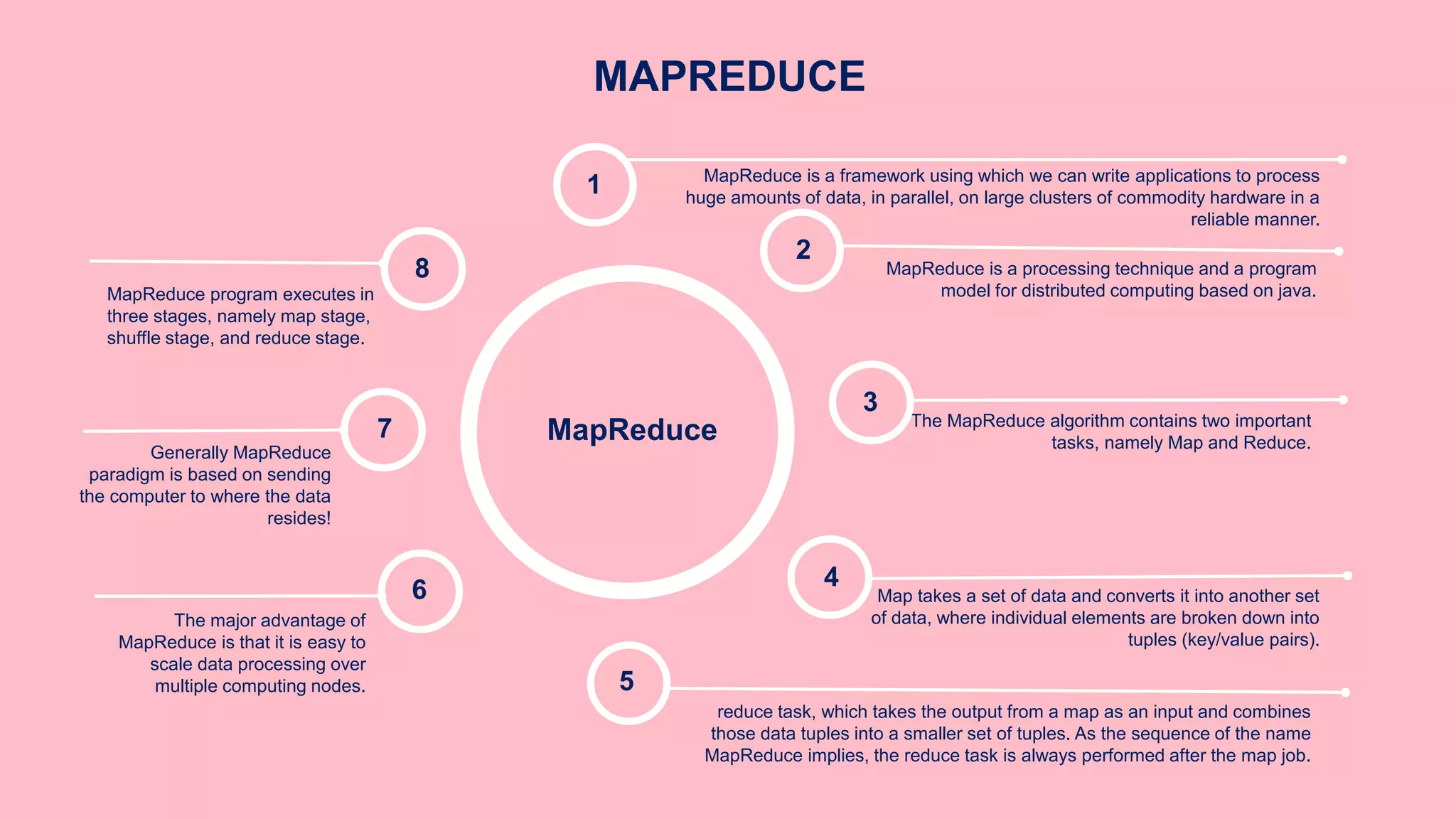



The document is a presentation on big data and Hadoop, highlighting the challenges of processing vast data sets and introducing Hadoop as an open-source framework for distributed data processing. It outlines the characteristics of big data, including volume, velocity, and variety, and details Hadoop's components like HDFS for storage and MapReduce for data analysis. The document also covers installation instructions, various Hadoop distributions, and key ecosystem tools within the Hadoop framework.


































































