Downloaded 103 times



![Who am I?
• Wisely Chen ( thegiive@gmail.com )
• Sr. Engineer in Yahoo![Taiwan] data team
• Loves to promote open source tech
• Hadoop Summit 2013 San Jose
• Jenkins Conf 2013 Palo Alto
• Spark Summit 2014 San Francisco
• Coscup 2006, 2012, 2013 , OSDC 2007, Webconf 2013,
Coscup 2012, PHPConf 2012 , RubyConf 2012](https://image.slidesharecdn.com/introductiontospark-140925212638-phpapp02/85/OCF-tw-s-talk-about-Introduction-to-spark-3-320.jpg)



















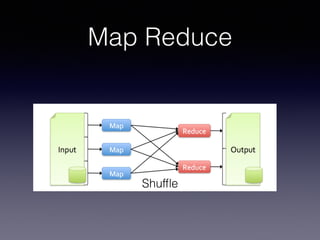
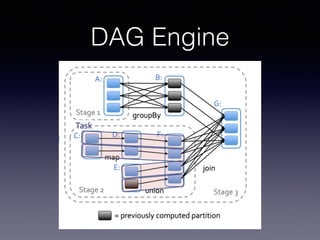
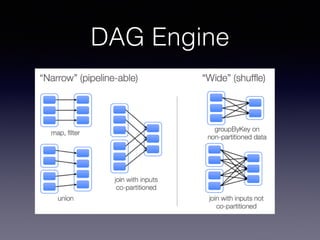


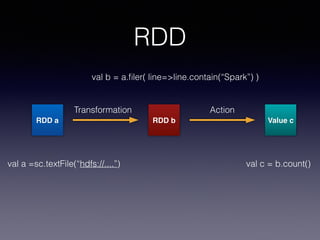
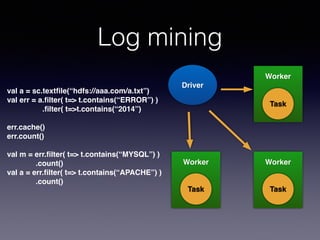
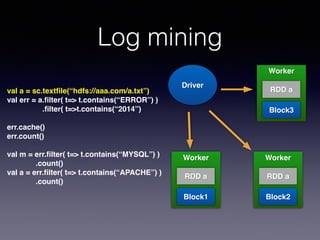
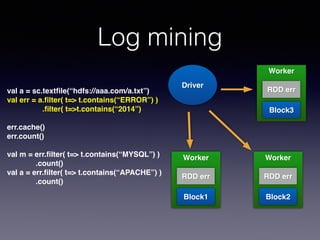
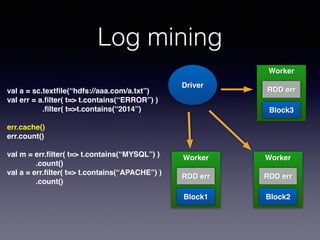
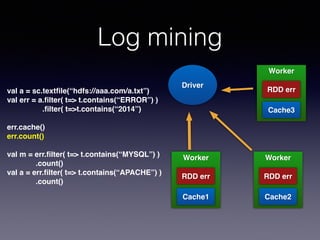
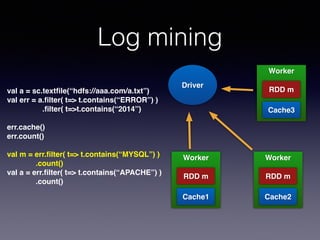
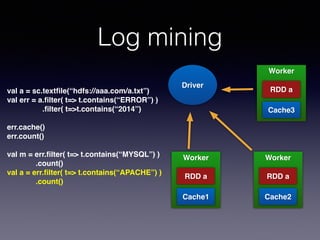















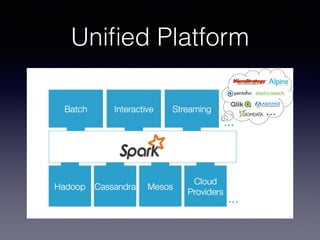
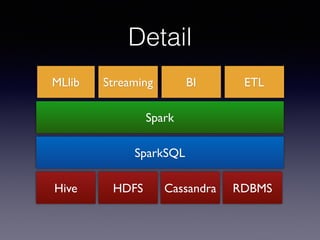
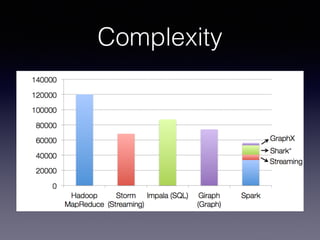
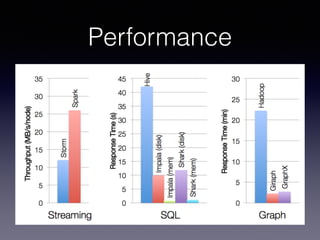

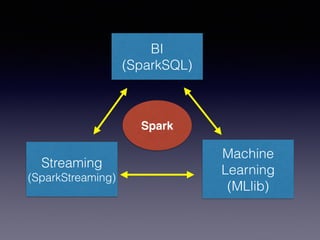

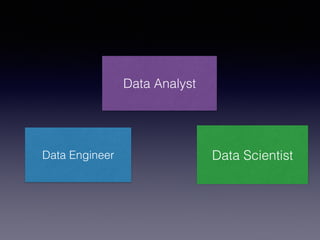

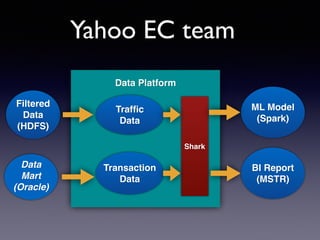



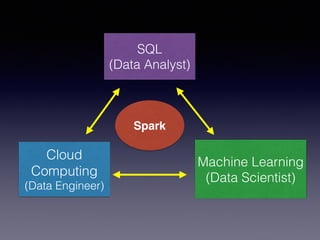

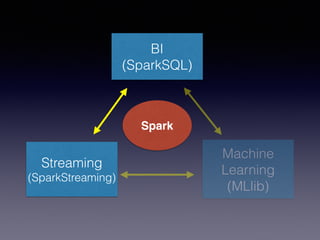

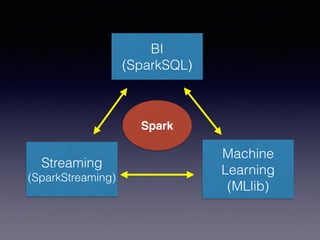





The document is a presentation by Wisely Chen, a Senior Engineer at Yahoo, introducing Apache Spark, a fast engine for large-scale data processing that is seen as the successor to MapReduce. It covers the Spark ecosystem, its advantages over Hadoop, and provides examples of using Spark with Python, Java, and Scala for data processing tasks. The presentation also highlights Spark's real-time analytics capabilities, machine learning applications, and the future of data processing frameworks.















































![[@NaukriEngineering] Apache Spark](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkppt-170105054406-thumbnail.jpg?width=640&height=640&fit=bounds)


























