Downloaded 46 times










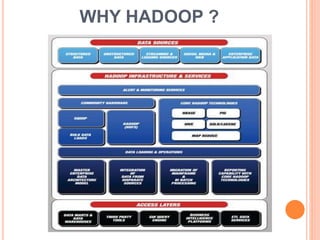


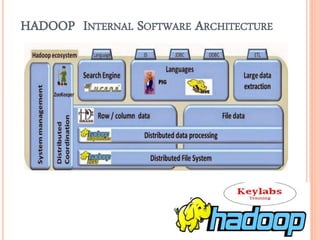


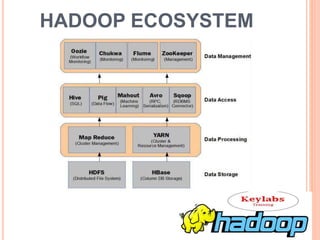














Hadoop is an open-source software framework initially created by Doug Cutting, designed for data-intensive distributed applications and built on concepts from Google’s MapReduce system. Organizations like Yahoo and Facebook utilize Hadoop for large-scale data processing, leveraging its ability to efficiently handle diverse data formats and perform batch processing quickly. The framework includes key components such as HDFS for storage and MapReduce for job management, making it a scalable, cost-effective, and fault-tolerant solution for data management.























































































