Downloaded 49 times


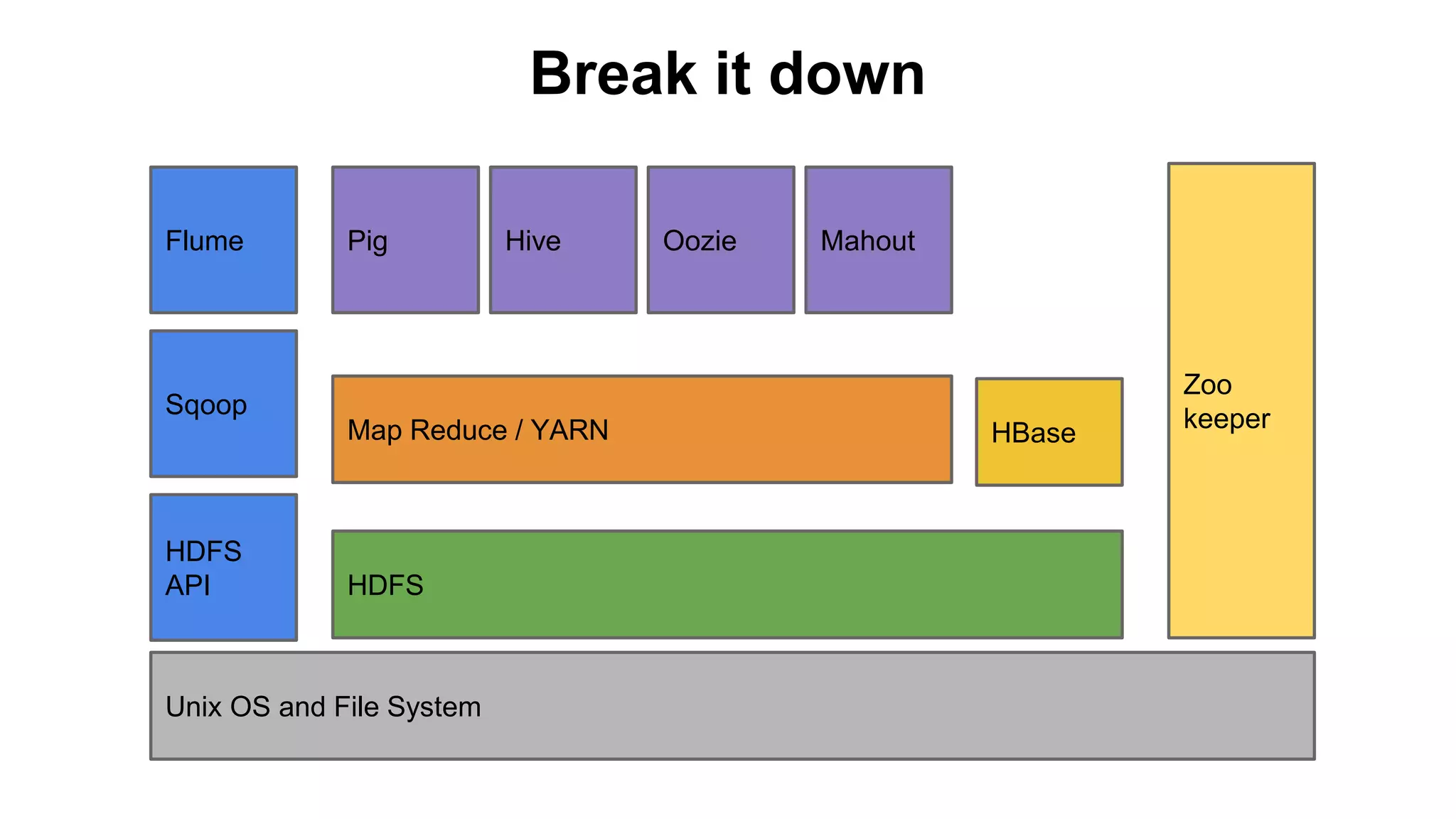


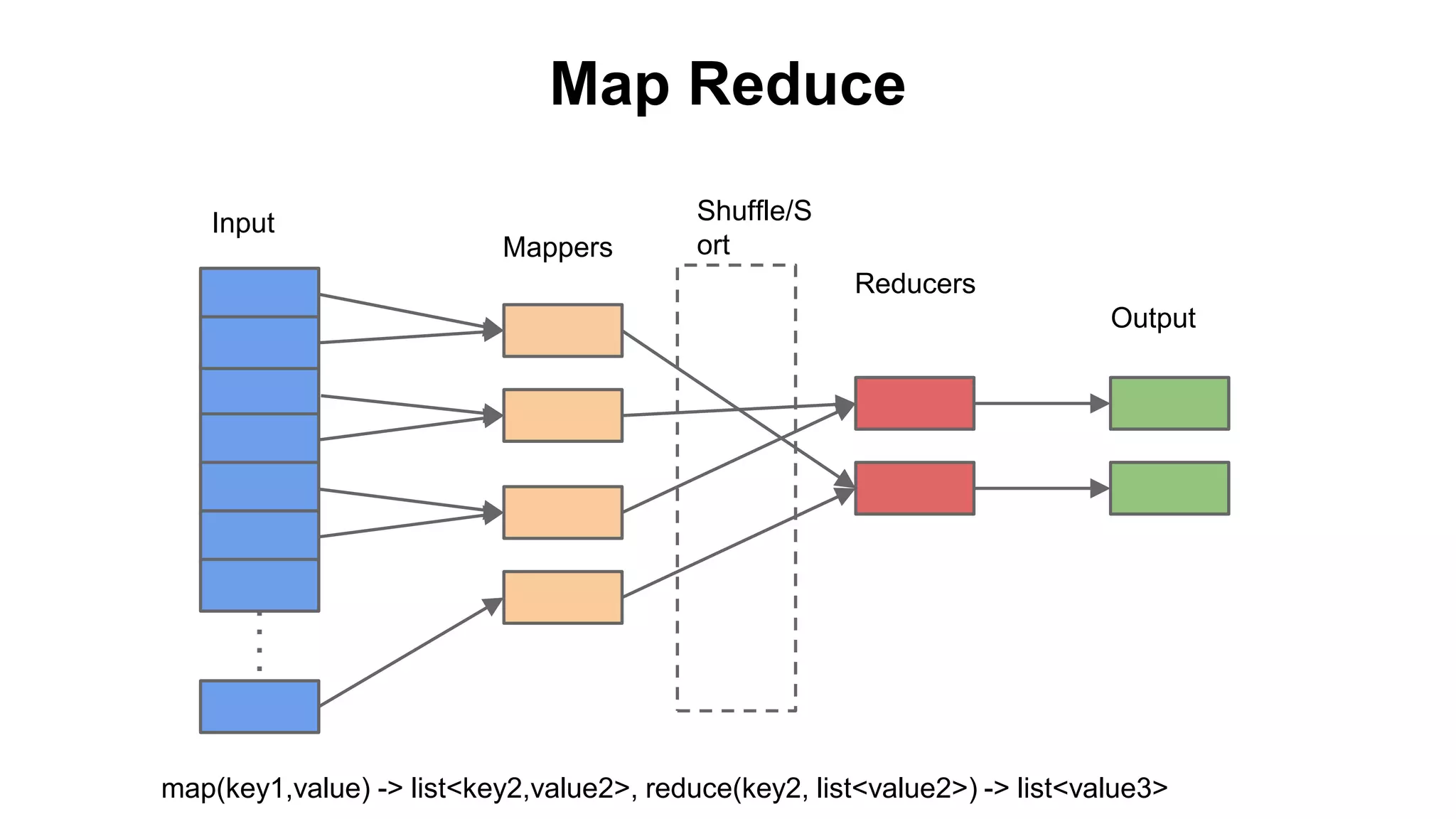
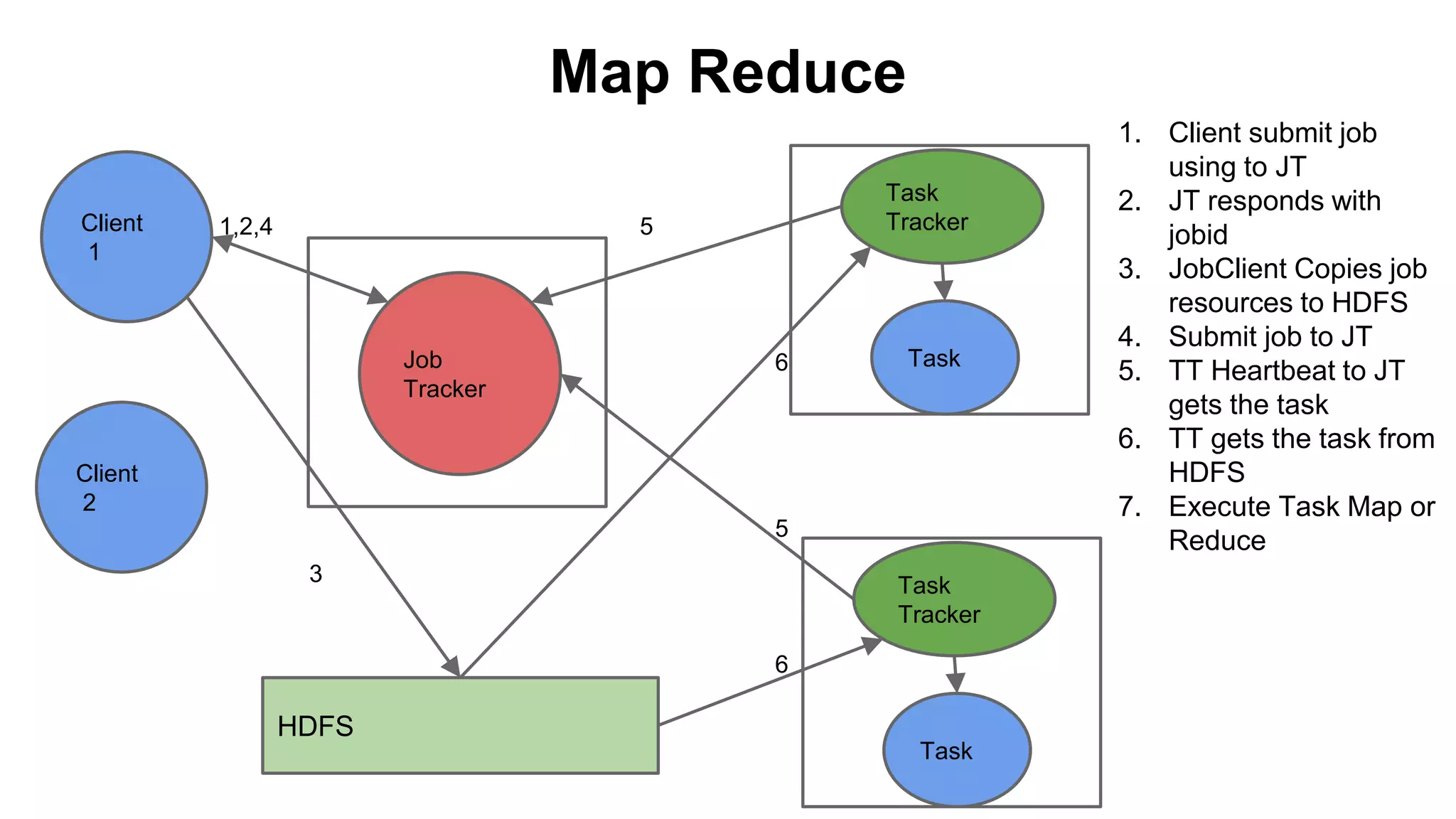
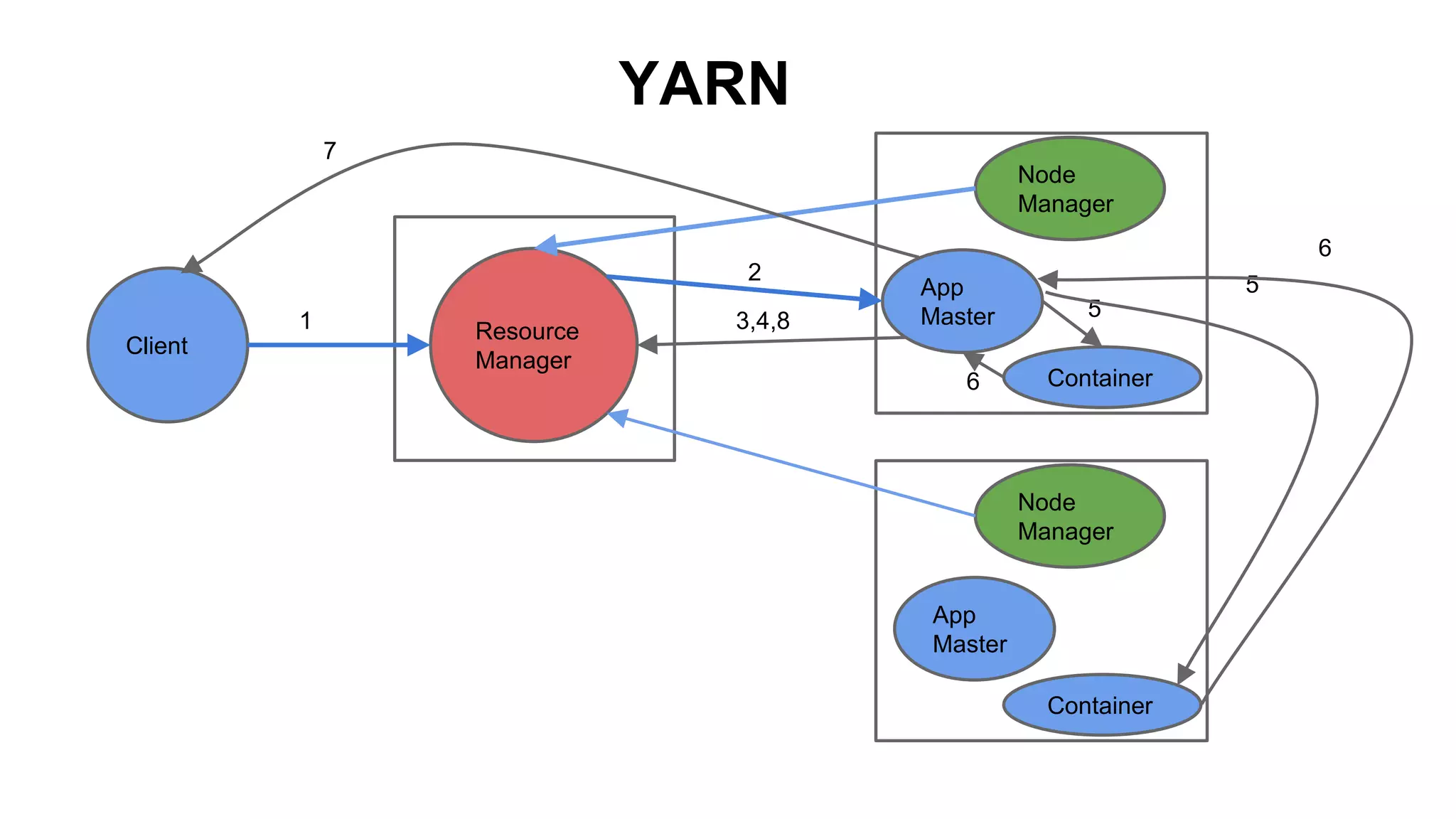

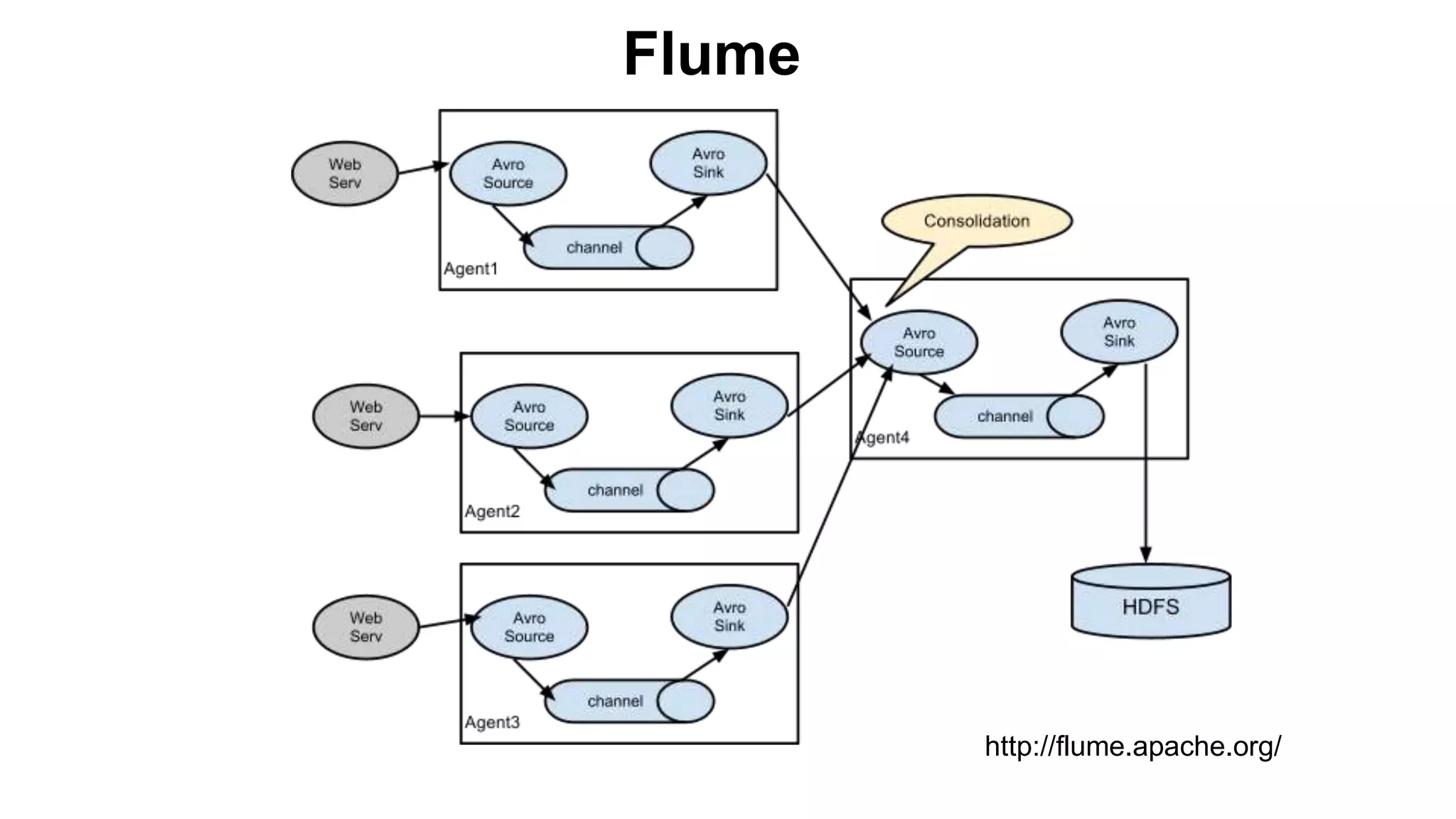

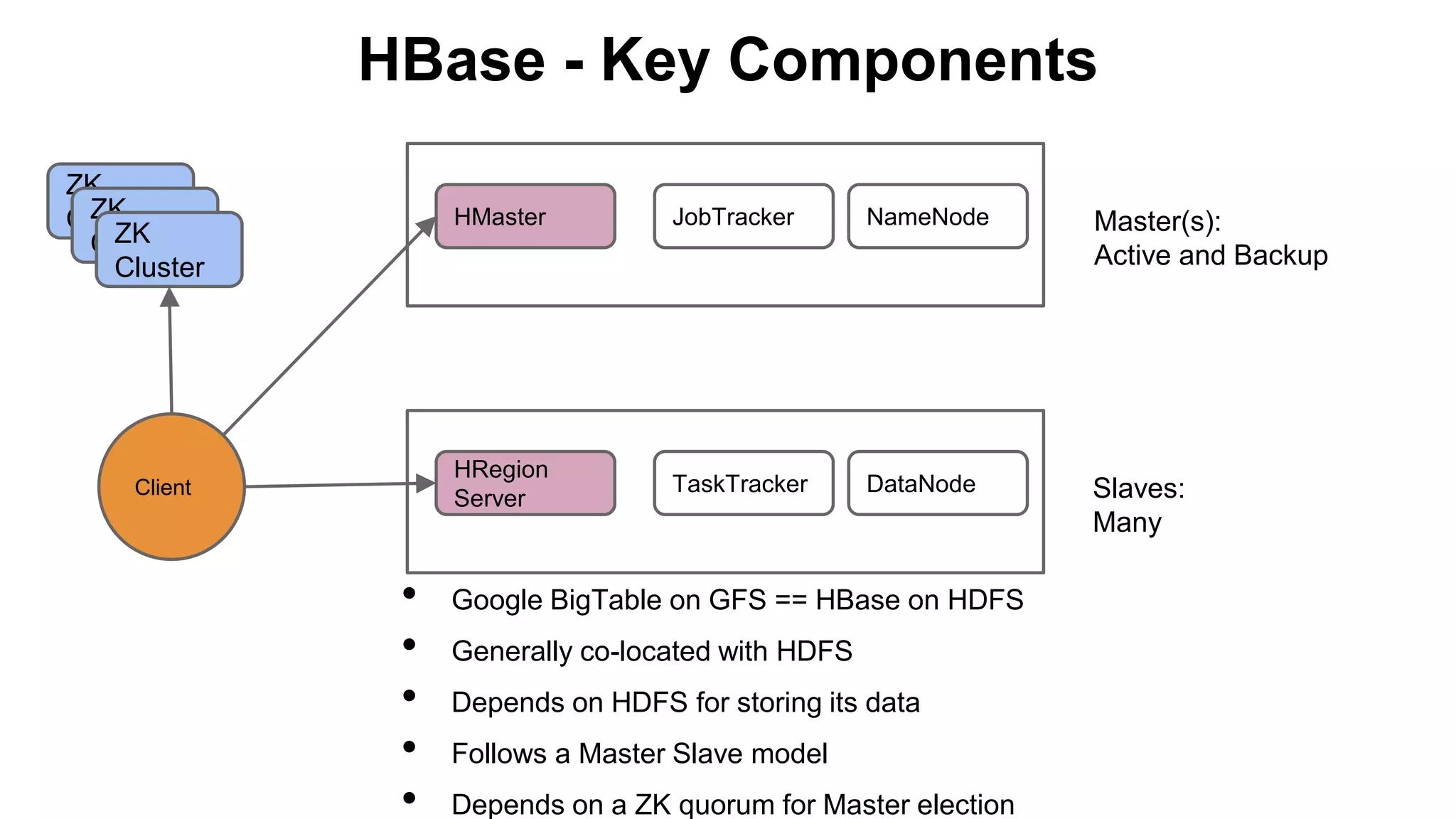






The document provides a basic introduction to the Hadoop ecosystem. It describes the key components which include HDFS for raw storage, HBase for columnar storage, Hive and Pig as query engines, MapReduce and YARN as schedulers, Flume for streaming, Mahout for machine learning, Oozie for workflows, and Zookeeper for distributed locking. Each component is briefly explained including their goals, architecture, and how they relate to and build upon each other.























































































