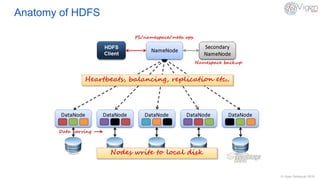
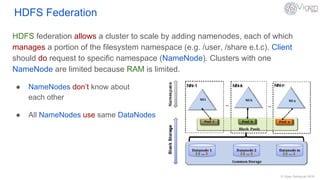
HDFS (Hadoop Distributed File System) is a distributed file system that stores large data sets across clusters of machines. It partitions and stores data in blocks across nodes, with multiple replicas of each block for fault tolerance. HDFS uses a master/slave architecture with a NameNode that manages metadata and DataNodes that store data blocks. The NameNode and DataNodes work together to ensure high availability and reliability even when hardware failures occur. HDFS supports large data sets through horizontal scaling and tools like HDFS Federation that allow scaling the namespace across multiple NameNodes.