

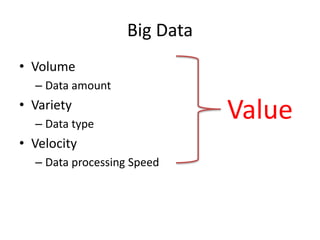


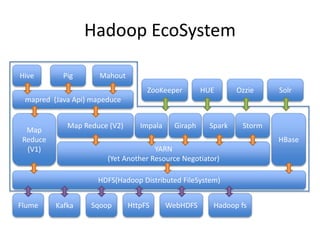
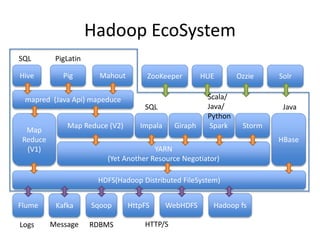
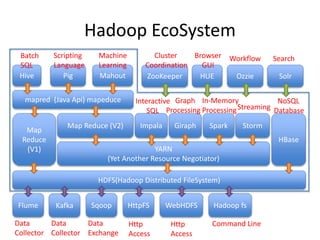
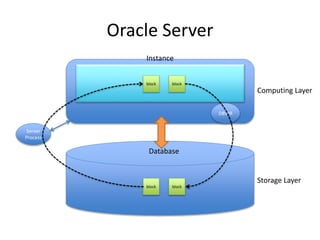
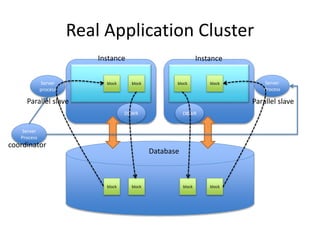

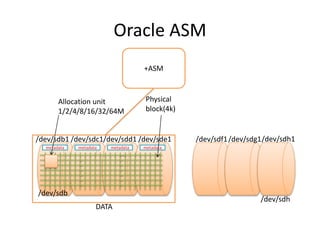
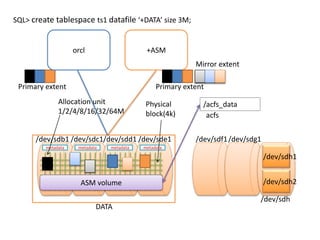
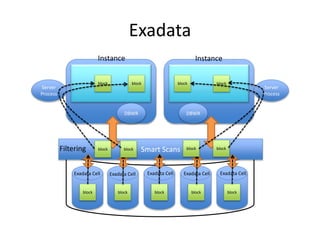


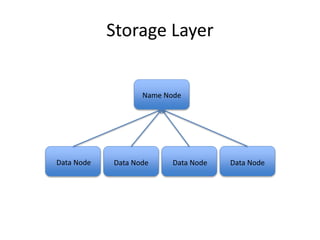
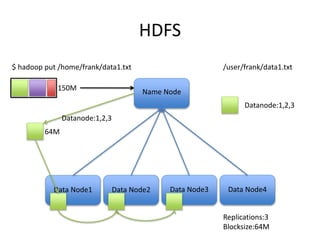
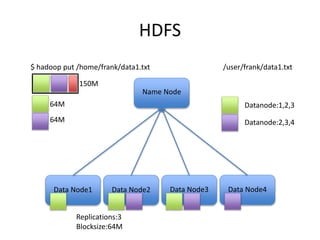
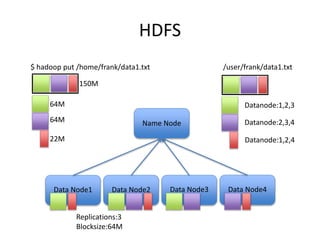
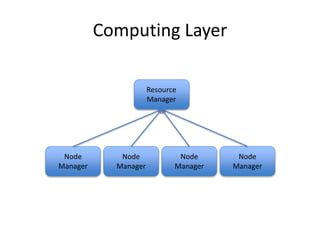
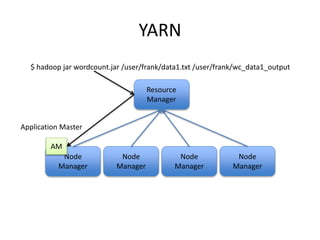
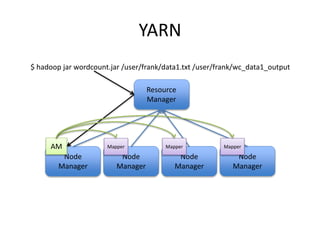
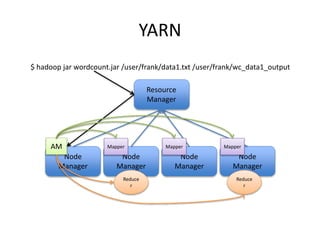
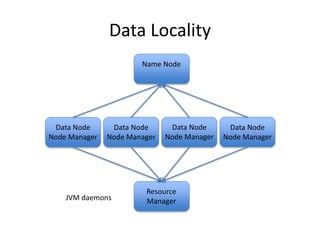
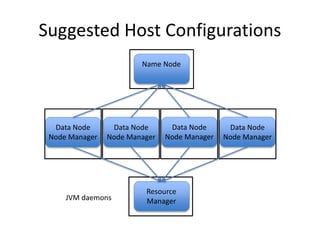
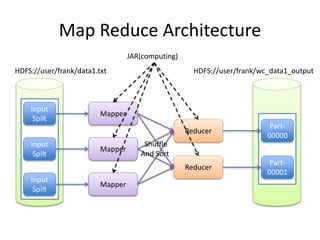
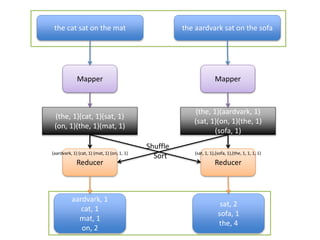
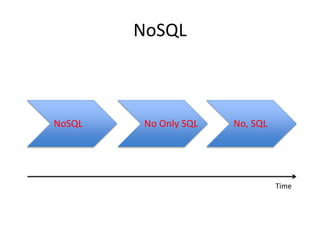



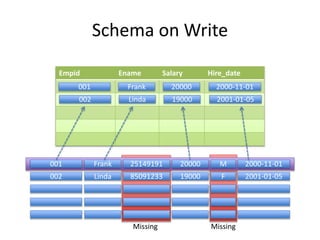
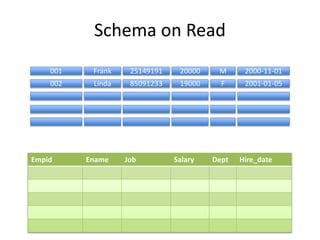
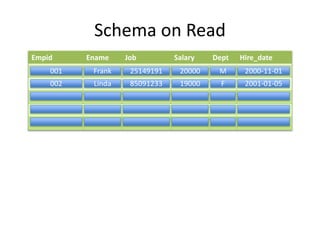
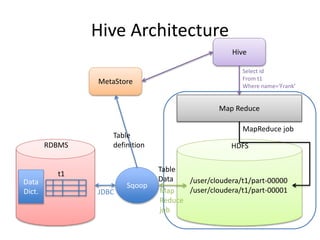
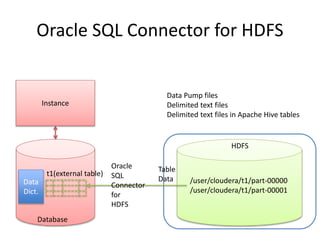
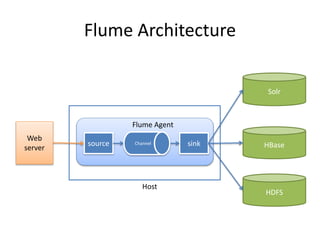
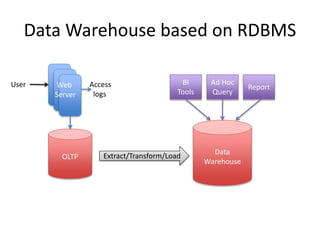
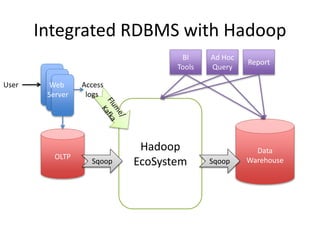


This document provides an overview of Hadoop and the Hadoop ecosystem. It discusses key Hadoop concepts like HDFS, MapReduce, YARN and data locality. It also summarizes SQL on Hadoop using tools like Hive, Impala and Spark SQL. The document concludes with examples of using Sqoop and Flume to move data between relational databases and Hadoop.











































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

















