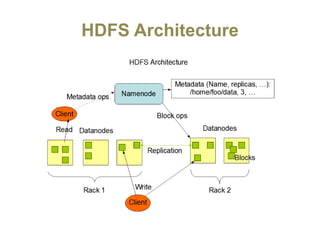
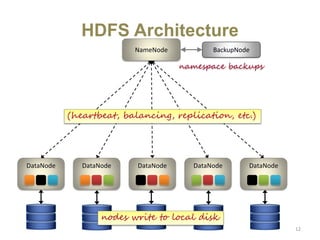
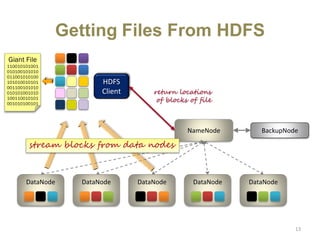
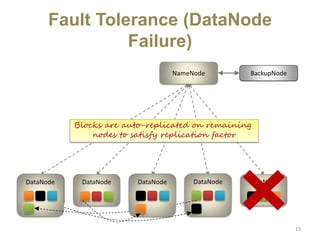
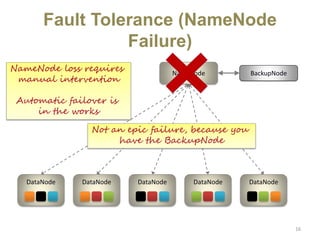
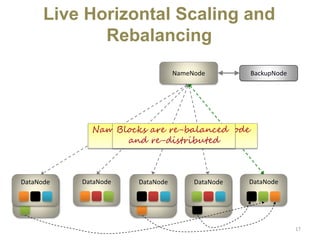
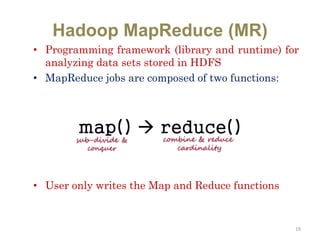
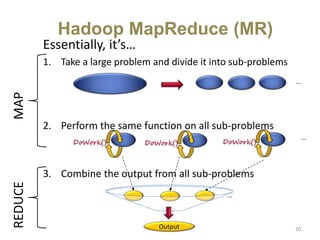
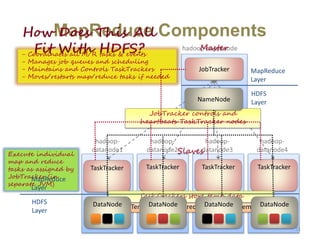
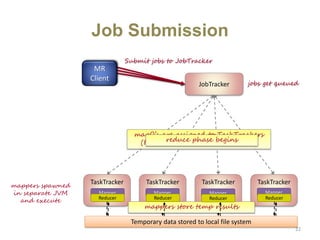
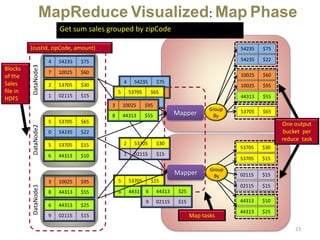
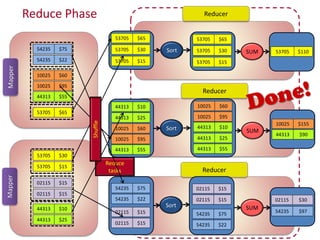
Hadoop is an open-source software framework for distributed storage and processing of large datasets across clusters of computers. It uses HDFS for data storage and MapReduce as a programming model for distributed computing. HDFS stores data reliably across machines in a Hadoop cluster as blocks and achieves high fault tolerance through replication. MapReduce allows processing of large datasets in parallel by dividing the work into independent tasks called Maps and Reduces. Hadoop has seen widespread adoption for applications involving massive datasets and is used by companies like Yahoo!, Facebook and Amazon.