Download as PDF, PPTX




![Documents Support Modern Requirements
Relational Document Data Structure
{ customer_id : 123,
first_name : "Mark",
last_name : "Smith",
city : "San Francisco",
location : [37.7576792,-122.5078112],
image : <binary data>,
phones: [ {
number : “1-212-555-1212”,
dnc : true,
type : “home”
},
{
number : “1-212-555-1213”,
type : “cell”
} ]
}](https://image.slidesharecdn.com/mongodbandhadoopdallas20160330-160331223615/75/MongoDB-Evenings-Dallas-What-s-the-Scoop-on-MongoDB-Hadoop-5-2048.jpg)



![db.tweets.aggregate([
{$group: {
_id: {
hour: {$hour: "$date"},
minute: {$minute: "$date"}
},
total: {$sum: "$sentiment.score"},
average: {$avg: "$sentiment.score"},
count: {$sum: 1},
happyTalk: {$push: "$sentiment.positive"}
}},
{$unwind: "$happyTalk"},
{$unwind: "$happyTalk"},
{$group: {
_id: "$_id",
total: {$first: "$total"},
average: {$first: "$average"},
count: {$first: "$count"},
happyTalk: {$addToSet: "$happyTalk"}
}},
{$sort: {_id: -1} }
])
But doesn't
MongoDB have…?
• aggregation framework
– machine learning libraries
• map reduce
– Javascript
– competing workloads](https://image.slidesharecdn.com/mongodbandhadoopdallas20160330-160331223615/75/MongoDB-Evenings-Dallas-What-s-the-Scoop-on-MongoDB-Hadoop-18-2048.jpg)




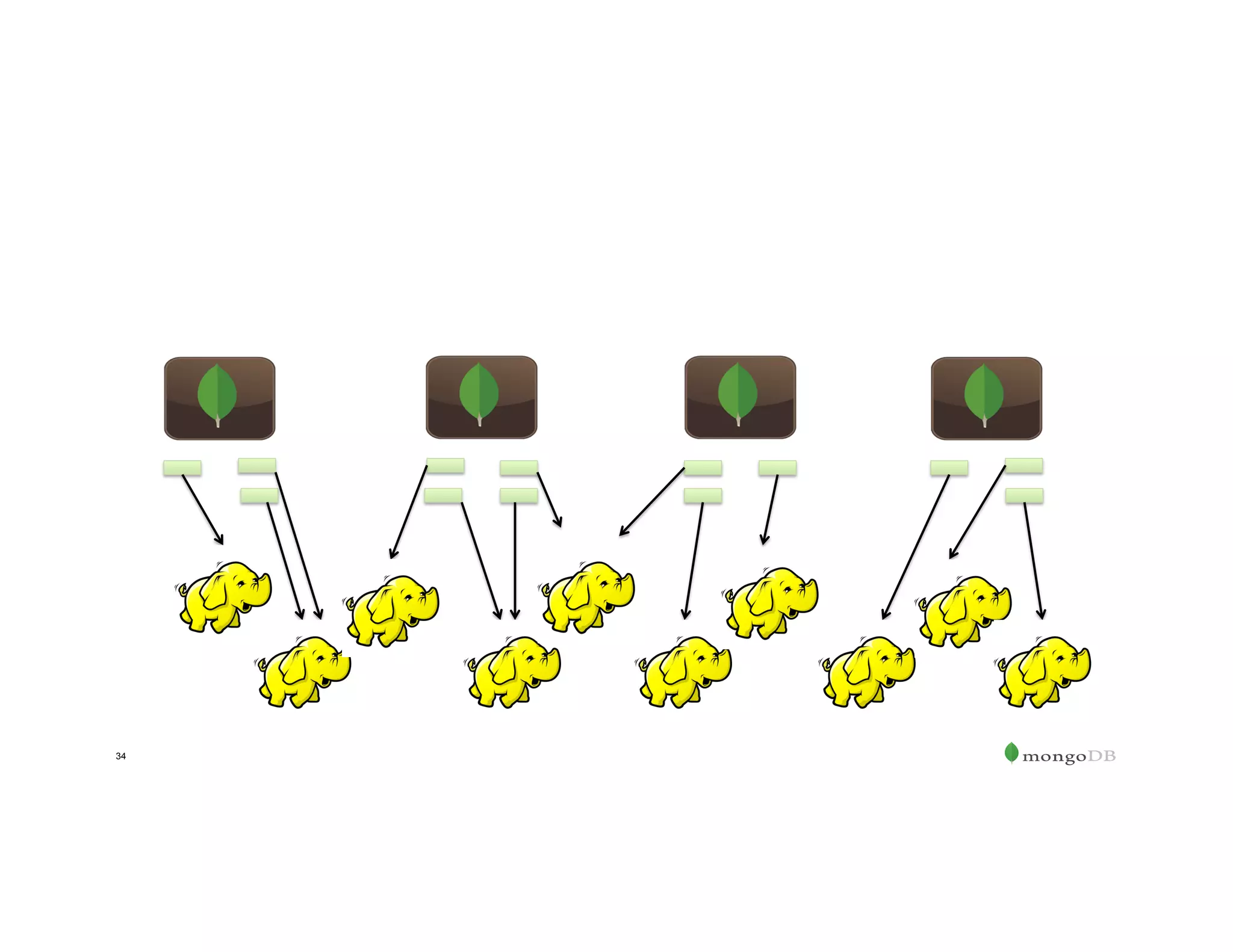
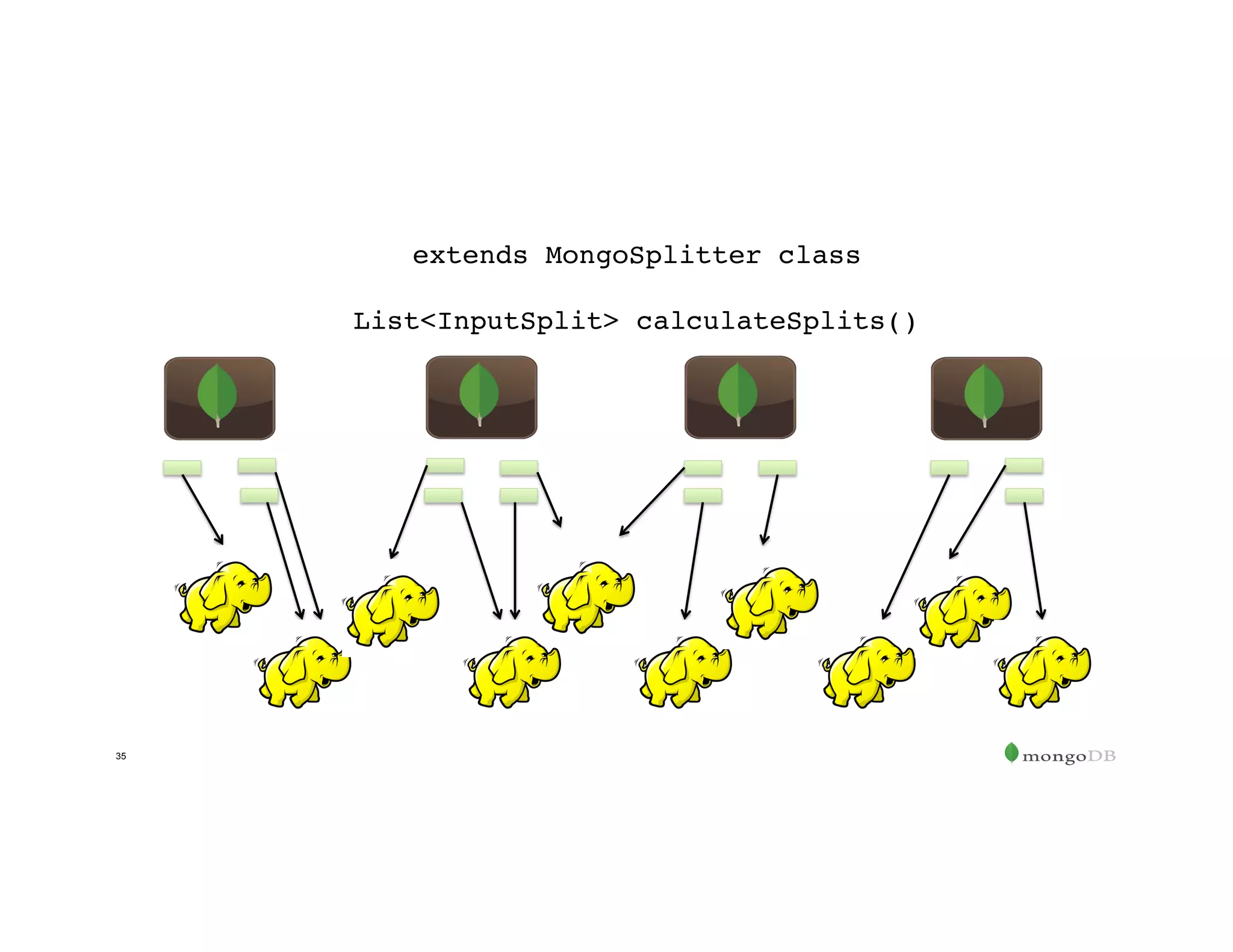





![Create the Resilient Distributed Dataset (RDD)
rdd = sc.newAPIHadoopRDD(
config, MongoInputFormat.class, Object.class, BSONObject.class)
config.set(
"mongo.input.uri", "mongodb://127.0.0.1:27017/marketdata.minbars")
config.set(
"mongo.input.query", '{"_id":{"$gt":{"$date":1182470400000}}}')
config.set(
"mongo.output.uri", "mongodb://127.0.0.1:27017/marketdata.fiveminutebars")
val minBarRawRDD = sc.newAPIHadoopRDD(
config,
classOf[com.mongodb.hadoop.MongoInputFormat],
classOf[Object],
classOf[BSONObject])](https://image.slidesharecdn.com/mongodbandhadoopdallas20160330-160331223615/75/MongoDB-Evenings-Dallas-What-s-the-Scoop-on-MongoDB-Hadoop-39-2048.jpg)



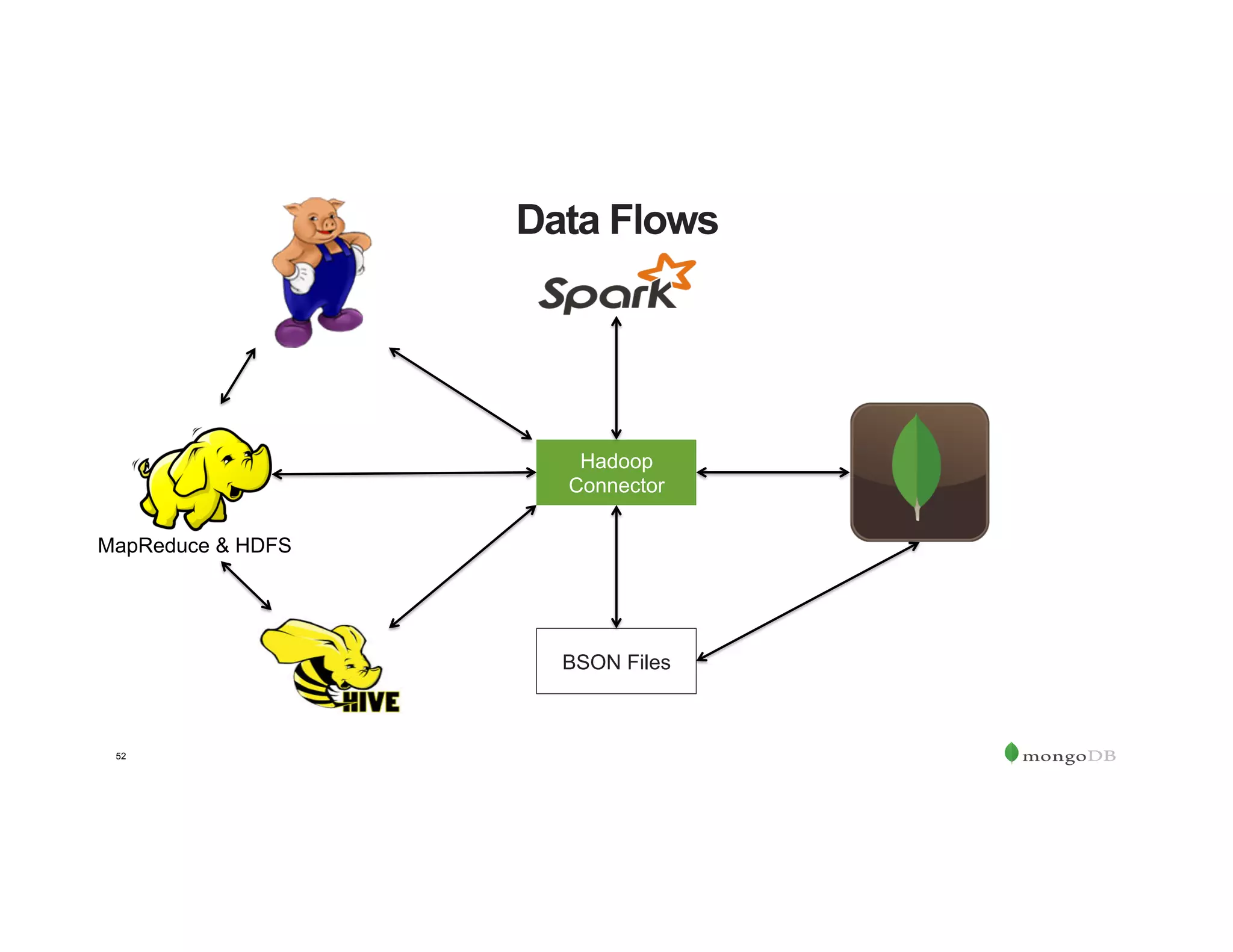
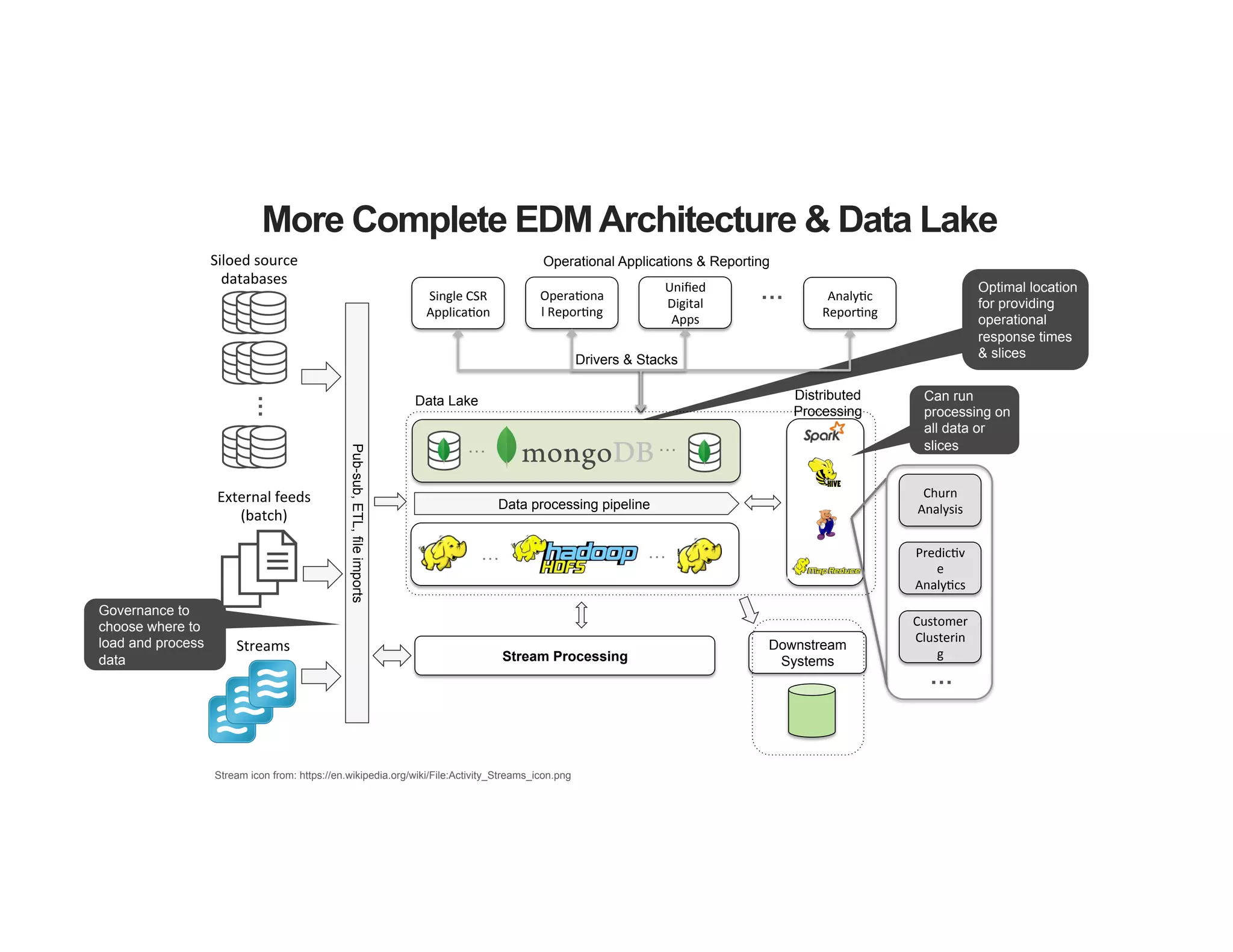


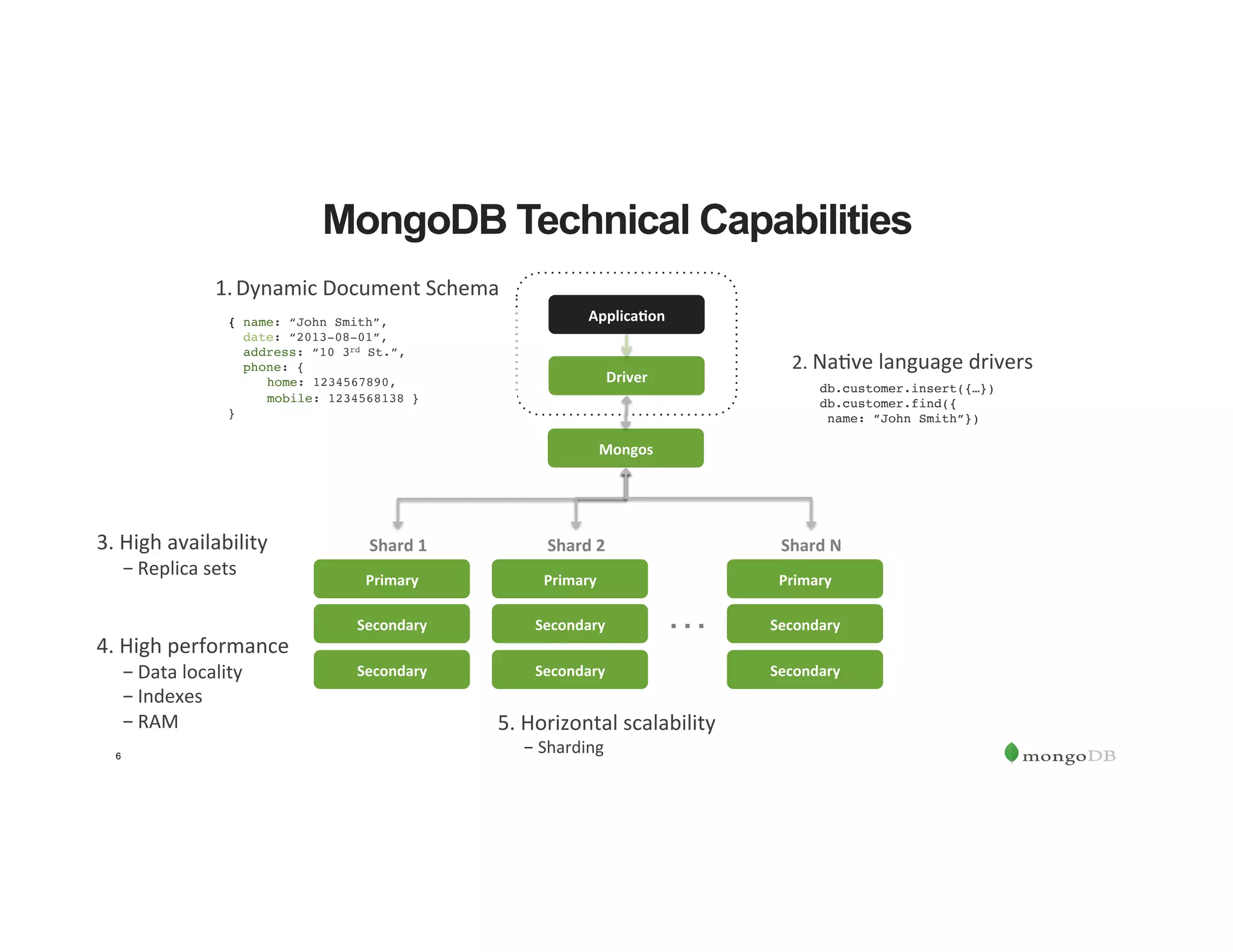
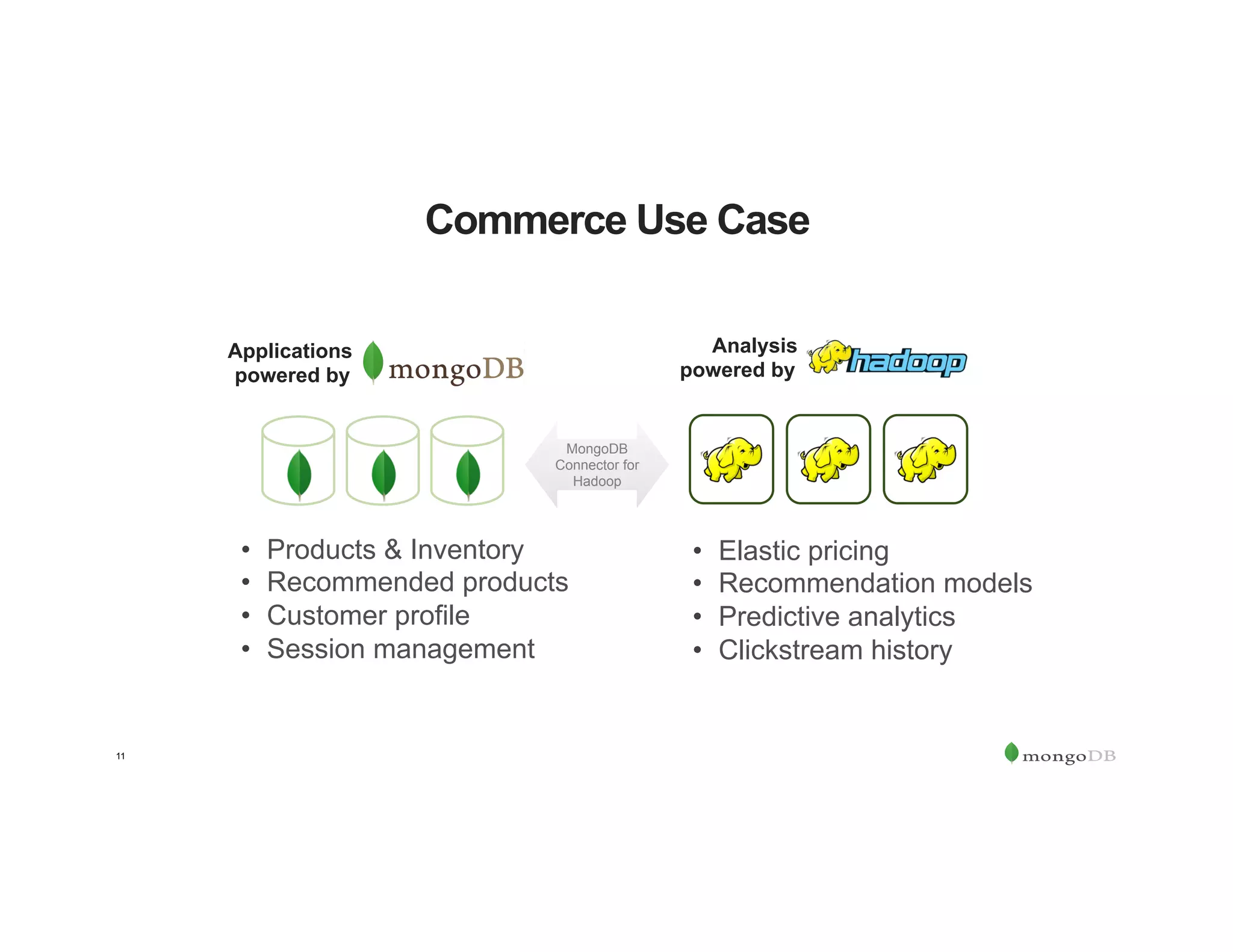
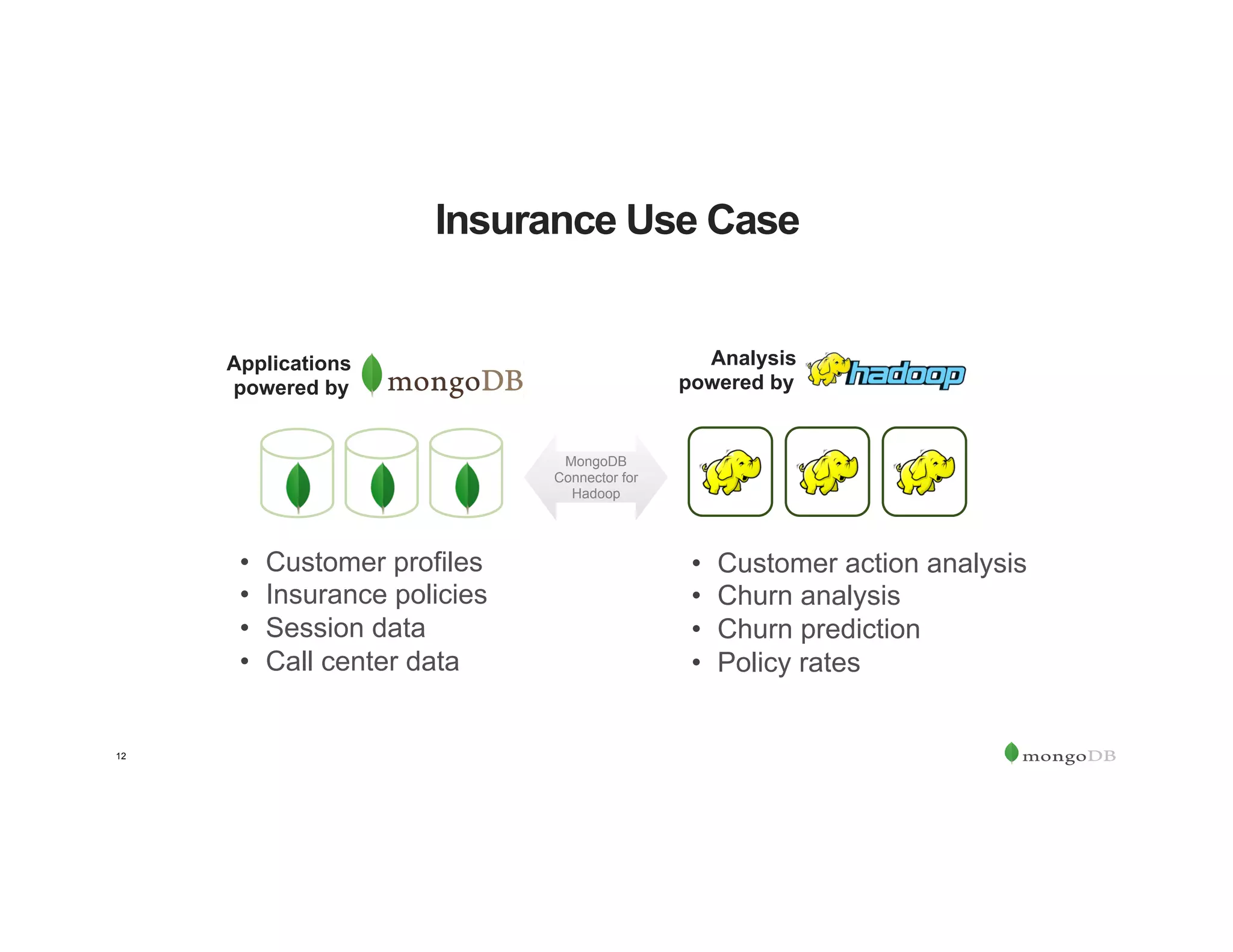
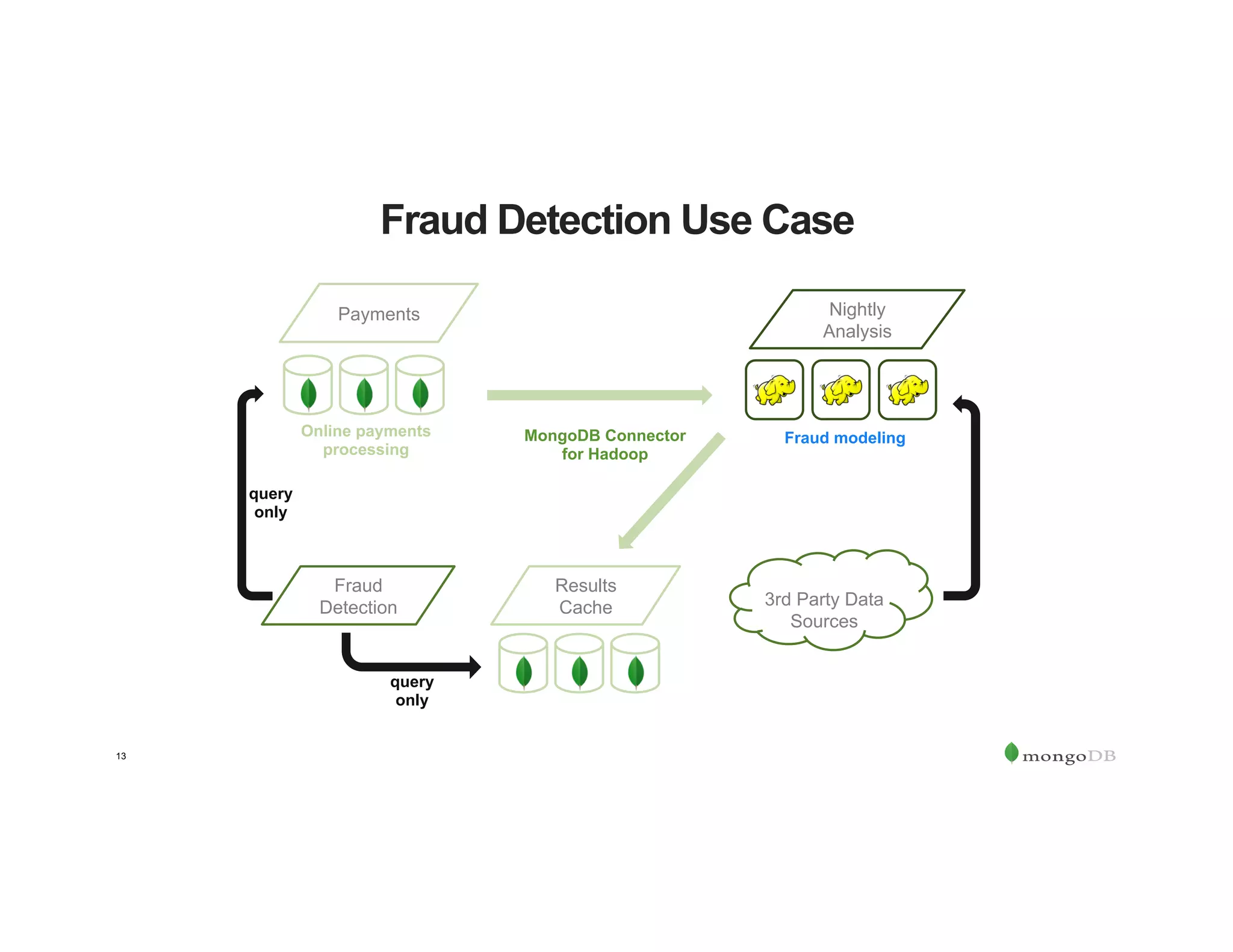
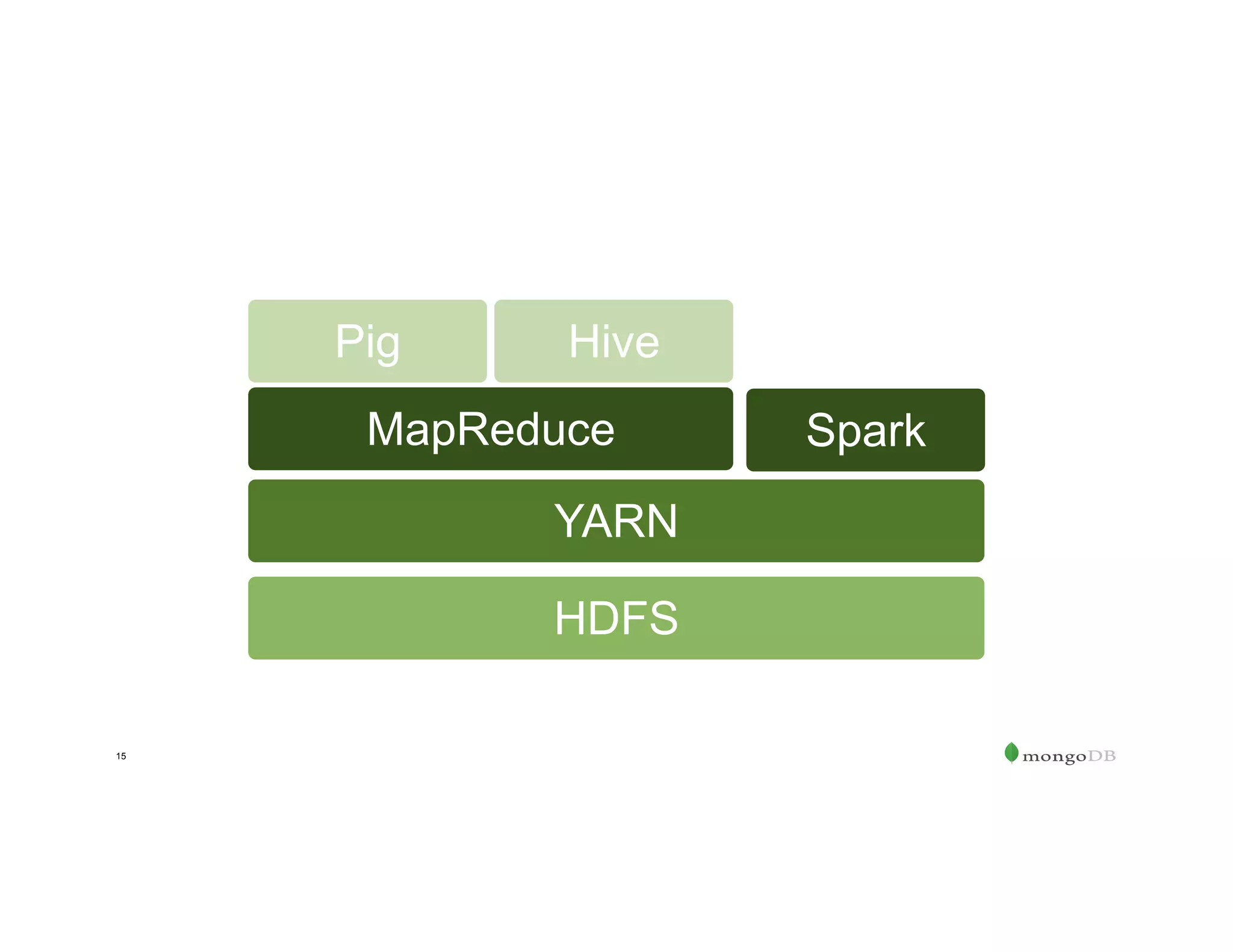
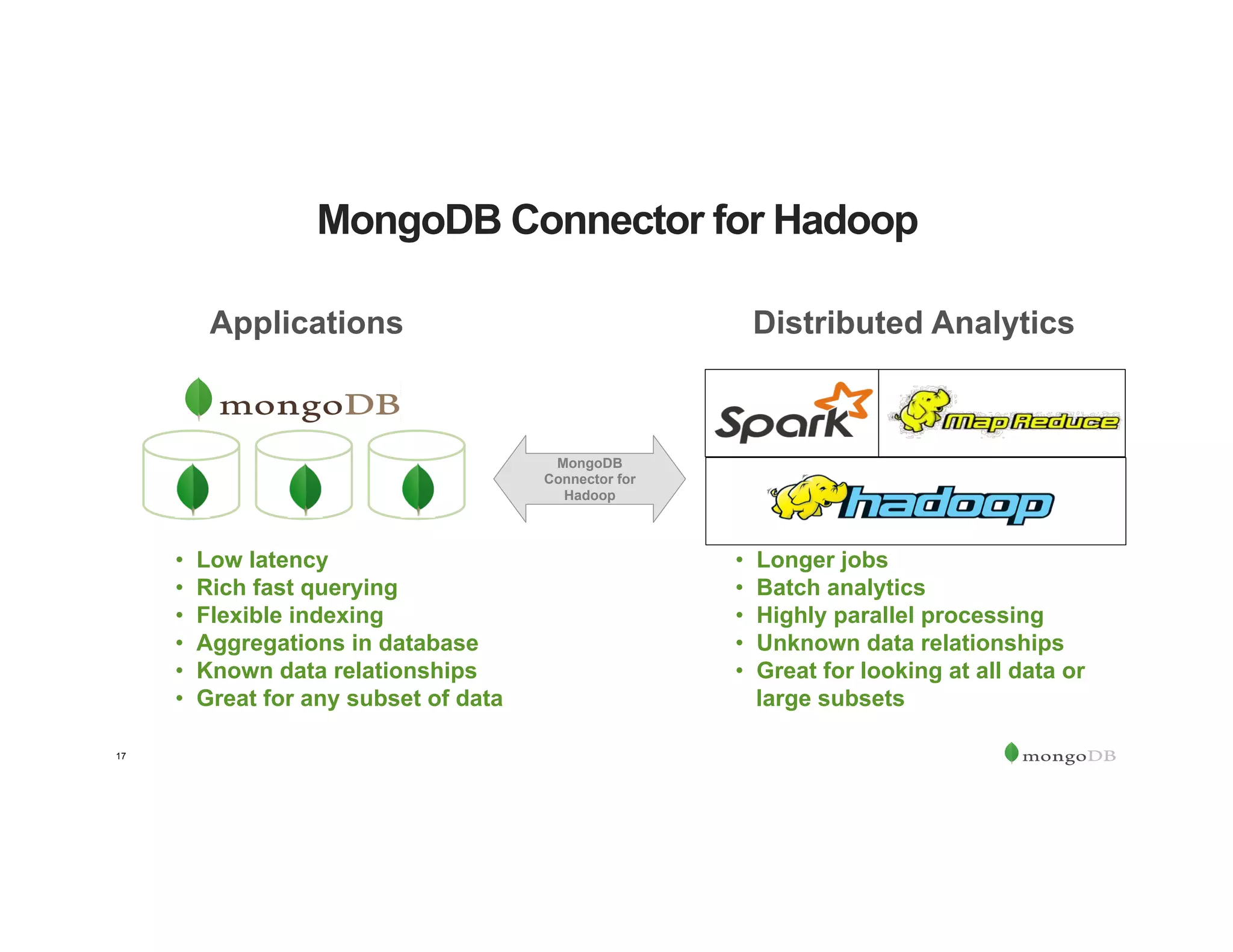
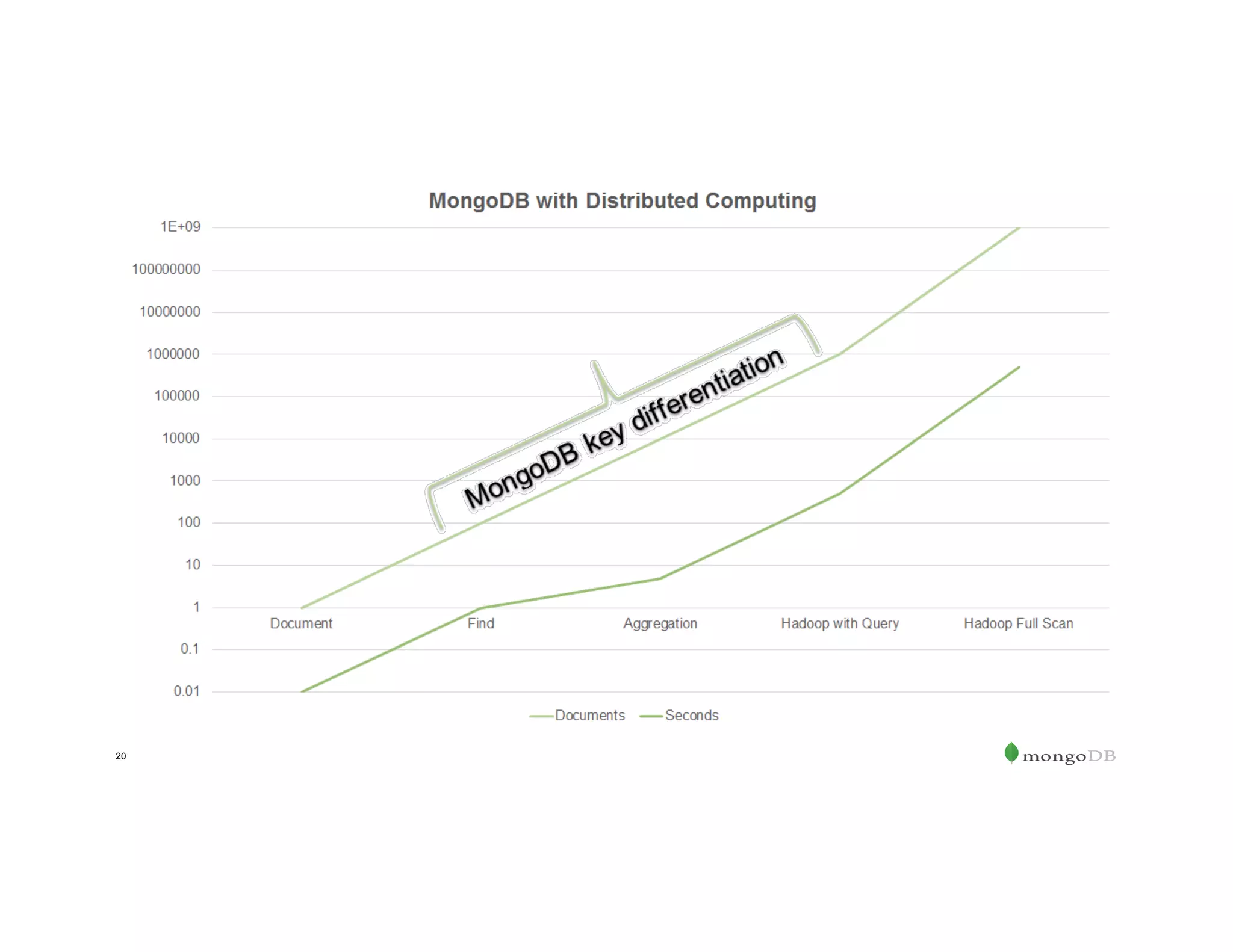
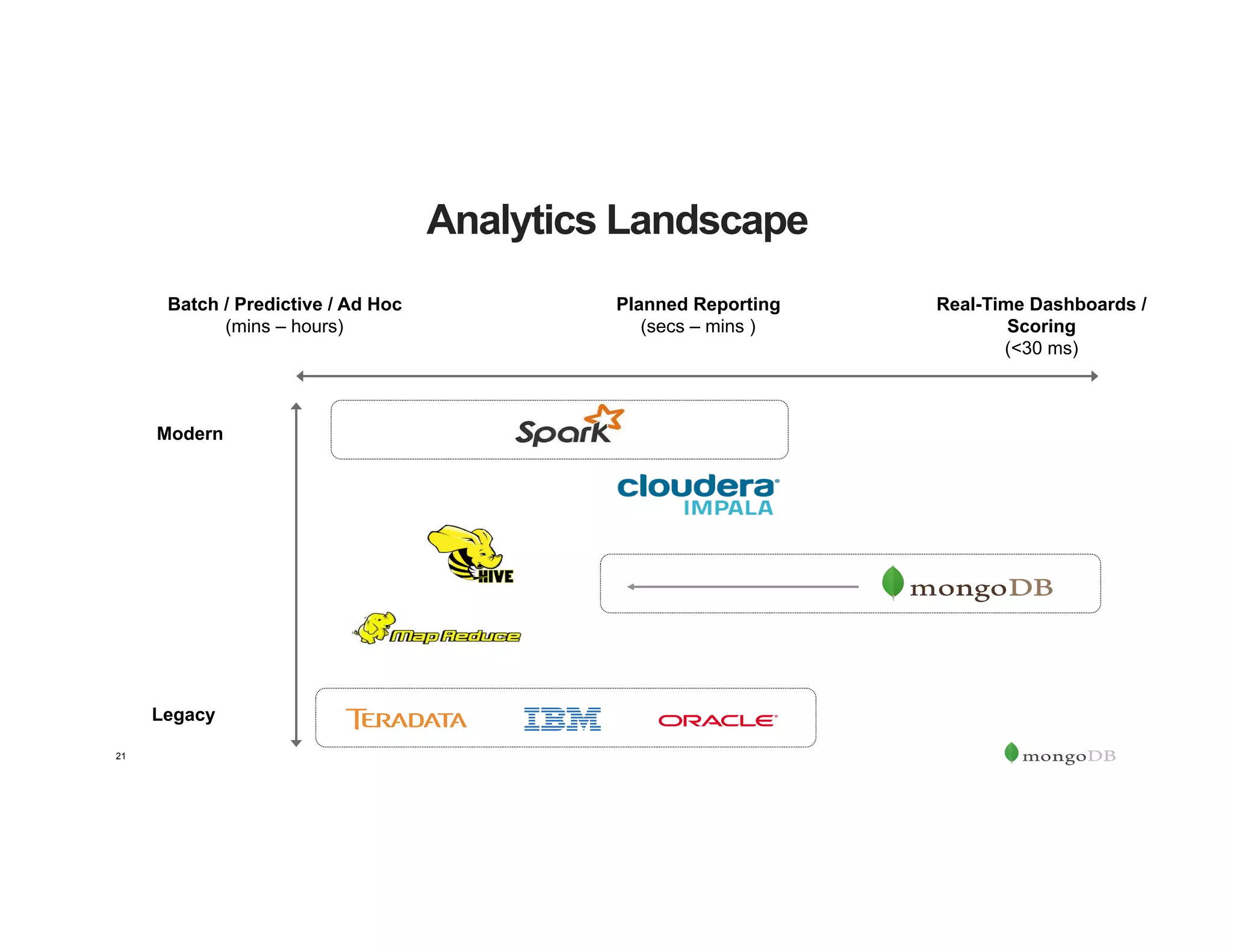
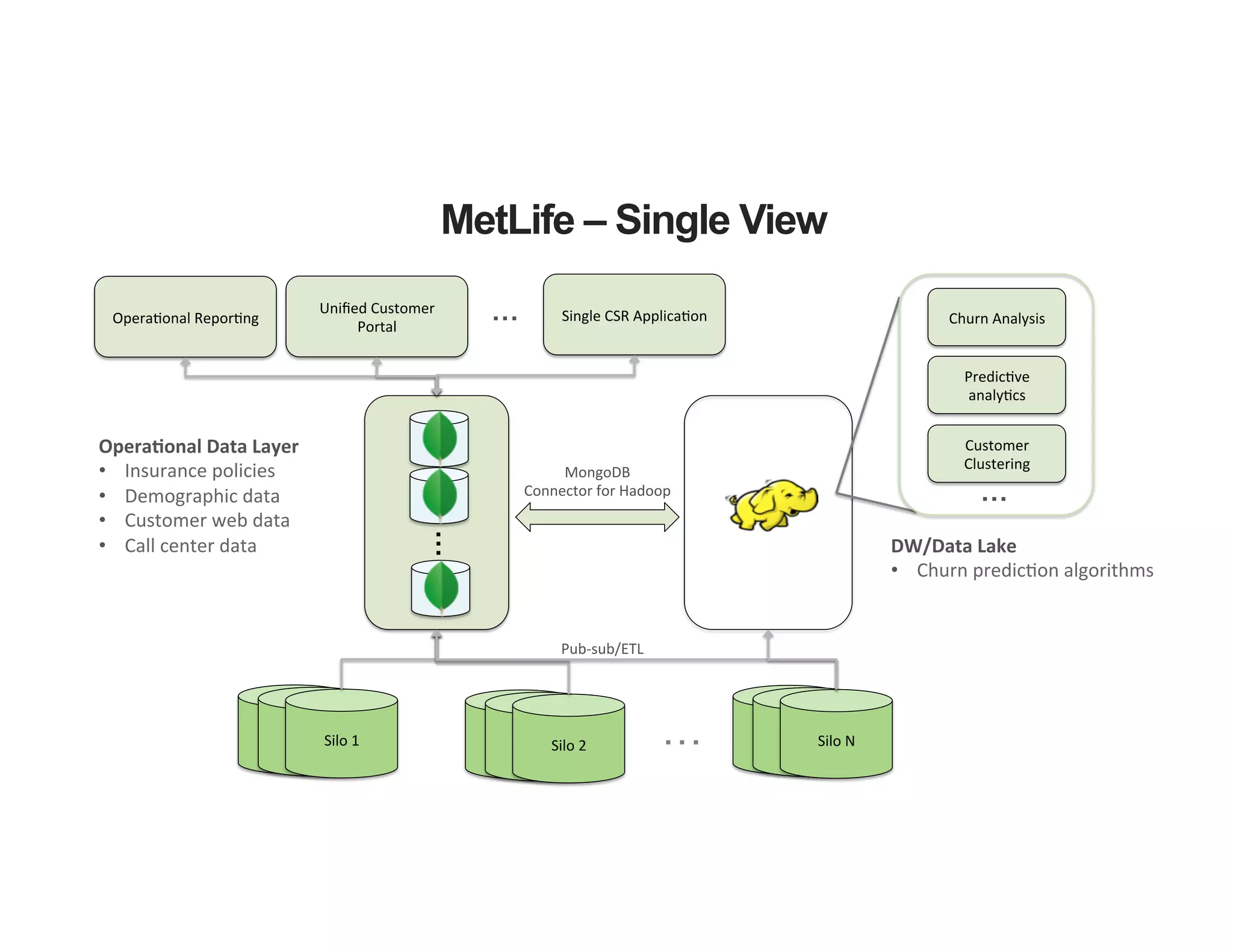
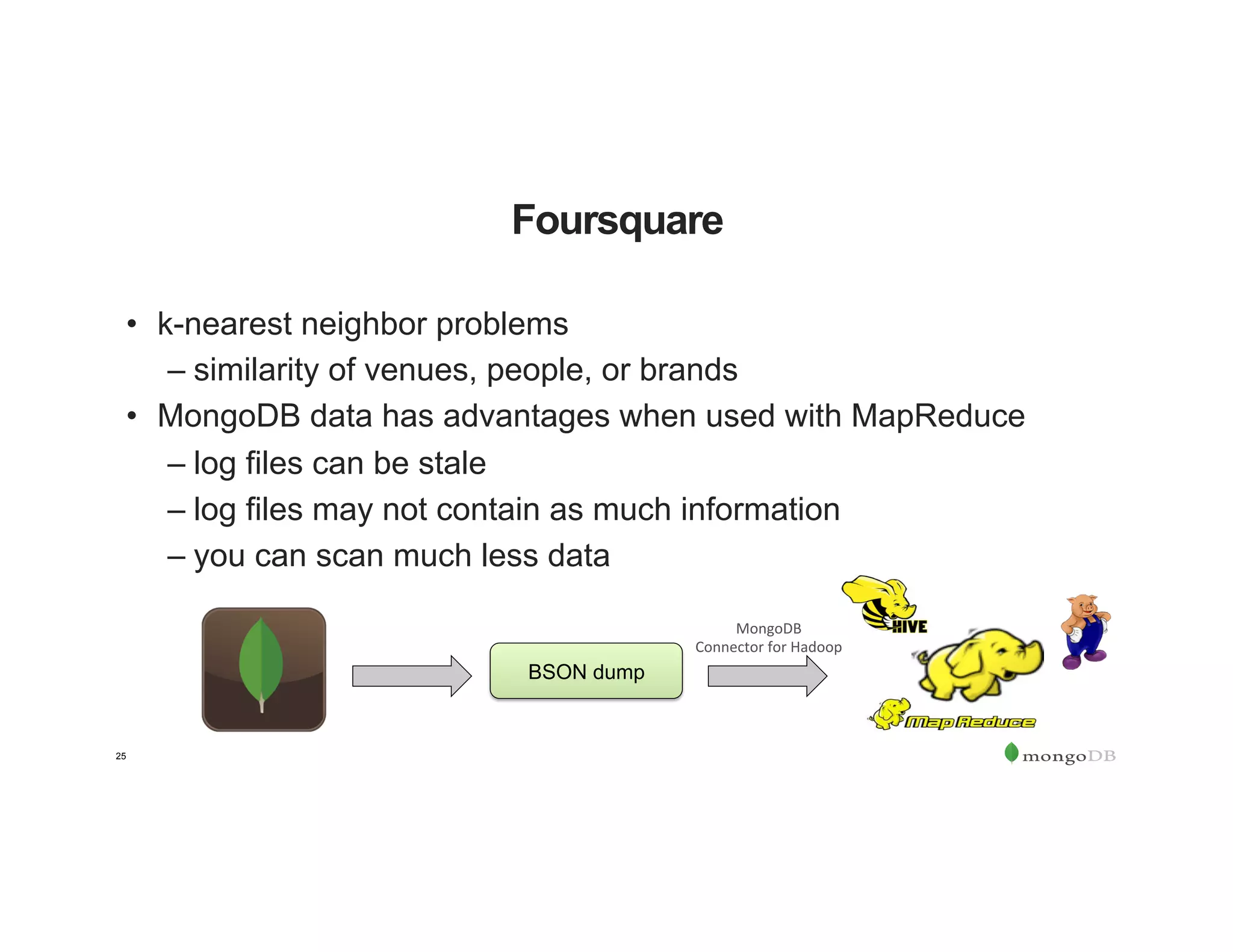
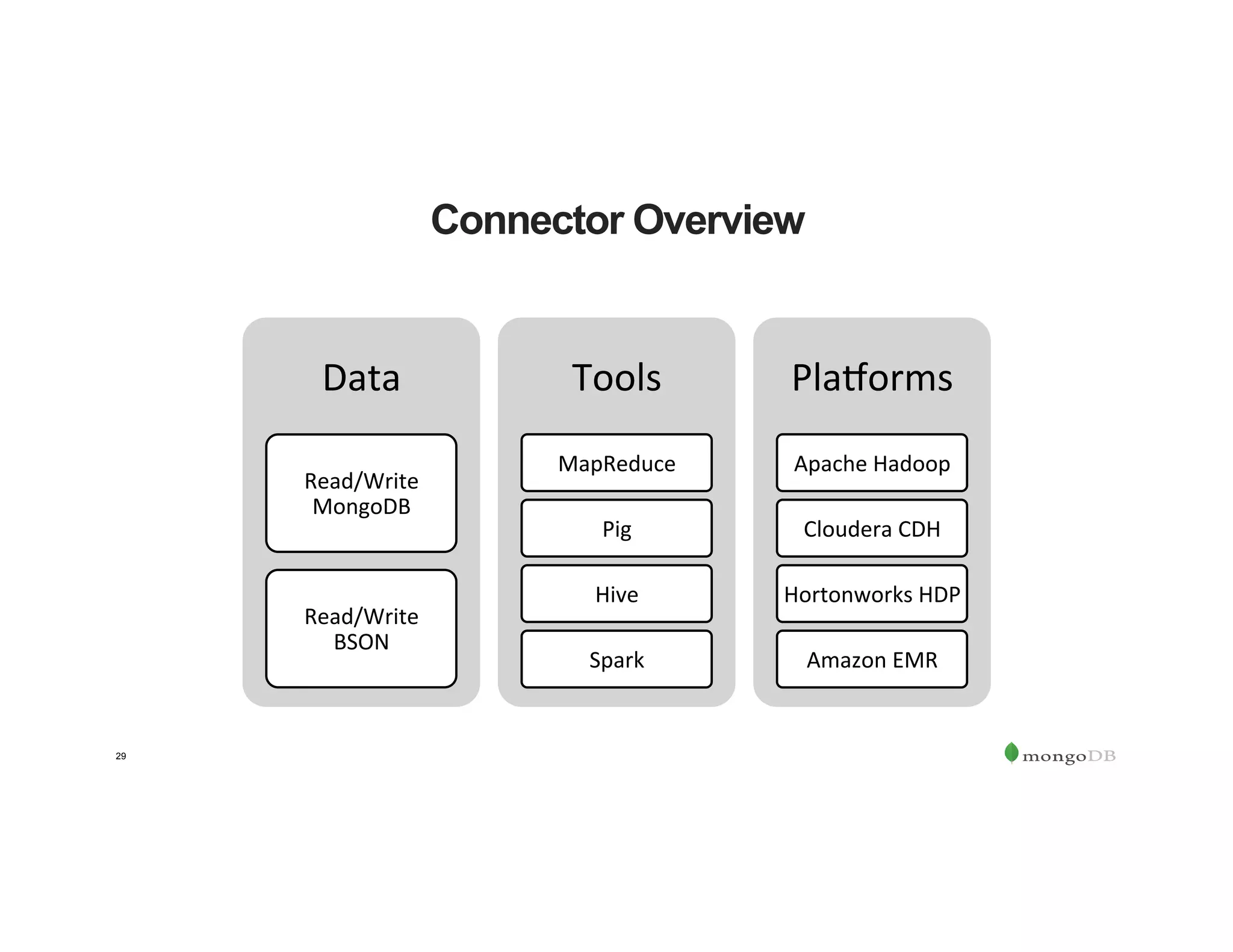
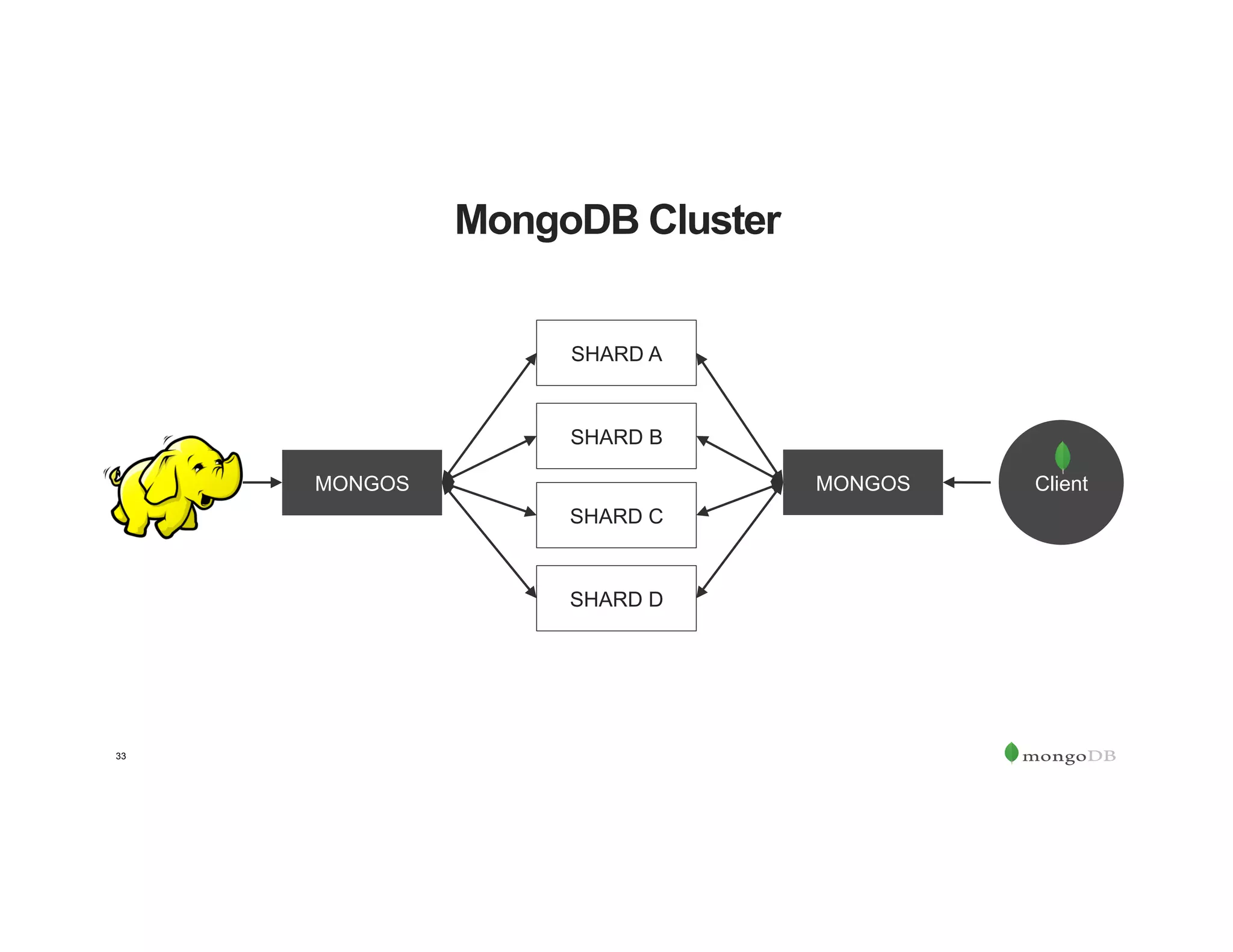
The document outlines the agenda for an event titled 'MongoDB Evenings Dallas,' which includes networking, discussions on MongoDB and Hadoop, and insights from industry speakers. It highlights MongoDB's technical capabilities, its integration with Hadoop for data processing, and various use cases in commerce and insurance. Additionally, it provides details on MongoDB connectors, data operations, analytics landscape, and event registration information.










































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

