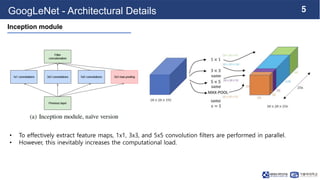
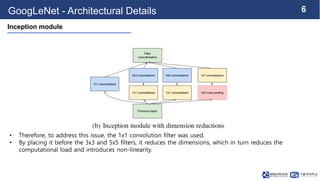
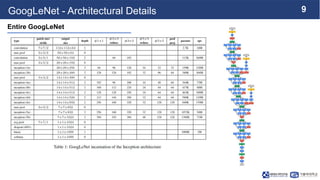
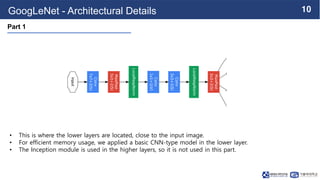
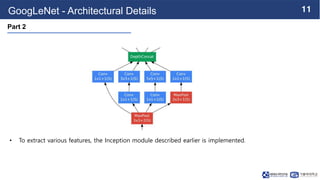
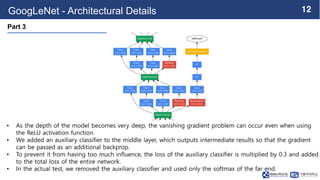
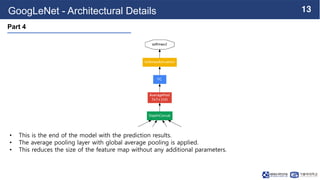
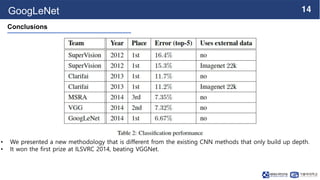
This document summarizes the GoogLeNet deep learning architecture. It describes how GoogLeNet uses inception modules containing 1x1 convolutional layers to reduce computational load. The inception modules perform 1x1, 3x3, and 5x5 convolutions in parallel, with the 1x1 layers reducing dimensionality first. This allows GoogLeNet to have significantly more parameters than VGGNet but higher accuracy and less computational resources. The document also explains how auxiliary classifiers are added to intermediate layers to address vanishing gradients in the deep model.