Downloaded 35 times





















![Remarks on Model Efficiency[1]
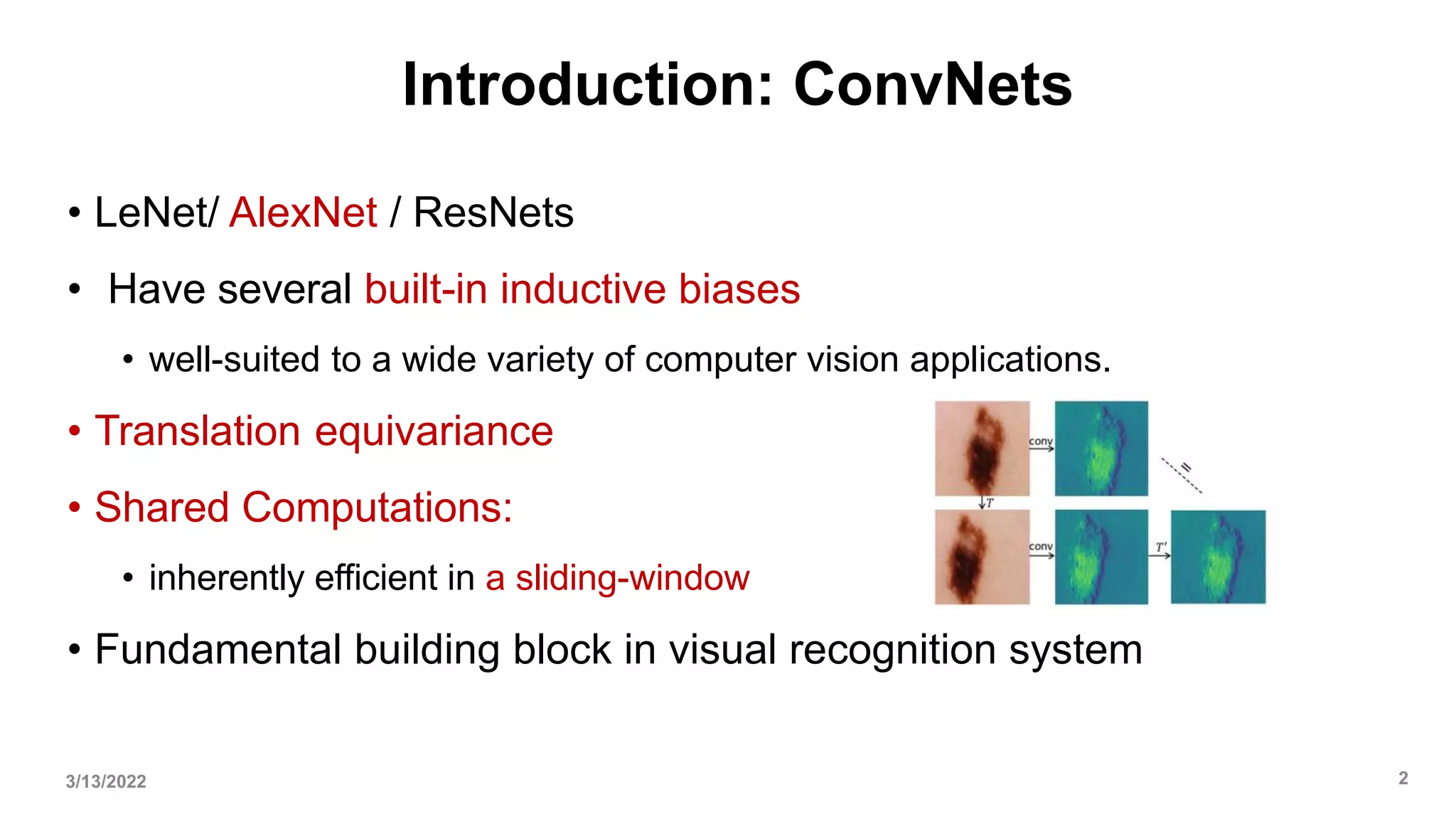
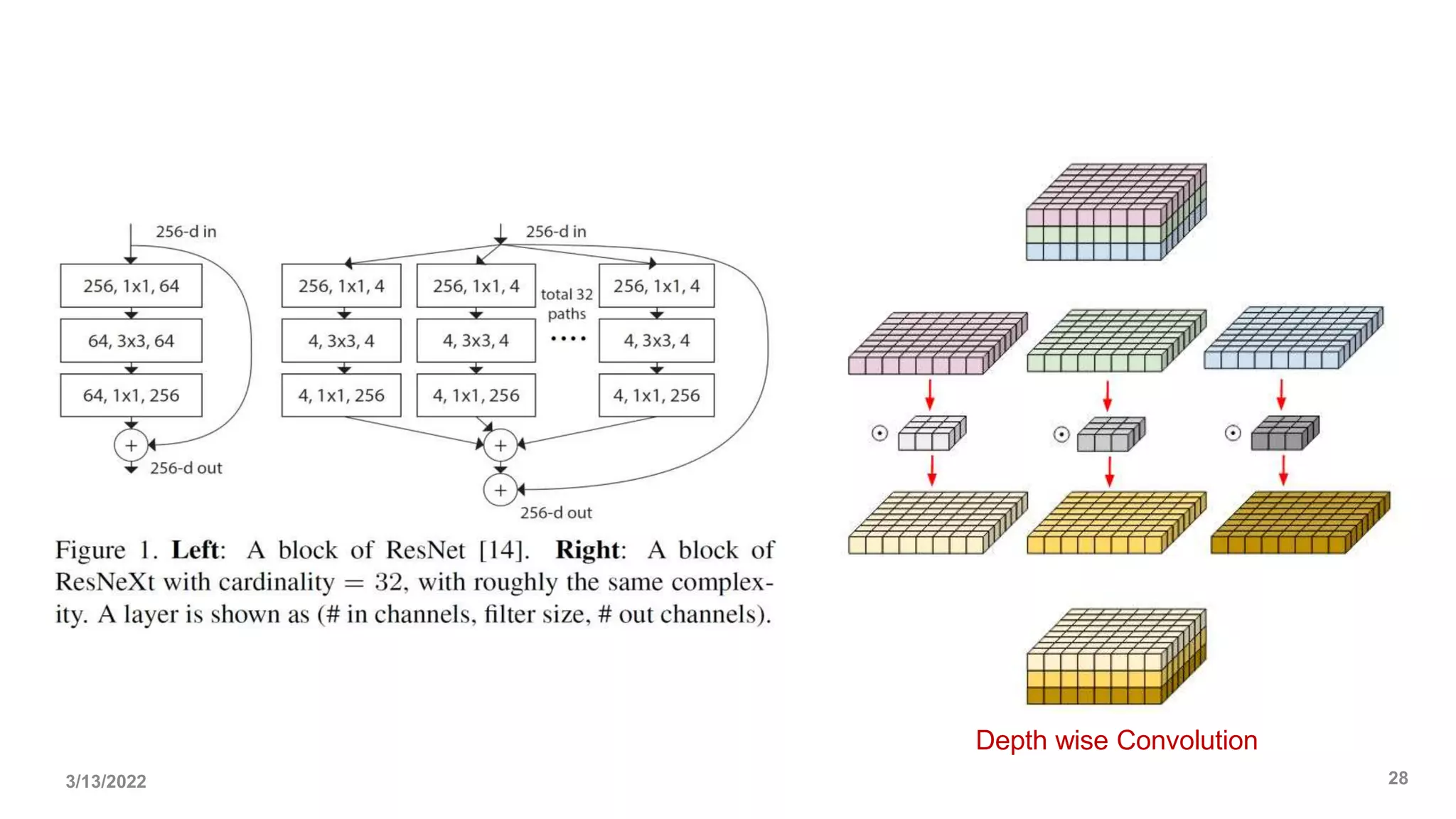
• Under similar FLOPs, models with depthwise convolutions are known to be slower
and consume more memory than ConvNets with only dense convolutions.
• Natural to ask whether the design of ConvNeXt will render it practically inefficient.
• As demonstrated throughout the paper, the inference throughputs of ConvNeXts
are comparable to or exceed that of Swin Transformers. This is true for both
classification and other tasks requiring higher-resolution inputs.
3/13/2022 46](https://image.slidesharecdn.com/dlpresentation-220313142652/75/ConvNeXt-A-ConvNet-for-the-2020s-explained-46-2048.jpg)
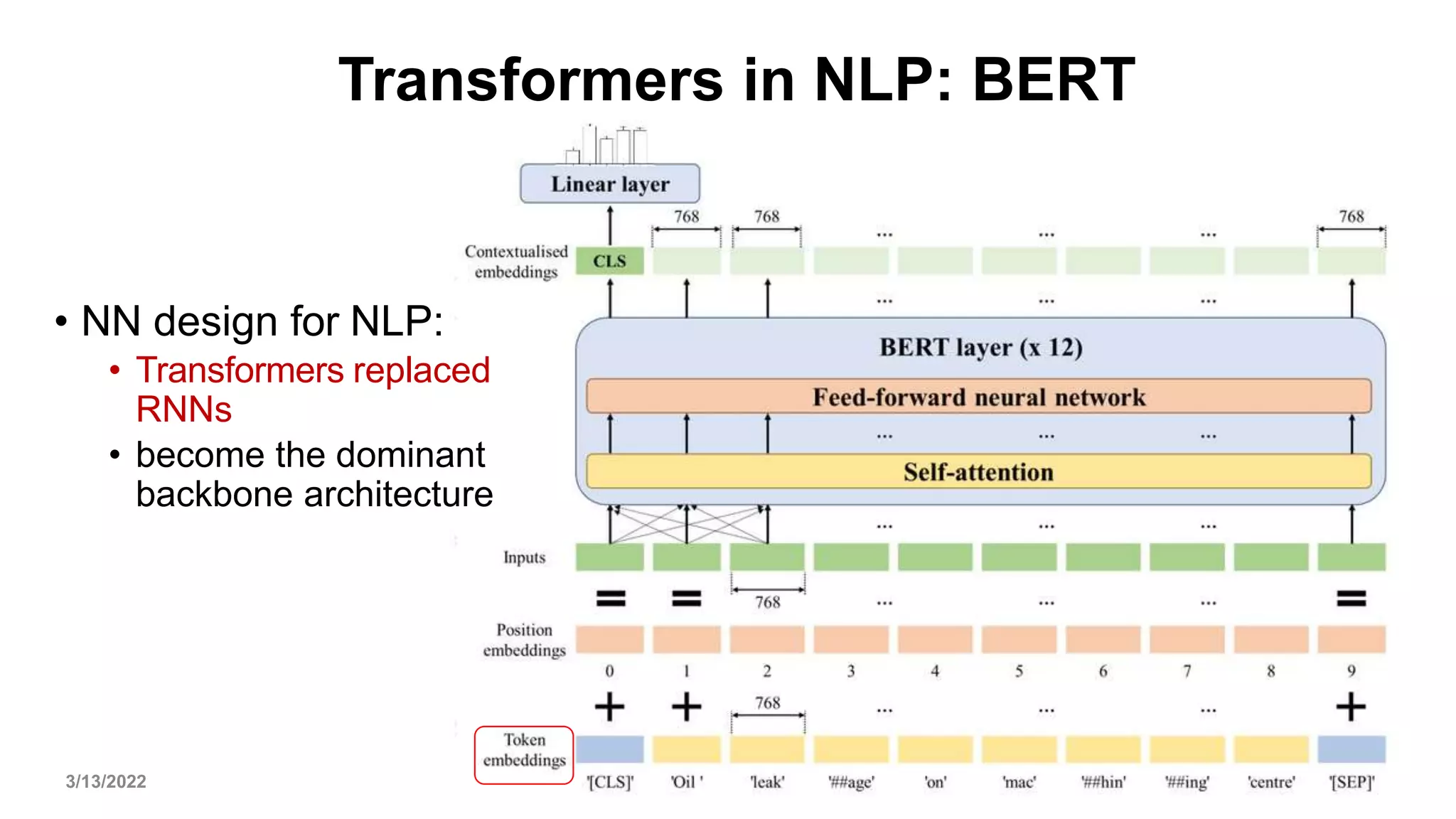
![Remarks on Model Efficiency[2]
• Furthermore, training ConvNeXts requires less memory than training Swin
Transformers. Training Cascade Mask-RCNN using ConvNeXt-B backbone
consumes 17.4GB of peak memory with a per-GPU batch size of 2, while the
reference number for Swin-B is 18.5GB.
• It is worth noting that this improved efficiency is a result of the ConvNet inductive
bias, and is not directly related to the self-attention mechanism in vision
Transformers
3/13/2022 47](https://image.slidesharecdn.com/dlpresentation-220313142652/75/ConvNeXt-A-ConvNet-for-the-2020s-explained-47-2048.jpg)
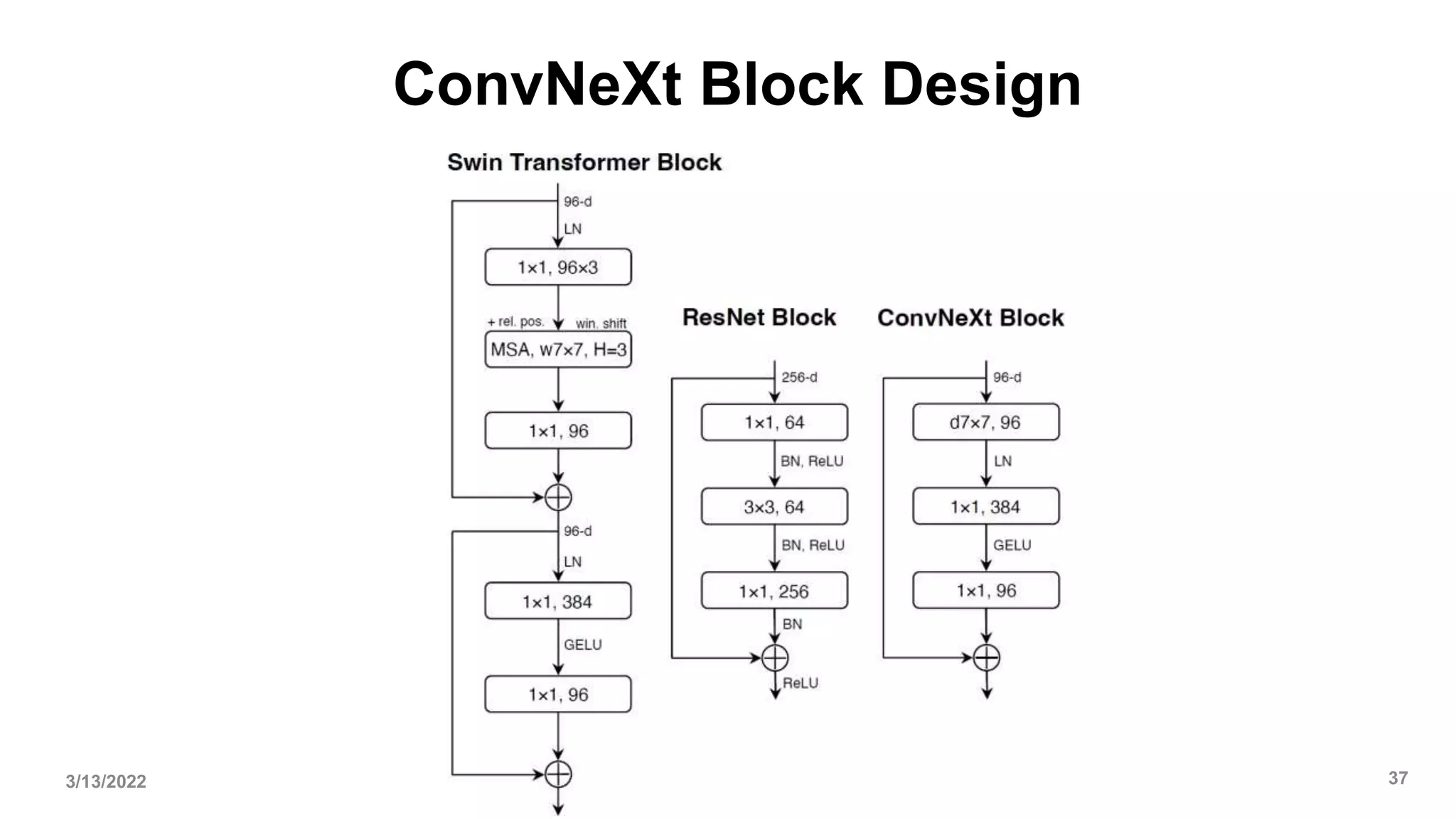
![Conclusions[1]
• In the 2020s, vision Transformers, particularly hierarchical ones such as Swin
Transformers, began to overtake ConvNets as the favored choice for generic
vision backbones.
• The widely held belief is that vision Transformers are more accurate,
efficient, and scalable than ConvNets.
• ConvNeXts, a pure ConvNet model can compete favorably with state-of- the-art
hierarchical vision Transformers across multiple computer vision benchmarks,
while retaining the simplicity and efficiency of standard ConvNets.
3/13/2022 48](https://image.slidesharecdn.com/dlpresentation-220313142652/75/ConvNeXt-A-ConvNet-for-the-2020s-explained-48-2048.jpg)
![Conclusions[2]
• In some ways, these observations are surprising while ConvNeXt
model itself is not completely new—many design choices have all
been examined separately over the last decade, but not collectively.
• The authors hope that the new results reported in this study will
challenge several widely held views and prompt people to rethink the
importance of convolution in computer vision.
3/13/2022 49](https://image.slidesharecdn.com/dlpresentation-220313142652/75/ConvNeXt-A-ConvNet-for-the-2020s-explained-49-2048.jpg)


The document presents ConvNeXt, a pure convolutional neural network architecture that achieves performance on par with state-of-the-art vision transformers. The authors modernized ResNet architectures with techniques from vision transformers like increased training epochs, data augmentation, and larger kernel sizes. This resulted in ConvNeXt surpassing Swin transformers on various tasks like image classification, object detection, and segmentation while retaining the simplicity and efficiency of convolutional networks. The study challenges beliefs that vision transformers are inherently more accurate and efficient than convolutional networks.








































































