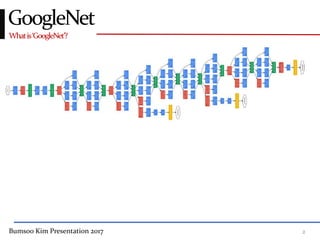
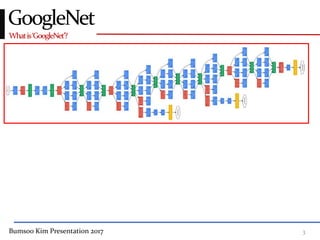
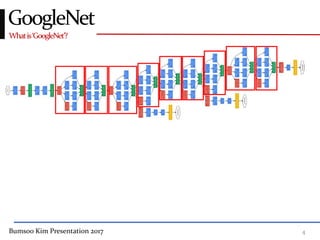
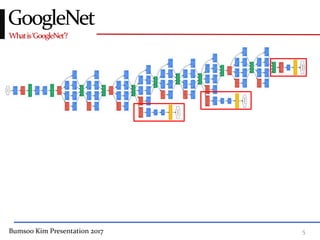
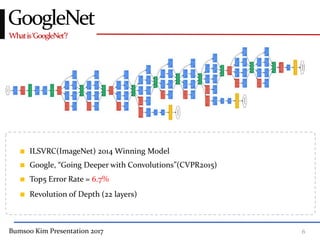
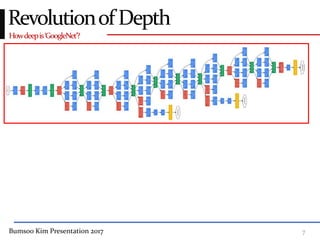
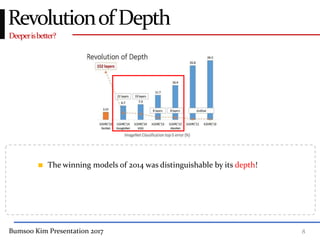
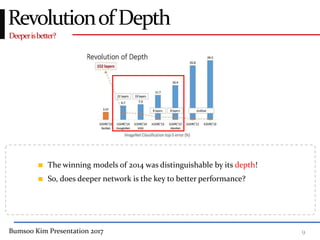
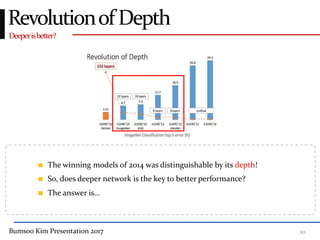
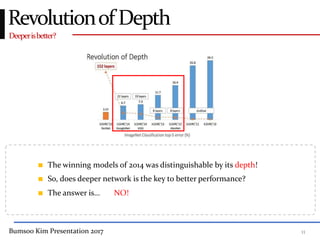
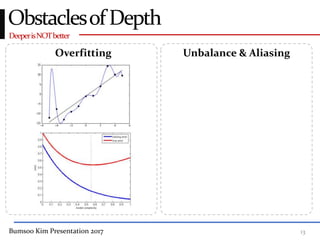
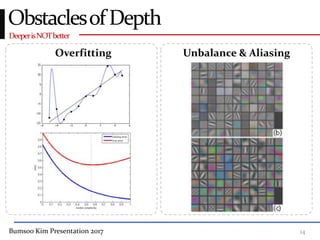
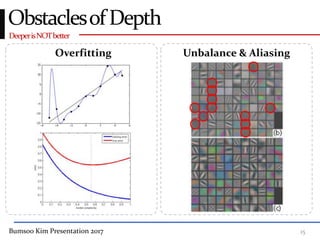
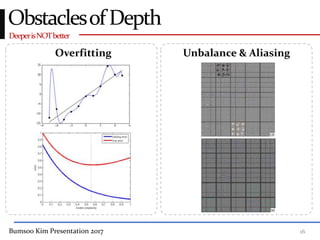
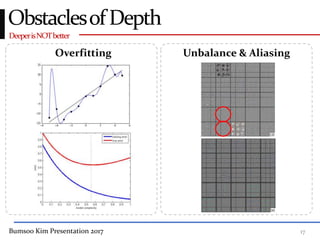
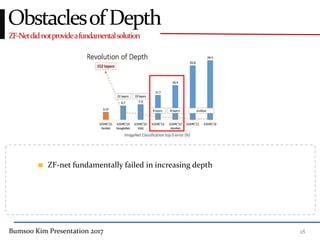
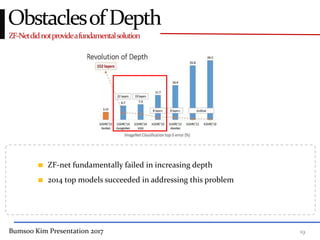
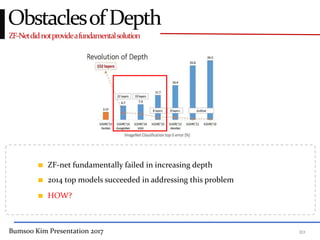
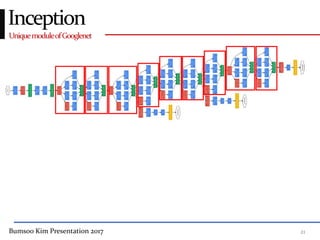
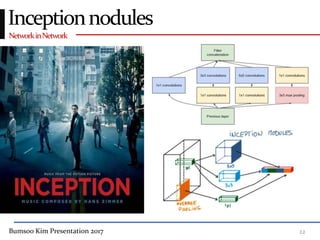
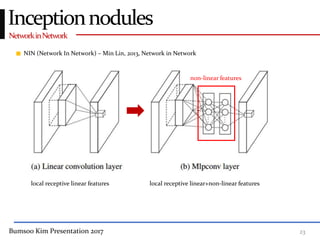
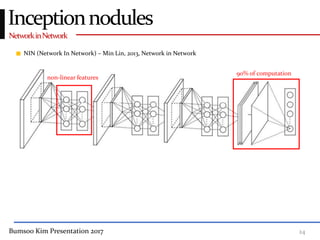
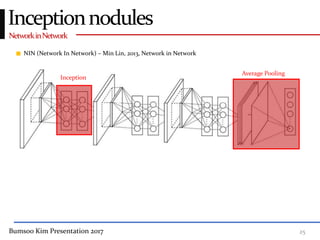
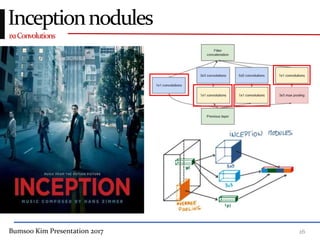
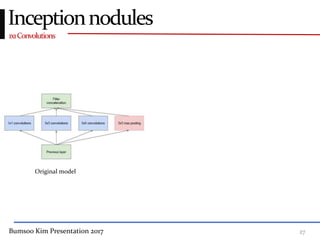
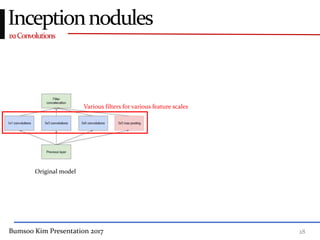
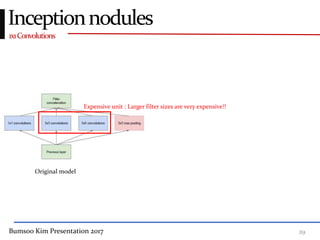
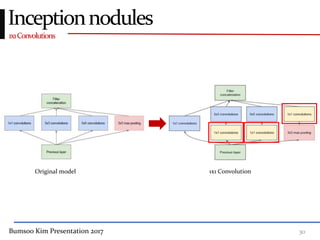
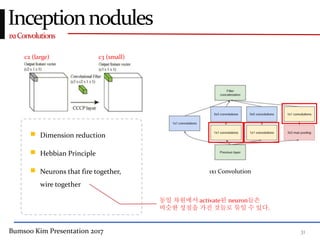
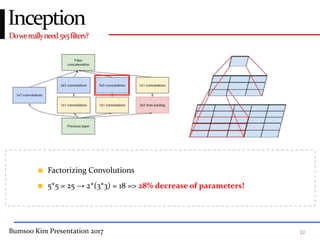
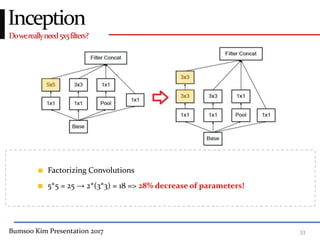
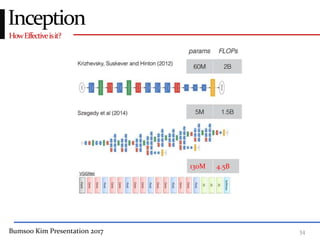
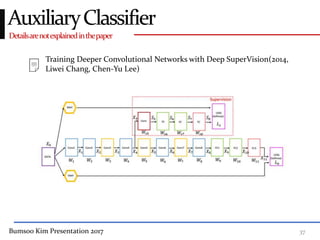
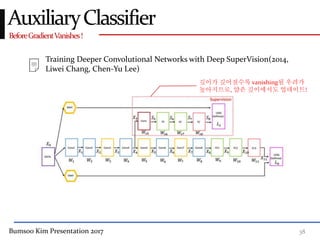
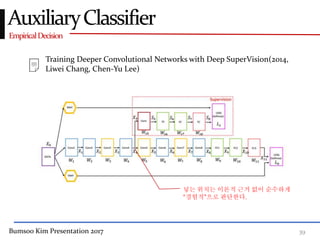
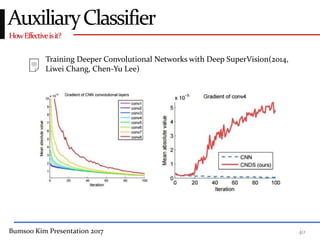
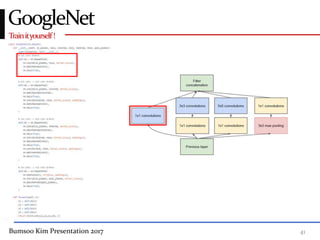
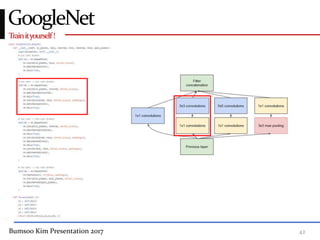
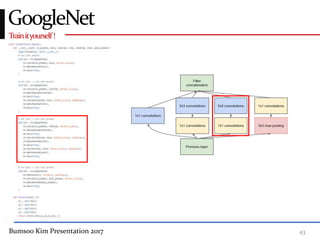
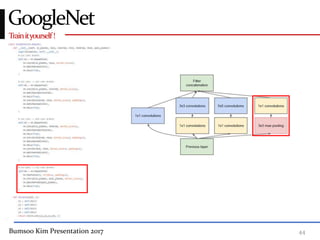
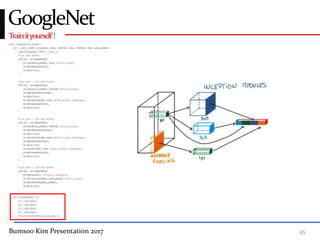
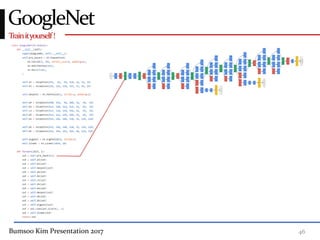
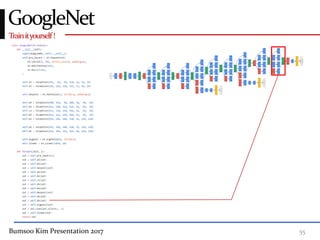
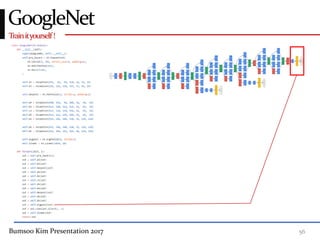
This presentation discusses GoogleNet, the 2014 winning model in the ILSVRC image classification competition. GoogleNet (also known as Inception) revolutionized convolutional neural networks by utilizing inception modules to increase depth while avoiding issues like overfitting. The inception module employs 1x1 convolutions for dimension reduction before 3x3 and 5x5 convolutions, allowing deeper networks to be trained. It also uses auxiliary classifiers to address the gradient vanishing problem and help train deeper layers. The presentation provides details on the architecture and training of GoogleNet, which achieved top-5 error rate of 6.7% and demonstrated that increased depth from innovative modules, rather than simply adding layers, can lead to better performance.
























































![[251] implementing deep learning using cu dnn](https://cdn.slidesharecdn.com/ss_thumbnails/215implementingdeeplearningusingcudnn-150915052020-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




























![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)



![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)