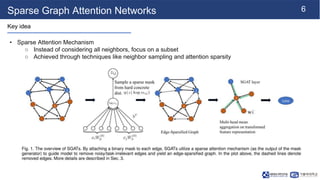
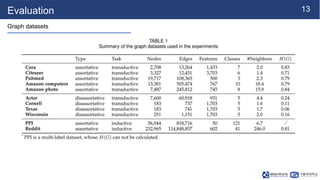
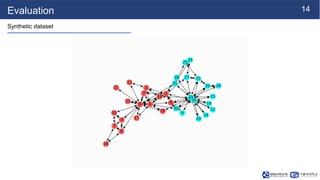
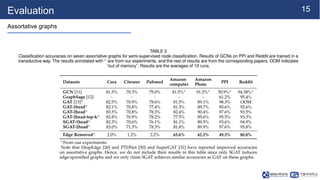
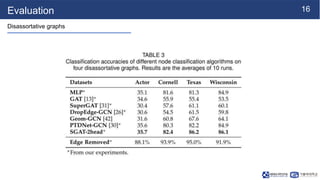
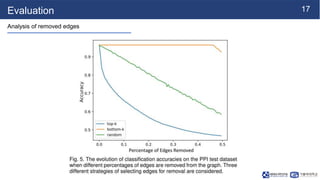
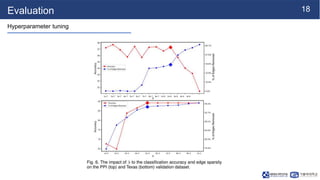
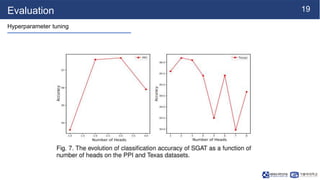
This document summarizes a research paper on sparse graph attention networks (SGATs). SGATs apply an attention mechanism to only a subset of neighbors for each node to improve the scalability and memory efficiency of graph attention networks. The key ideas are a sparse attention mechanism using techniques like neighbor sampling and a binary gate attached to each edge. SGATs show advantages in scalability, memory usage, and performance on disassortative graphs by removing up to 80% of edges while maintaining classification accuracy. Evaluation on synthetic and real-world graphs demonstrates SGATs can identify and remove noisy edges.













![250224_JH_Labseminar[Graph Attention Networks].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/250224jhlabseminar-250224130028-853586a2-thumbnail.jpg?width=640&height=640&fit=bounds)



![240930_JW_labseminar[Graph Attention Networks].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240930jwlabseminargat-240930125744-5764cef7-thumbnail.jpg?width=640&height=640&fit=bounds)






























































