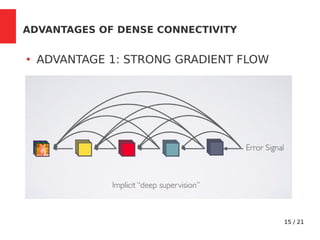
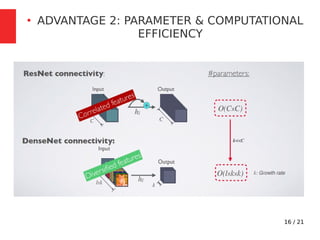
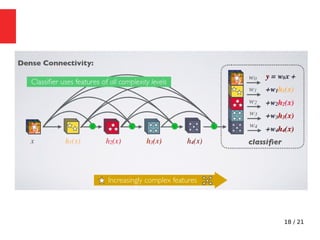
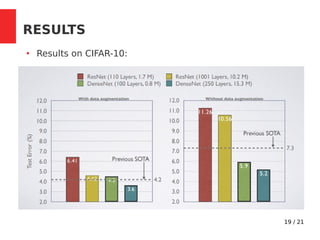
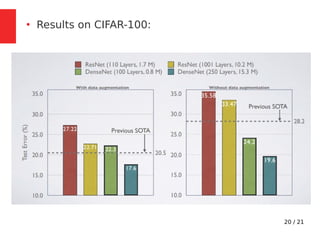
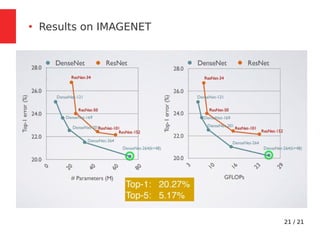
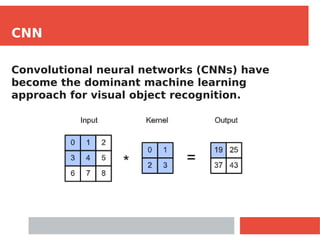
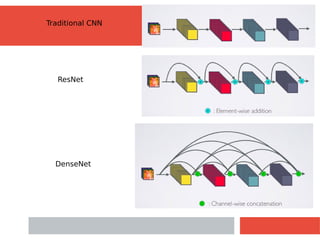
The document discusses Densely Connected Convolutional Networks (DenseNets) as a solution to the vanishing gradient problem found in deep neural networks, emphasizing their architecture's direct connections from any layer to all subsequent layers. Key features include the narrowness of layers, pooling strategies, growth rate of feature maps, and bottleneck layers for efficiency. DenseNets demonstrate advantages like strong gradient flow, parameter efficiency, and low complexity while performing well on various image recognition tasks.








![13 / 21
Compression
●
To further improve model compactness, the number
of feature-maps is reduced at transition layers.
●
If a dense block contains m feature-maps, we let
the following transition layer generate [θm] output
feature maps, where 0 < θ ≤1 is referred to as the
compression factor.](https://image.slidesharecdn.com/ppt-210410130657/85/Densenet-CNN-13-320.jpg)