Downloaded 199 times












![Additional resources
● Lluis Castrejon, “Domain adaptation and zero-shot learning”. University of
Toronto 2016.
● Hoffman, J., Guadarrama, S., Tzeng, E. S., Hu, R., Donahue, J., Girshick, R., ... & Saenko, K. (2014). LSDA: Large scale
detection through adaptation. NIPS 2014. (Slides by Xavier Giró-i-Nieto)
● Yosinski, Jason, Jeff Clune, Yoshua Bengio, and Hod Lipson. "How transferable are features in deep neural
networks?." In Advances in Neural Information Processing Systems, pp. 3320-3328. 2014.
● Shao, Ling, Fan Zhu, and Xuelong Li. "Transfer learning for visual categorization: A survey." Neural Networks and
Learning Systems, IEEE Transactions on 26, no. 5 (2015): 1019-1034.
● Chen, Tianqi, Ian Goodfellow, and Jonathon Shlens. "Net2Net: Accelerating Learning via Knowledge Transfer." ICLR
2016. [code] [Notes by Hugo Larrochelle
● Gani, Yaroslav, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario
Marchand, and Victor Lempitsky. "Domain-Adversarial Training of Neural Networks." arXiv preprint arXiv:1505.07818
(2015).
24](https://image.slidesharecdn.com/dlmmdcud2l04transfer-170429105218/75/Transfer-Learning-D2L4-Insight-DCU-Machine-Learning-Workshop-2017-24-2048.jpg)

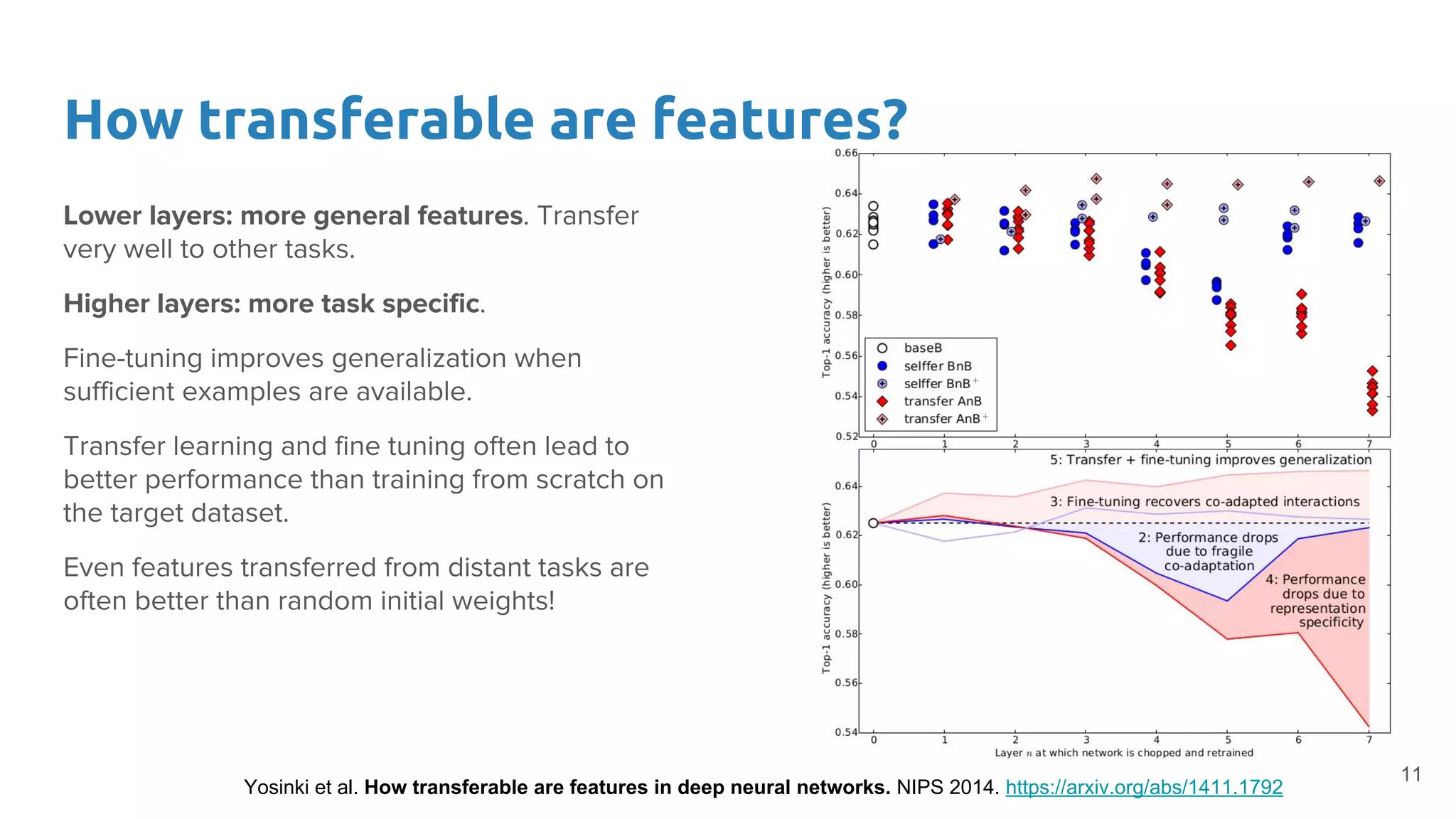
The document discusses the concept of transfer learning and its applications in deep learning, specifically addressing the misconception that millions of labeled examples are necessary for effective training. It highlights methods such as using pre-trained models, fine-tuning network layers, and unsupervised domain adaptation to improve performance, even with limited data. Additionally, it concludes that lower layers of neural networks contain more general features that are transferable across tasks, while higher layers are more task-specific.
Kevin McGuinness introduces the Deep Learning Workshop, focusing on transfer learning techniques.
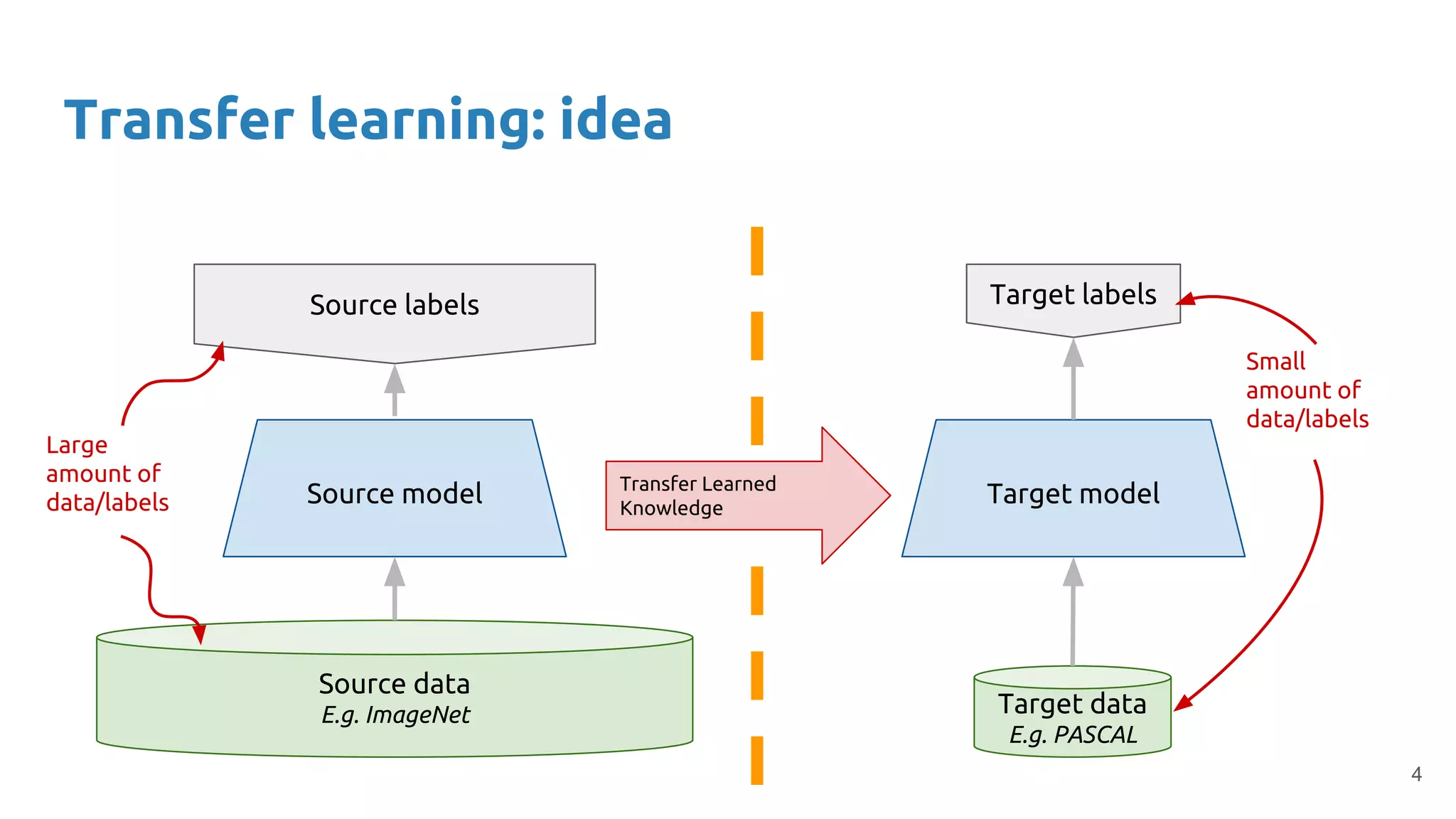
Transfer learning allows adaptation of pre-trained models to new tasks, leveraging unlabelled data and representations from related tasks.
Illustrates the use of a model (e.g., ImageNet) and how it can aid in training models for different tasks with limited data.
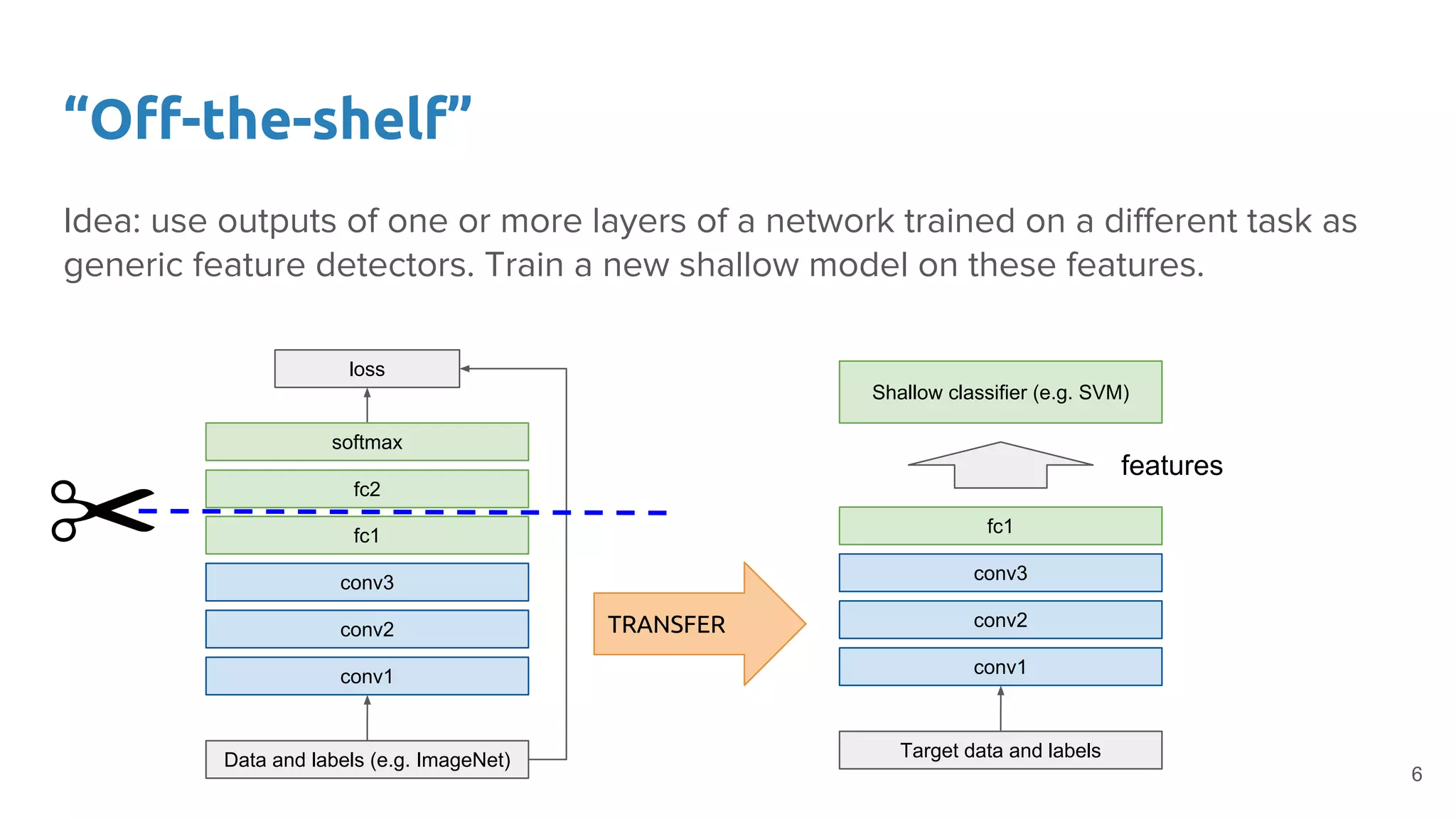
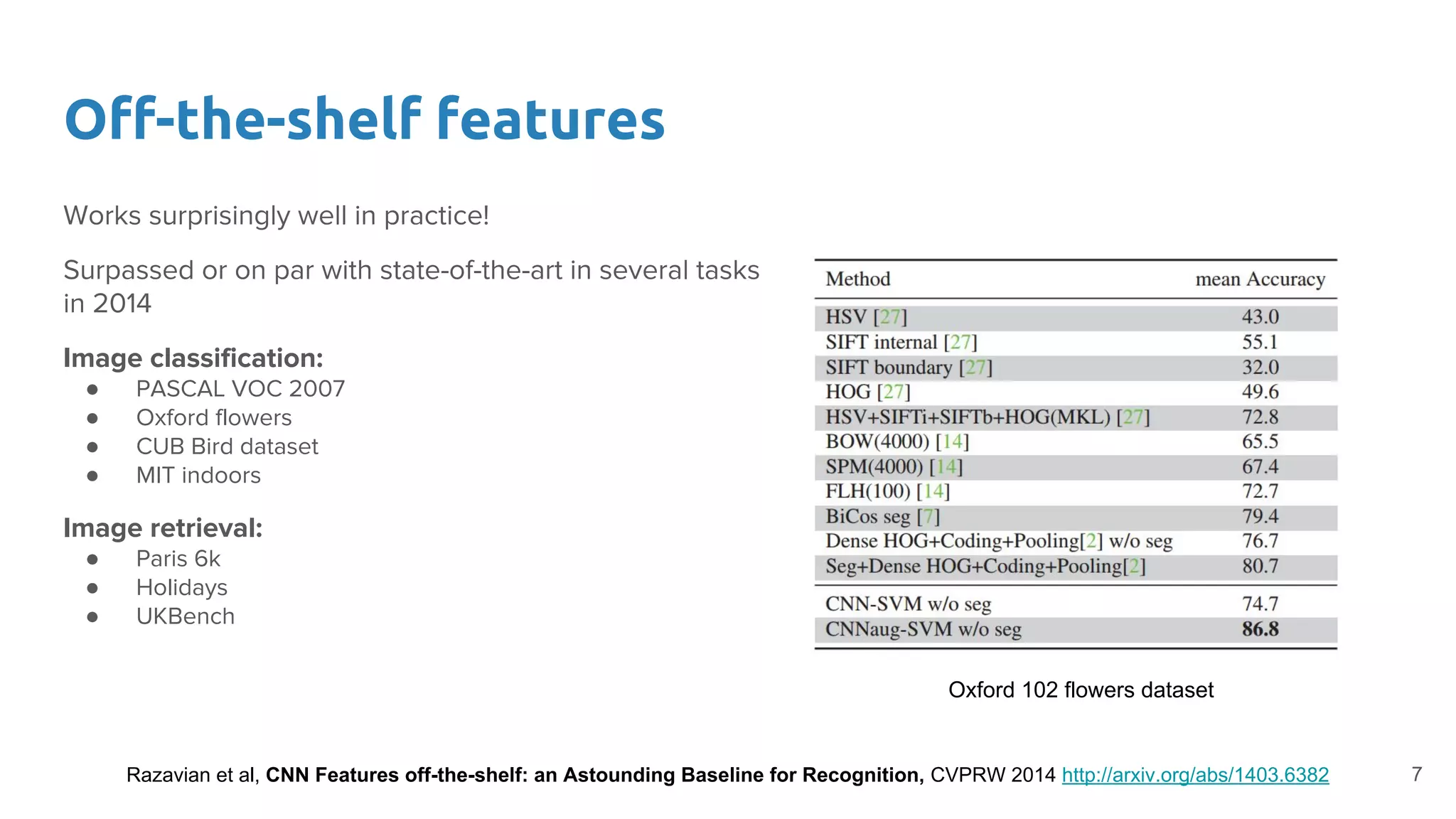
Explains the concept of using features from pre-trained networks as effective detectors in new tasks, leading to impressive results.
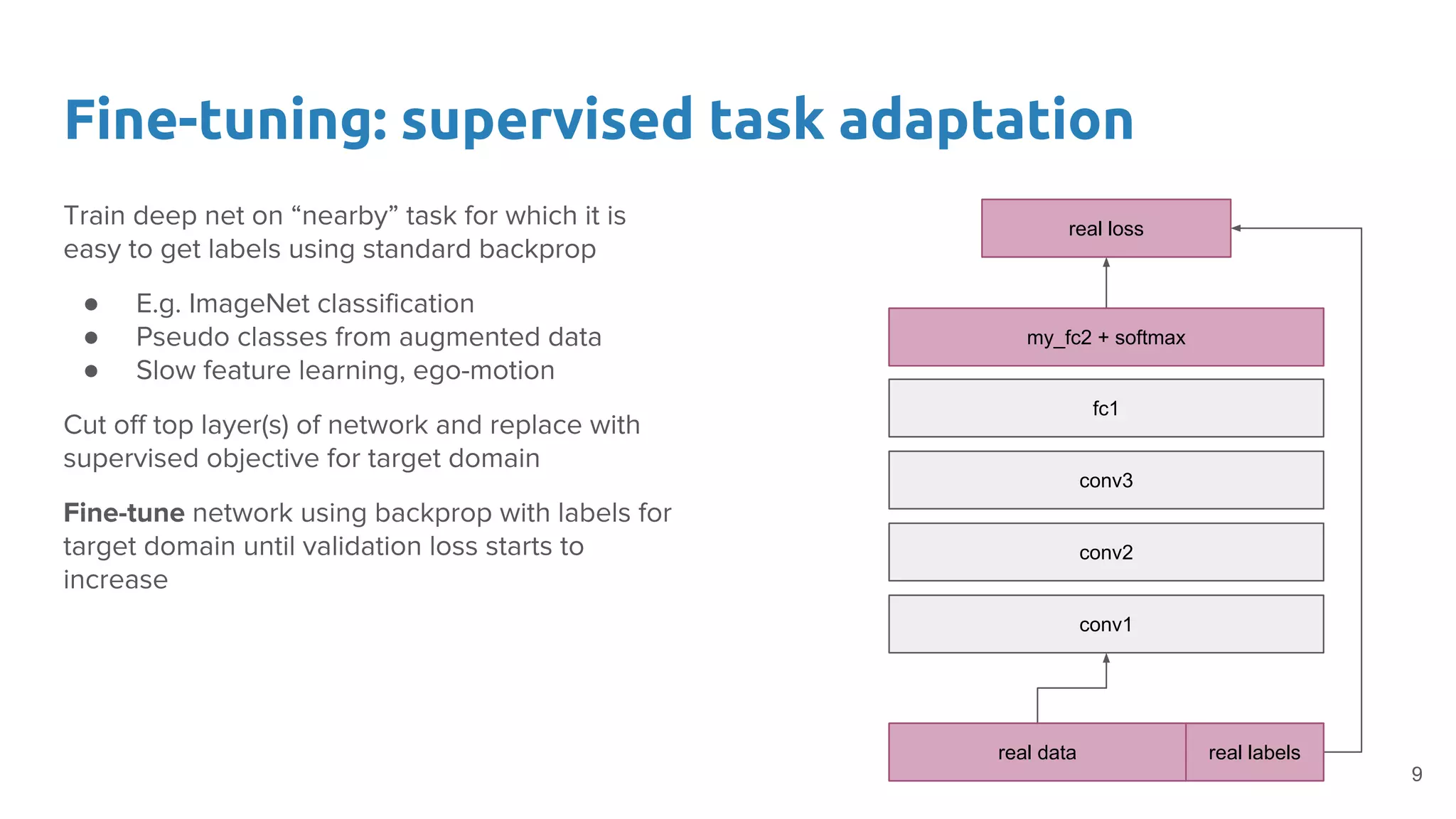
Discusses fine-tuning techniques for adapting deep networks for specific tasks and the importance of layer-specific adjustments.
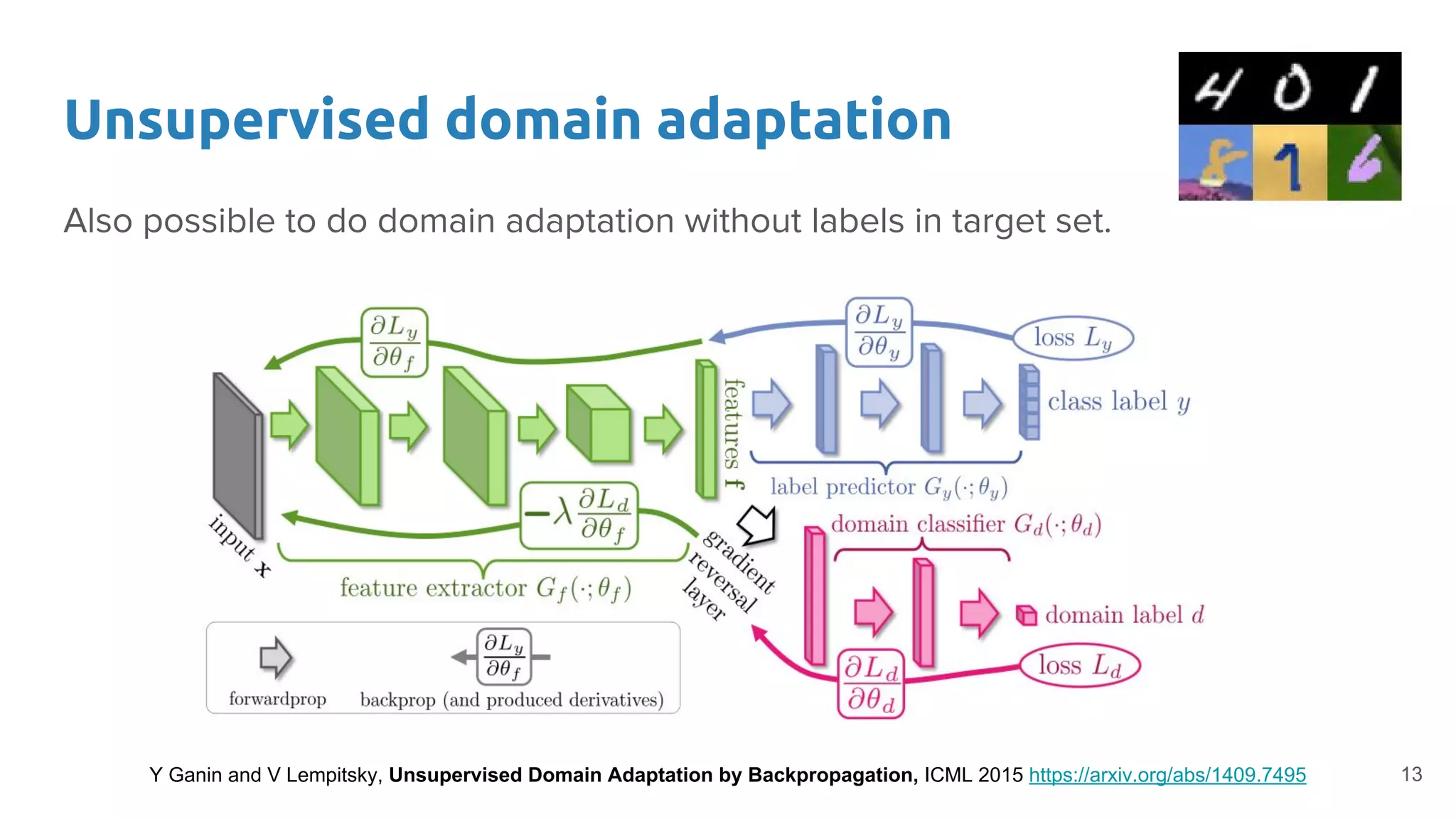
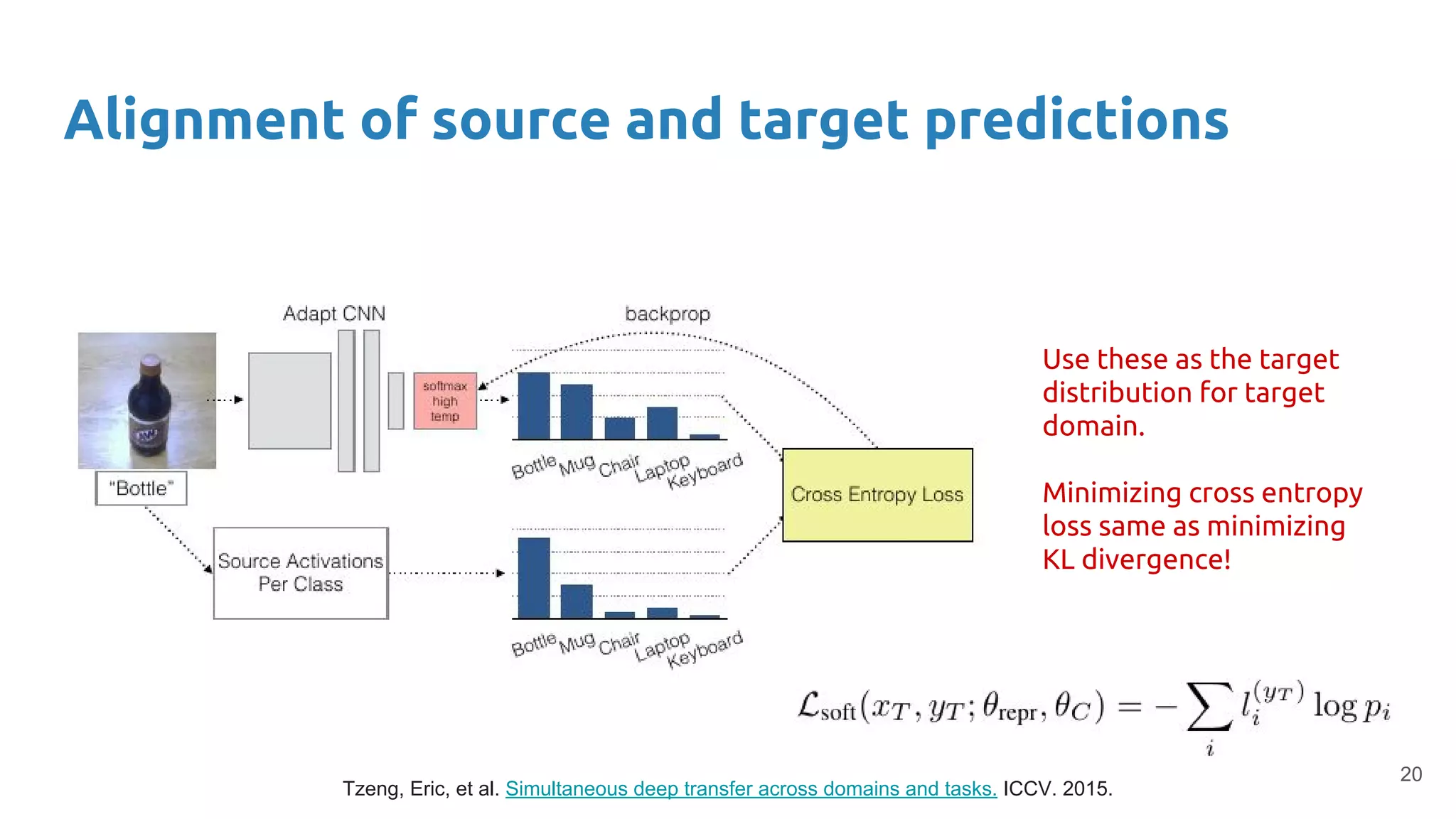
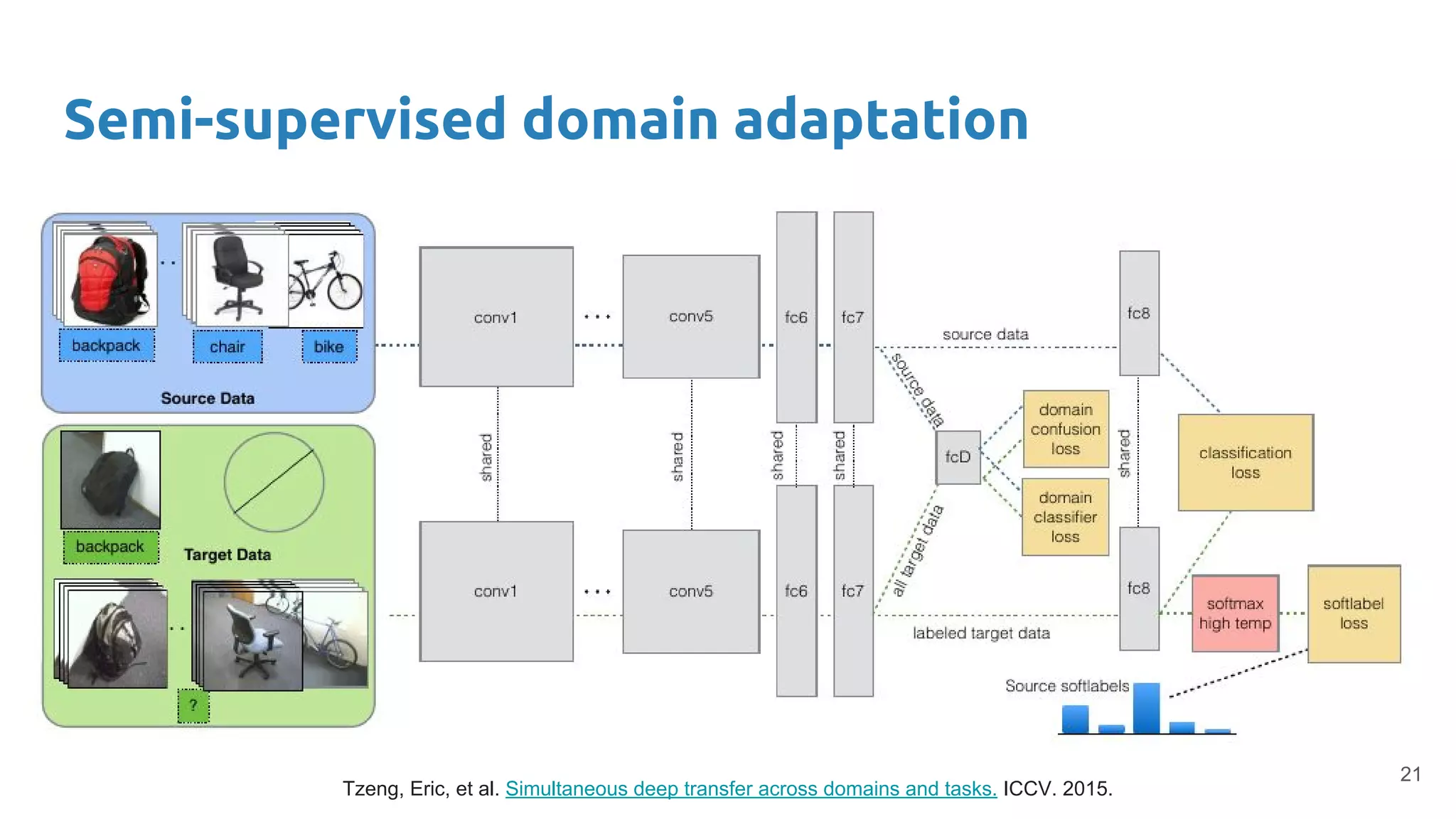
Describes methods for adapting models to new domains without label information, enhancing model applicability.
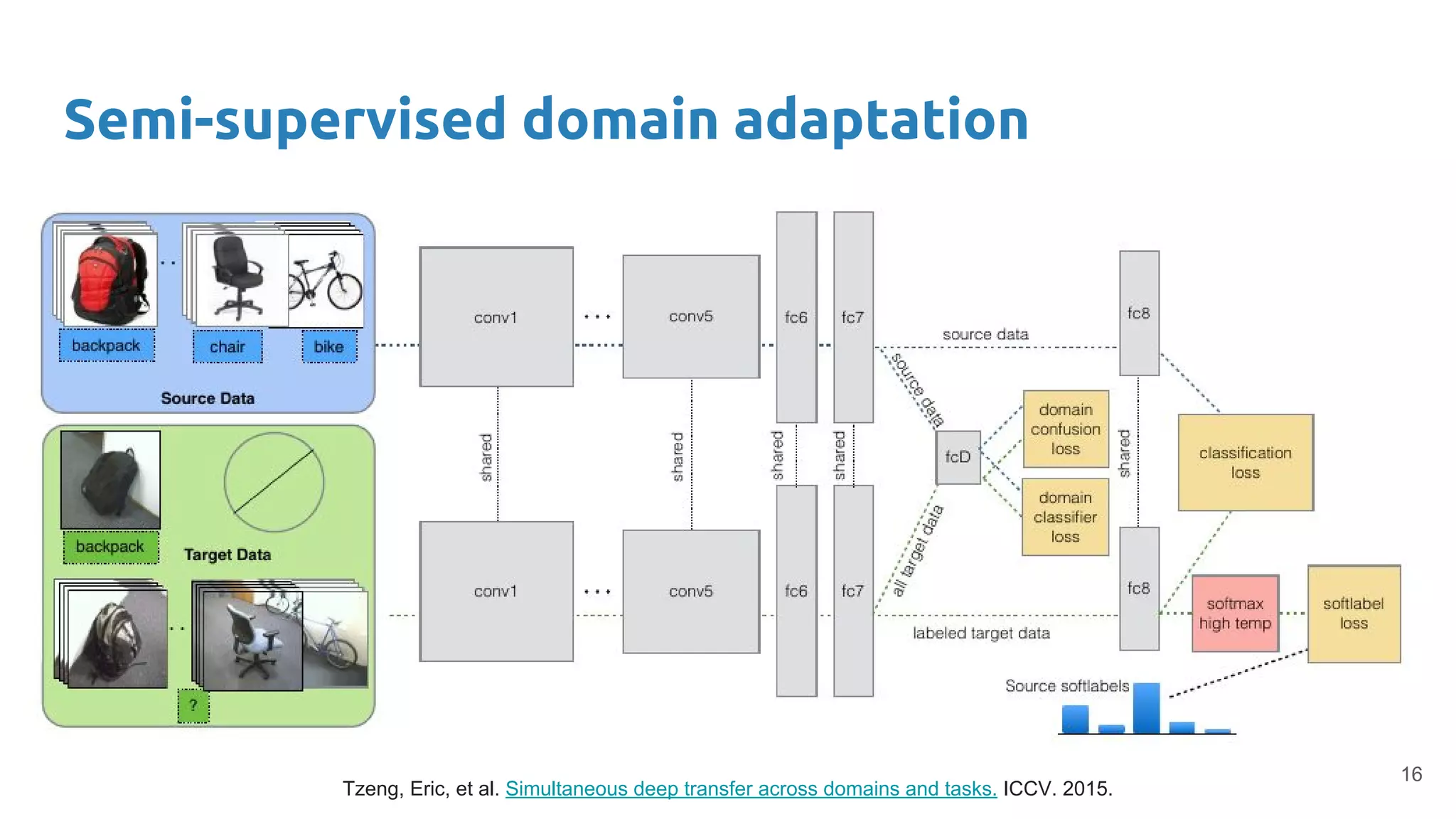
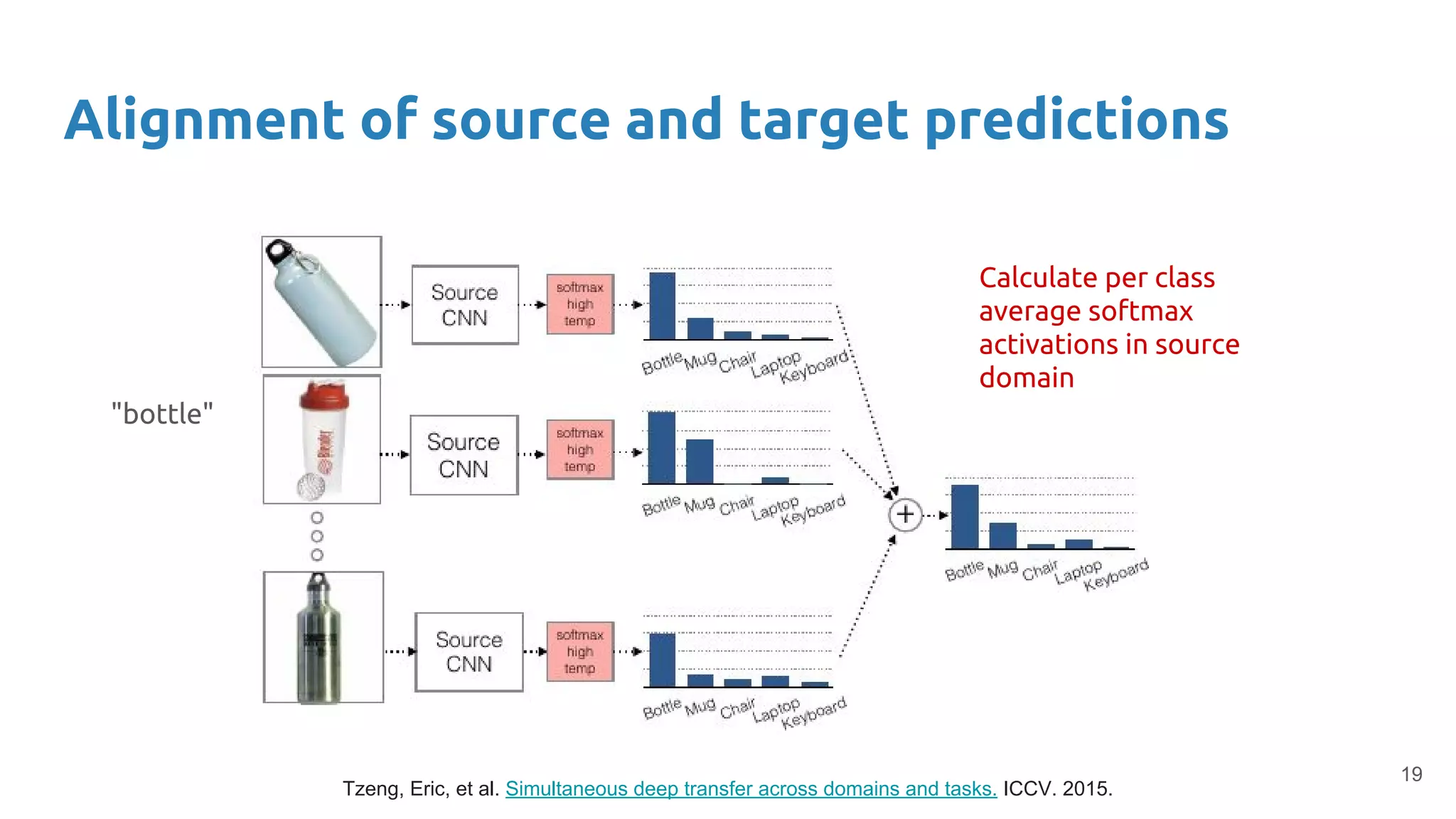
Combines fine-tuning with unsupervised domain adaptation strategies to optimize classifier accuracy and interpretability across domains.
Summarizes the workshop teachings on transfer learning, indicating its effectiveness for training large models on small datasets.
An open floor for questions to clarify concepts discussed during the workshop.
Provides resources for further reading on domain adaptation and transfer learning methodologies.






















































































