Download as PDF, PPTX


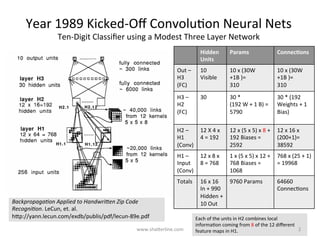
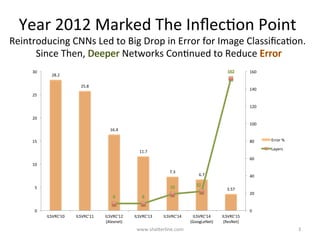




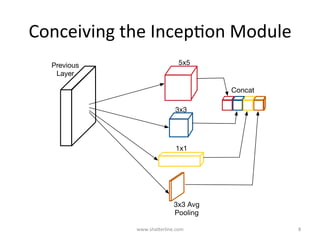
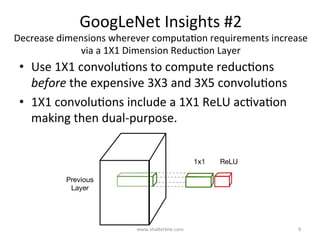
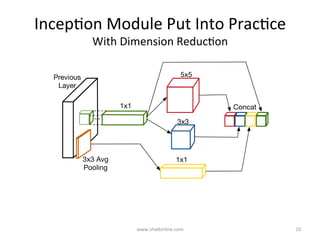

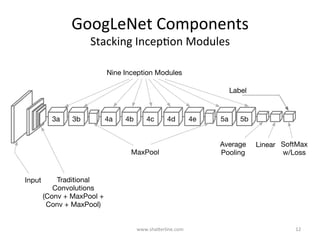

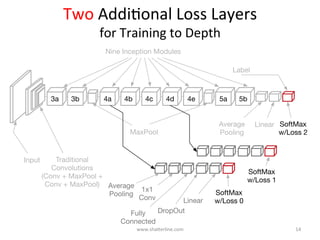



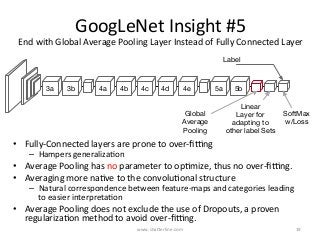



GoogLeNet introduced several key insights for designing efficient deep learning networks: 1. Exploit local correlations in images by concatenating 1x1, 3x3, and 5x5 convolutions along with pooling. 2. Decrease dimensions before expensive convolutions using 1x1 convolutions for dimension reduction. 3. Stack inception modules upon each other, occasionally inserting max pooling layers, to allow tweaking each module. 4. Counter vanishing gradients with intermediate losses added to the total loss for training deep networks. 5. End with a global average pooling layer instead of fully connected layers to avoid overfitting.









































































