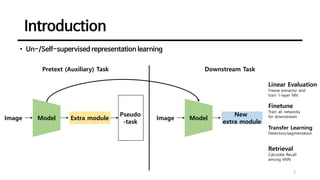
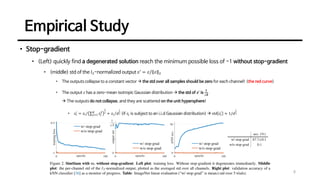
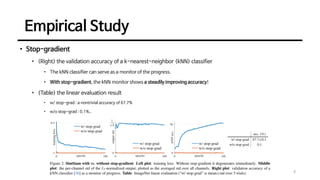
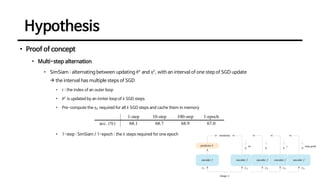
This document discusses an unsupervised representation learning method called SimSiam. It proposes that SimSiam can be interpreted as an expectation-maximization algorithm that alternates between updating the encoder parameters and assigning representations to images. Key aspects discussed include how the stop-gradient operation prevents collapsed representations, the role of the predictor network, effects of batch size and batch normalization, and alternatives to the cosine similarity measure. Empirical results show that SimSiam learns meaningful representations without collapsing, and the various design choices affect performance but not the ability to prevent collapsed representations.