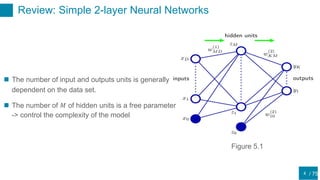
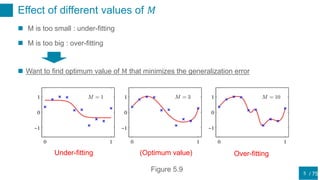
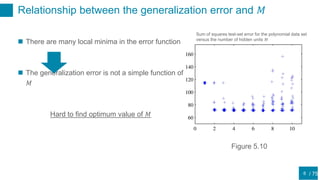
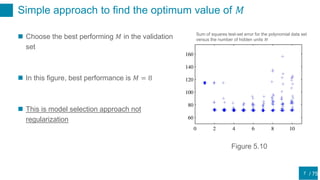
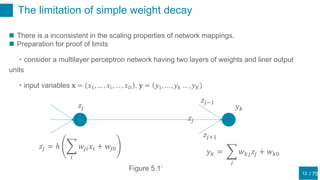
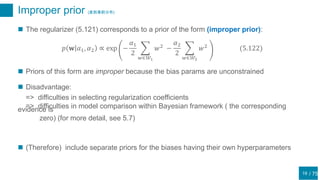
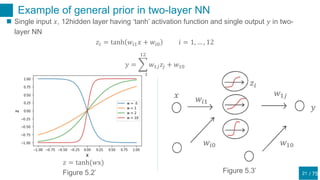
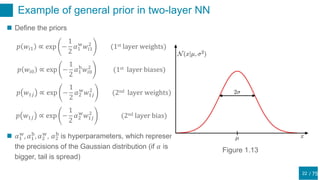
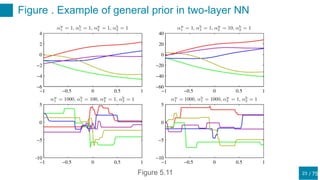
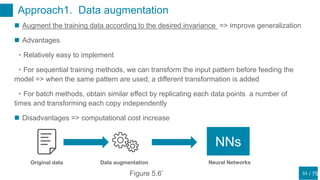
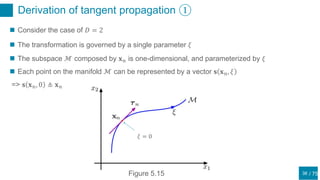
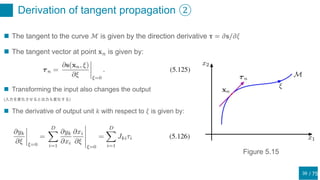
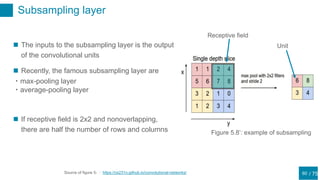
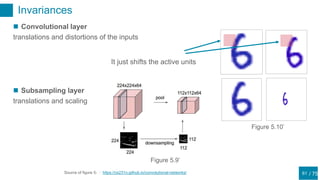
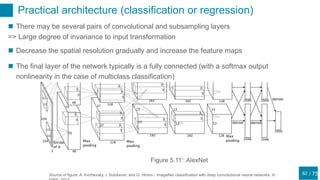
This document discusses regularization techniques for neural networks to prevent overfitting. It describes how the number of hidden units controls complexity and can lead to underfitting or overfitting. Early stopping is introduced as an alternative to regularization where training is stopped when validation error starts to increase. Consistency of regularization terms under linear transformations of data is discussed. Different approaches for building invariances like data augmentation, tangent propagation, and convolutional network structures are outlined.





































![/ 75
Formulation of data augmentation ⑤
51
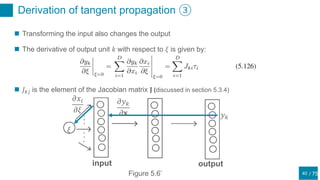
The function that minimizes the sum-of-squares error is the conditional mean 𝐸[𝑡|𝐱]
(5.131) is the original sum-of-squares-error plus terms of 𝑂(𝜉2
)
Therefore, the model function that minimizes the (5.131) will have the form:
For 𝑂 𝜉2
, the first term of the regularization term Ω is zero
Thus, regularization term Ω can be written by:](https://image.slidesharecdn.com/prml20205-5shitomi-200919081357/85/PRML-5-5-51-320.jpg)








![/ 75
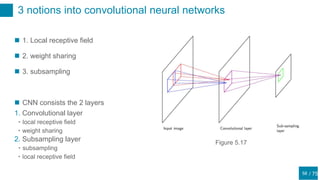
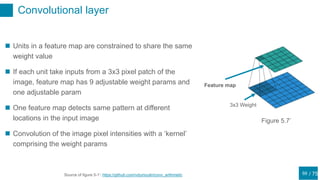
Problem of weight sharing
65
Weight sharing technique (Section 5.5.6)
=>Add the constraint that weights belonging to the same
groups are equal
“This approach is effective when the problem being
addressed is quite well understood, so that it is possible
to specify, in advance, which weights should be
identical.”[1]
e.g.) Consider the recognizing handwritten digits, wealready
know the some invariances
[1]. Nowlan, S.J. and G.E. Hinton,: Simplifying neural networks by soft weight sharing. Neural Computation 4(4), 473-
Figure 5.17
We know that we should share the weights each ker
Soft weight sharing
If we don’t know the where we should share the weights](https://image.slidesharecdn.com/prml20205-5shitomi-200919081357/85/PRML-5-5-65-320.jpg)






























![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)









































