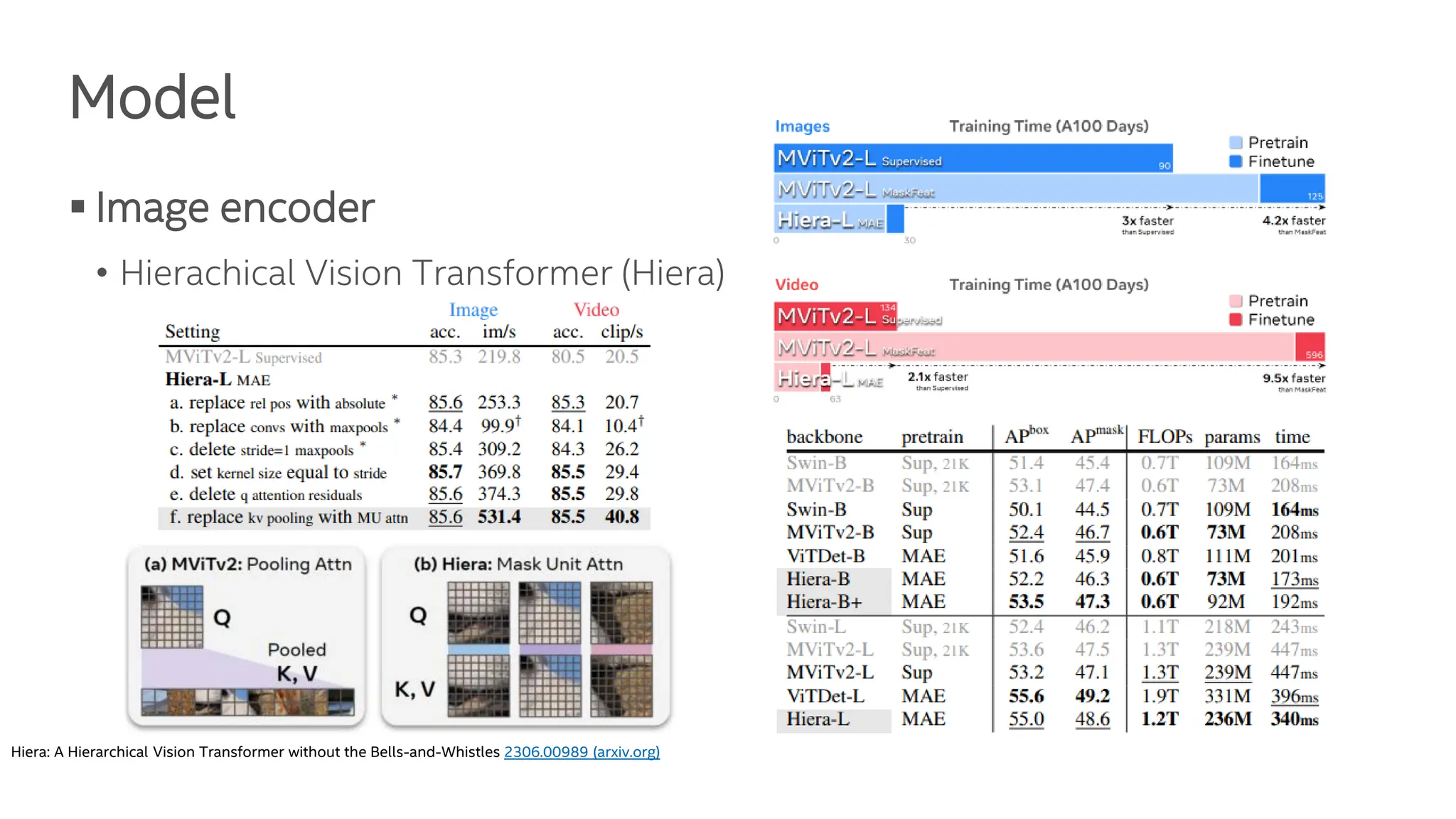
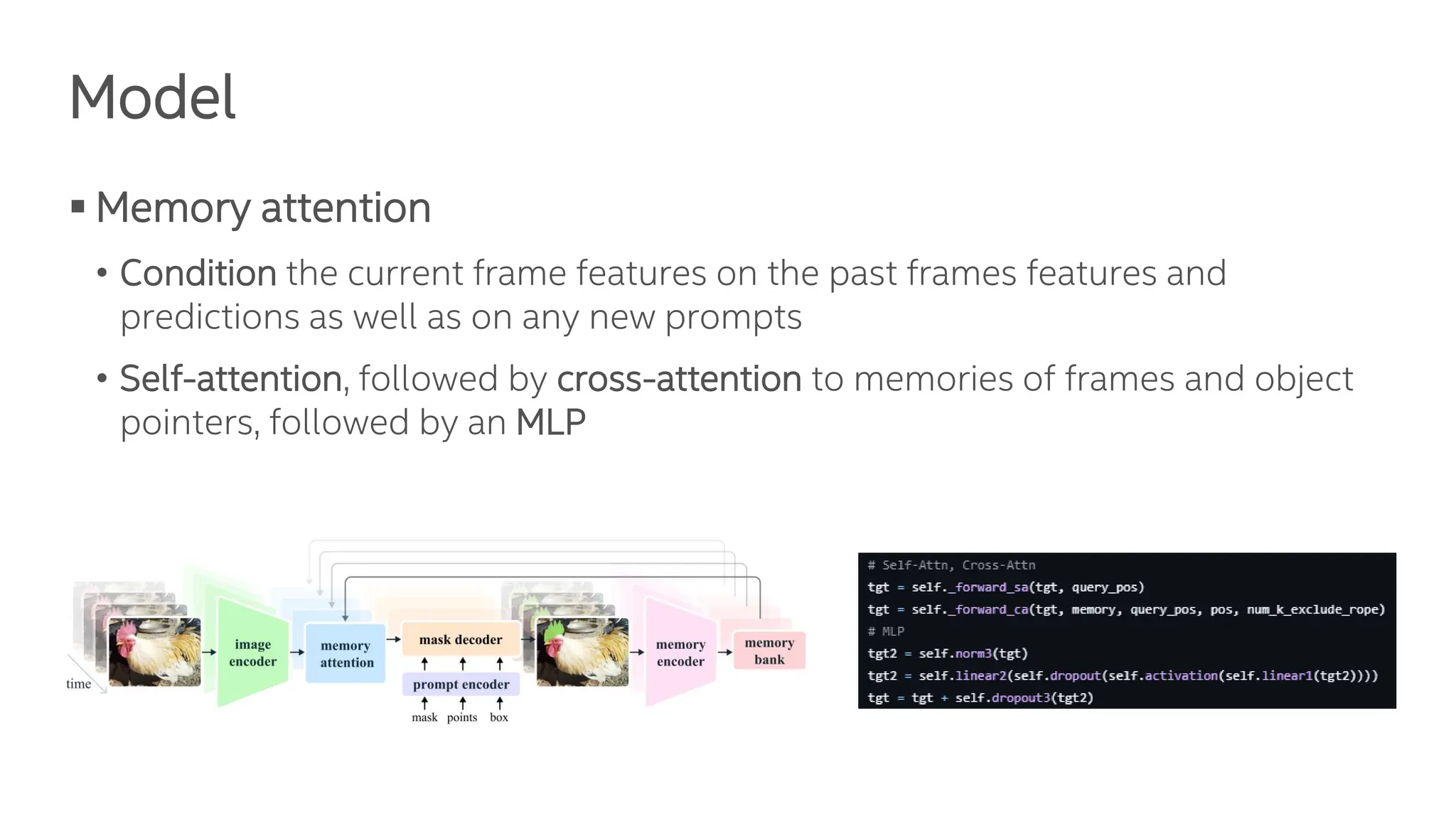
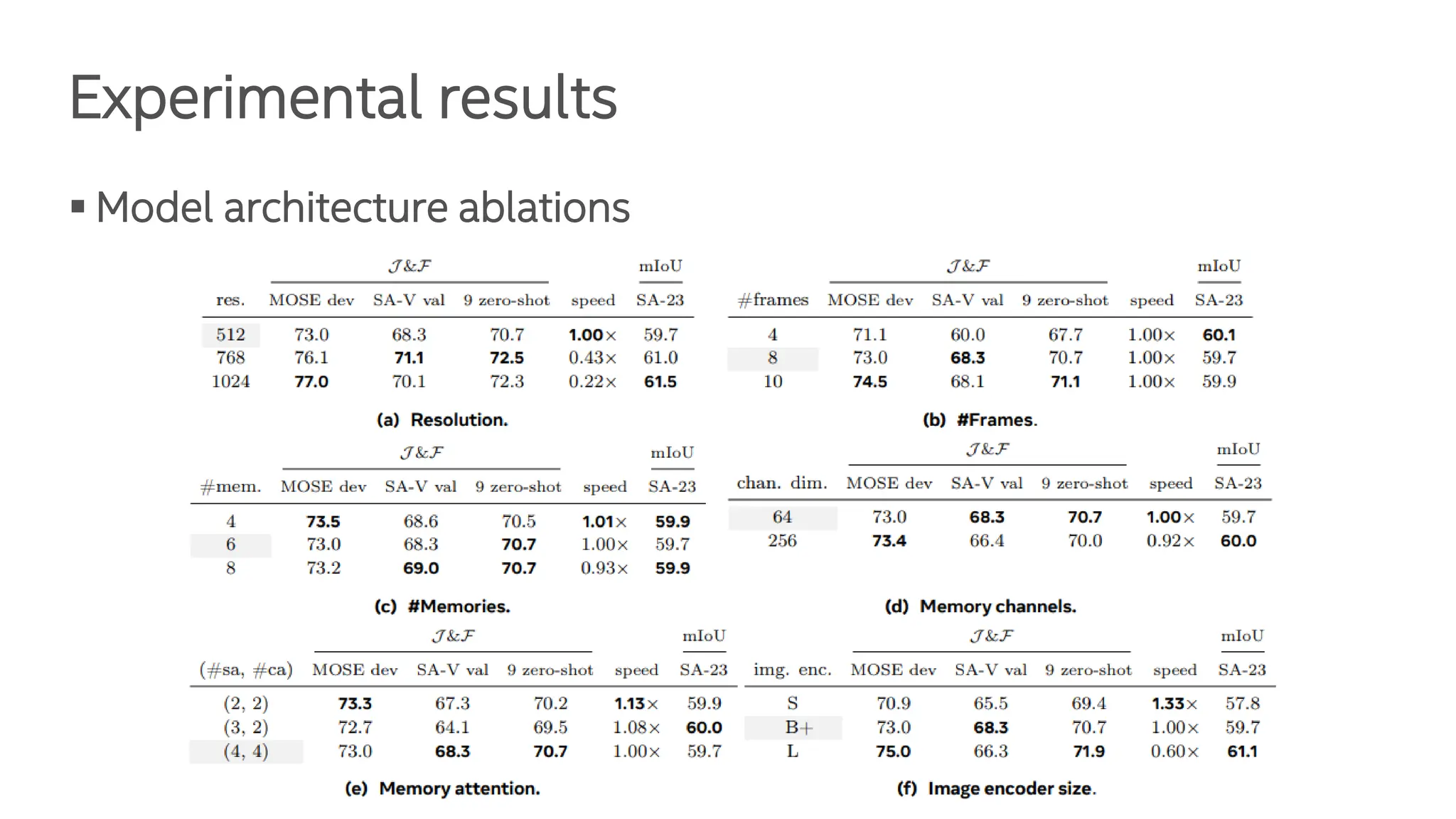
The document presents the Segment Anything Model 2 (SAM 2), a unified framework for promptable visual segmentation in videos and images. It details the architecture including memory attention, various image encoders, and the role of a memory bank in retaining past predictions. Additionally, it discusses training methodologies and experimental results highlighting SAM 2's performance on tasks like promptable video segmentation.






















































![[212]big models without big data using domain specific deep networks in data-...](https://cdn.slidesharecdn.com/ss_thumbnails/212bigmodelswithoutbigdatausingdomain-specificdeepnetworksindata-scarcesettings-171017003514-thumbnail.jpg?width=640&height=640&fit=bounds)















































