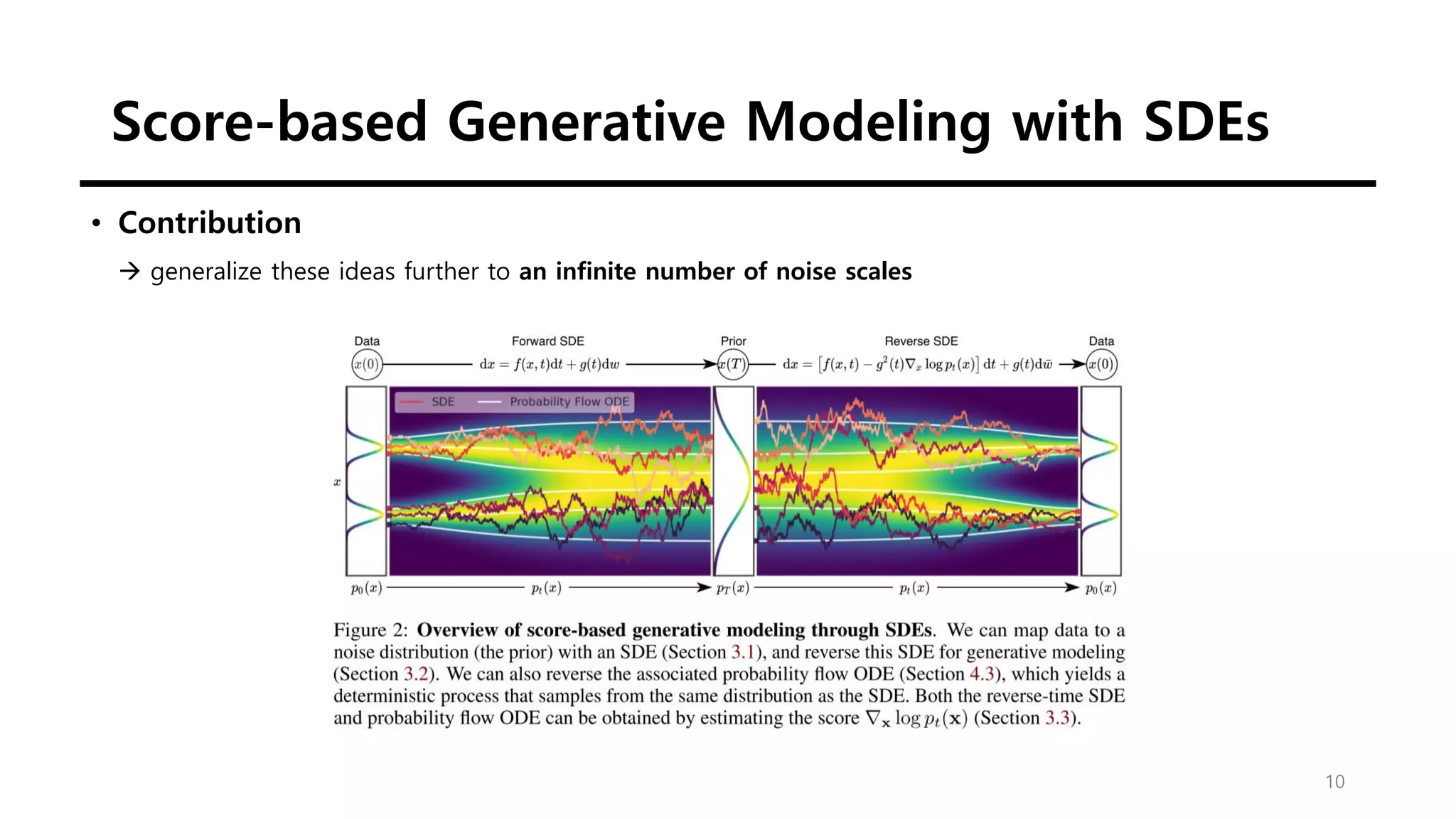
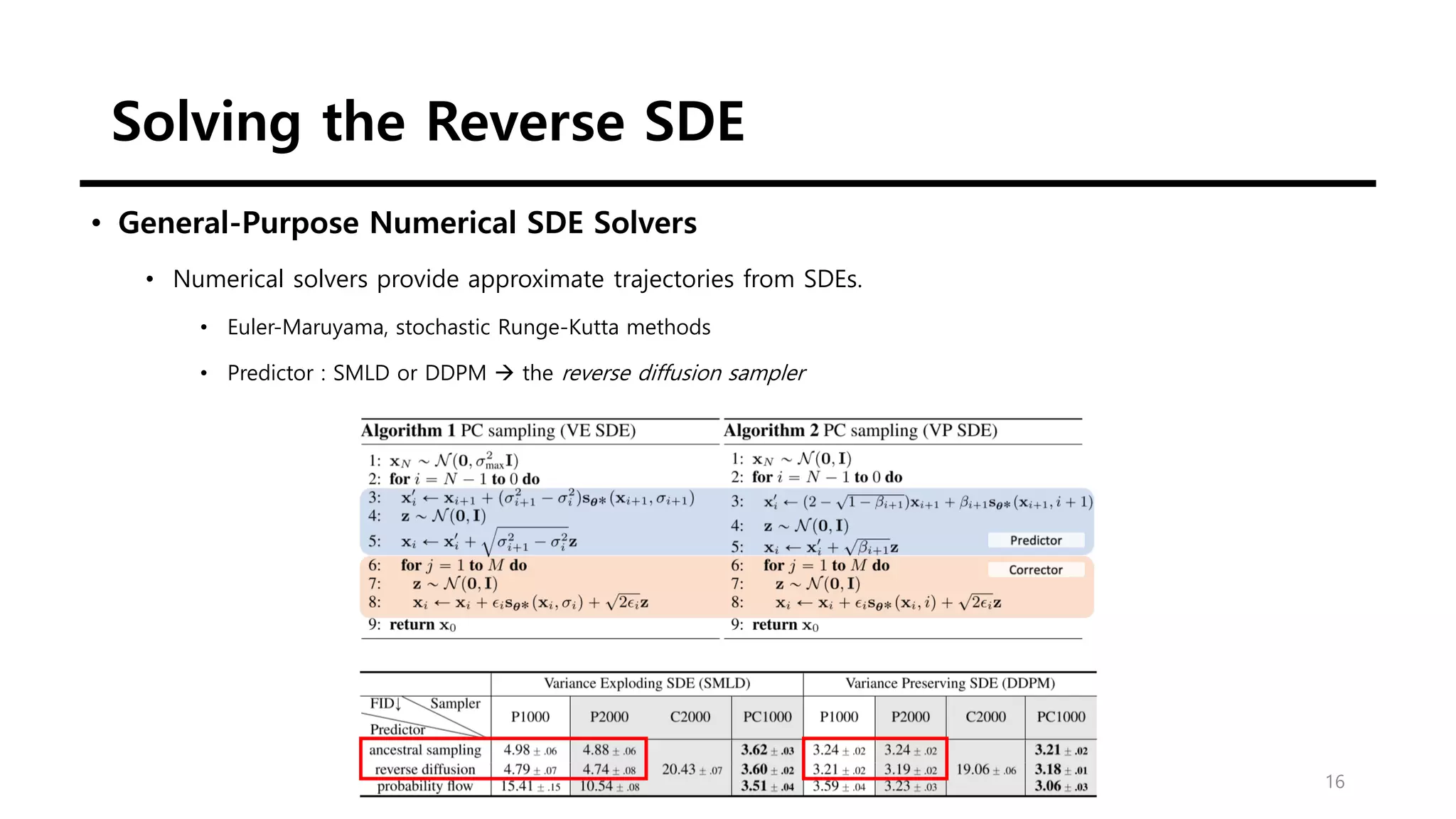
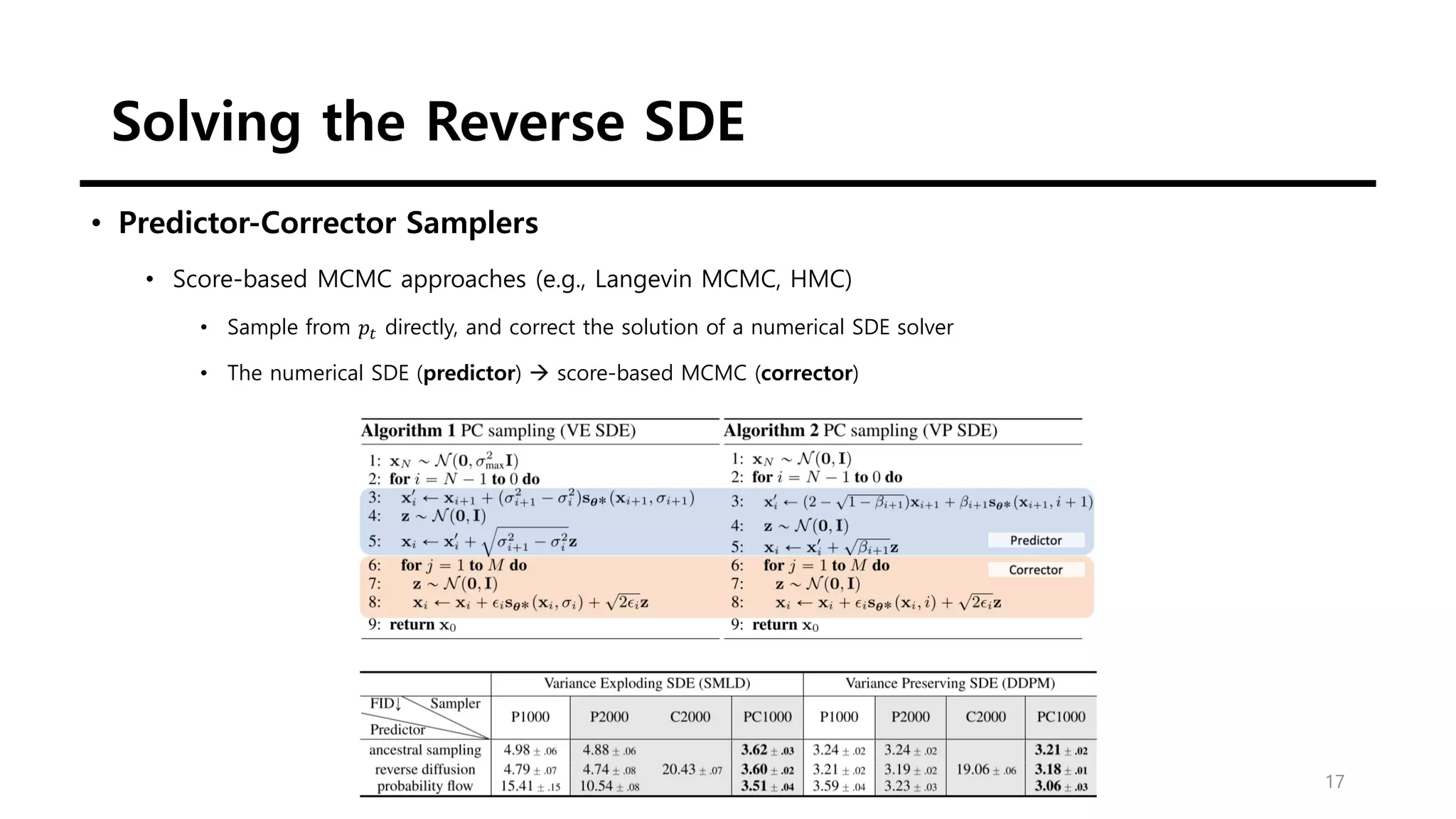
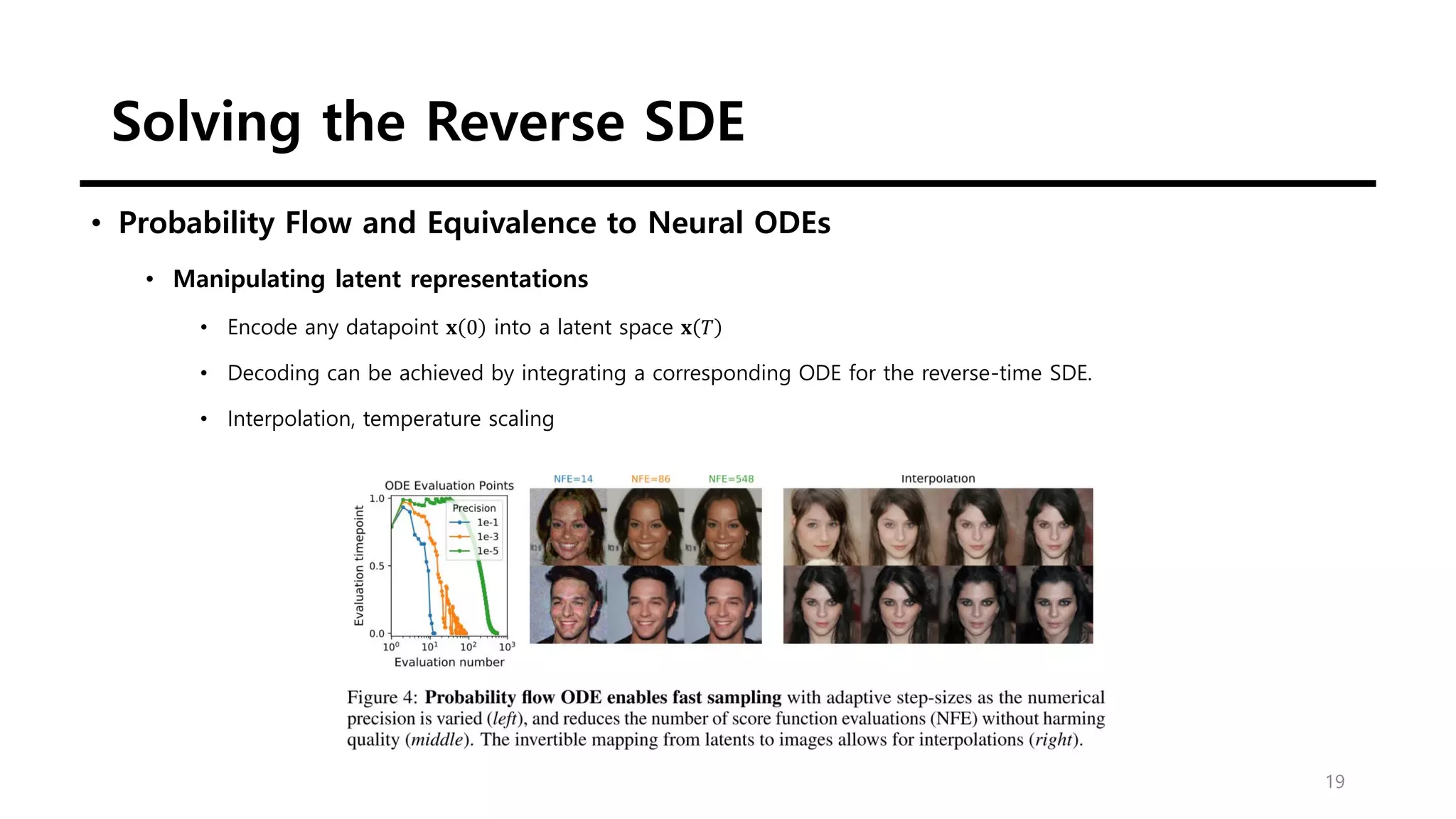
This document discusses score-based generative modeling using stochastic differential equations (SDEs). It introduces modeling data diffusion as an SDE from the data distribution to a simple prior and generating samples by reversing this diffusion process. It also describes estimating the score (gradient of the log probability density) needed for the reverse process using score matching. Finally, it notes that noise perturbation models like NCSN and DDPM can be viewed as discretizations of specific SDEs called variance exploding and variance preserving SDEs.



























![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Ridge-i 論文よみかい] Wasserstein auto encoder](https://cdn.slidesharecdn.com/ss_thumbnails/wassersteinauto-encoder-181006055019-thumbnail.jpg?width=640&height=640&fit=bounds)







































































