This document provides an outline and overview of training convolutional neural networks. It discusses update rules like stochastic gradient descent, momentum, and Adam. It also covers techniques like data augmentation, transfer learning, and monitoring the training process. The goal of training a CNN is to optimize its weights and parameters to correctly classify images from the training set by minimizing output error through backpropagation and updating weights.









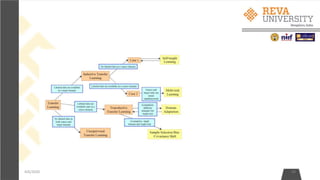
![The CNN Training Process
• Parameters - Number of filters, filter sizes, architecture of the network etc.
are fixed before Step 1 and do not change during training process – only
the values of the filter matrix and connection weights get updated.
• Step1: Initialize all filters and parameters / weights with random values.
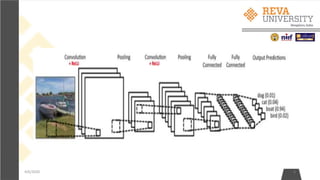
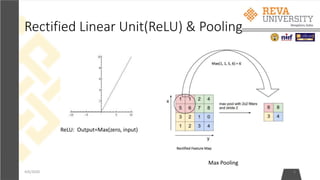
• Step2: The network takes a training image as input, goes through the
forward propagation step (convolution, ReLU and pooling operations, the
Fully Connected layer) and finds the output probabilities for each class.
• Lets say the output probabilities for the boat image above are [0.3, 0.3, 0.1, 0.2,0.1]
• Since weights are randomly assigned for the first training example, output
probabilities are also random.
4/6/2020 11](https://image.slidesharecdn.com/nimritafdp-200801055625/85/Deeplearning-11-320.jpg)

![• The weights are adjusted in proportion to their contribution to the total error.
• When the same image is input again, output probabilities might now be [0.6,
0.1, 0.1, 0.1,0.1], which is closer to the target vector [1, 0, 0,0, 0].
• This means that the network has learnt to classify this particular image
correctly by adjusting its weights / filters such that the output error is
reduced.
4/6/2020 13](https://image.slidesharecdn.com/nimritafdp-200801055625/85/Deeplearning-13-320.jpg)








![4/6/2020 22
SGD + momentum:
•Build up velocity as a running mean of gradients:
•# Computing weighted average. rho best is in range [0.9 - 0.99] V[t+1] = rho * v[t] + dx x[t+1] = x[t] - learningRate * V[t+1]
•V[0] is zero.
•Solves the saddle point and local minimum problems.
•It overshoots the problem and returns to it back.](https://image.slidesharecdn.com/nimritafdp-200801055625/85/Deeplearning-22-320.jpg)


![• Data augmentation:Another technique that makes Regularization.
• Change the data!
• For example flip the image, or rotate it.
• Example in ResNet:
• Training: Sample random crops and scales:
• Pick random L in range [256,480]
• Resize training image, short side = L
• Sample random 224x244 patch.
• Testing: average a fixed set of crops
• Resize image at 5 scales: {224, 256, 384, 480, 640}
• For each size, use 10 224x224 crops: 4 corners + center + flips
• Apply Color jitter or PCA
• Translation, rotation, stretching.
4/6/2020 27](https://image.slidesharecdn.com/nimritafdp-200801055625/85/Deeplearning-27-320.jpg)







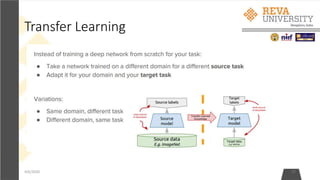

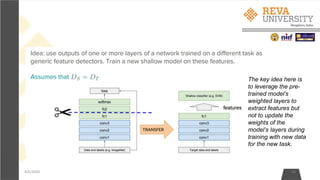
![Practical advice for Transfer Learning
4/6/2020 39
• Constraints from pretrained models. Note that if you wish to use a pretrained network,
you may be slightly constrained in terms of the architecture you can use for your new
dataset. For example, you can't arbitrarily take out Conv layers from the pretrained
network. However, some changes are straight-forward: Due to parameter sharing, you
can easily run a pretrained network on images of different spatial size. This is clearly
evident in the case of Conv/Pool layers because their forward function is independent of
the input volume spatial size (as long as the strides "fit"). In case of FC layers, this still
holds true because FC layers can be converted to a Convolutional Layer: For example, in
an AlexNet, the final pooling volume before the first FC layer is of size [6x6x512].
Therefore, the FC layer looking at this volume is equivalent to having a Convolutional
Layer that has receptive field size 6x6, and is applied with padding of 0.
• Learning rates. It's common to use a smaller learning rate for ConvNet weights that are
being fine-tuned, in comparison to the (randomly-initialized) weights for the new linear
classifier that computes the class scores of your new dataset. This is because we expect
that the ConvNet weights are relatively good, so we don't wish to distort them too
quickly and too much (especially while the new Linear Classifier above them is being
trained from random initialization).](https://image.slidesharecdn.com/nimritafdp-200801055625/85/Deeplearning-39-320.jpg)