The document discusses principles and techniques for exploratory data analysis including:
1) Showing comparisons, causality, and systematic structure through data visualization principles.
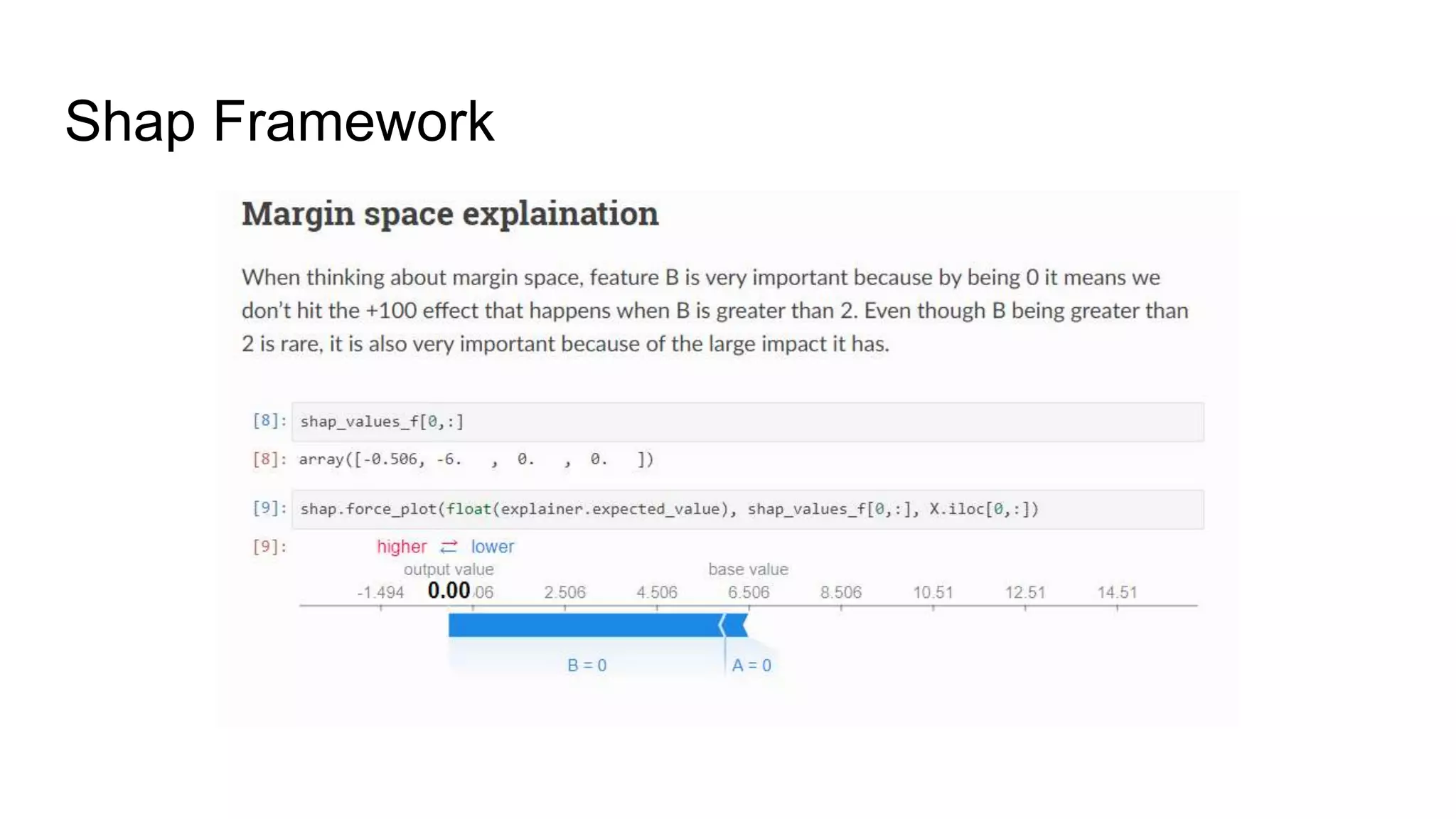
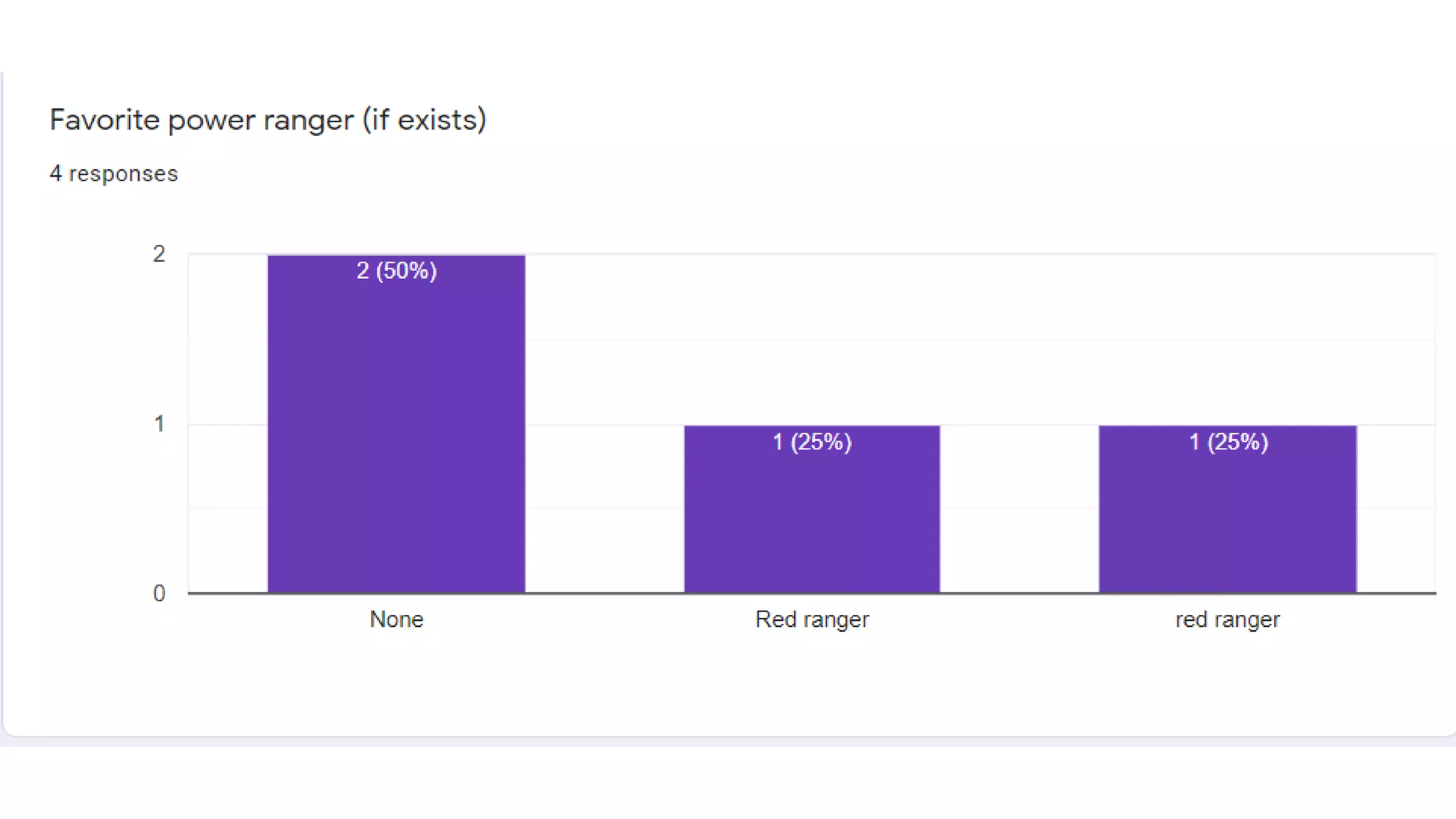
2) Creating one dimensional and two dimensional plots like scatter plots to understand data properties and find patterns.
3) Using base plotting systems, lattice systems, and ggplot2 systems which offer different levels of customization for creating plots.
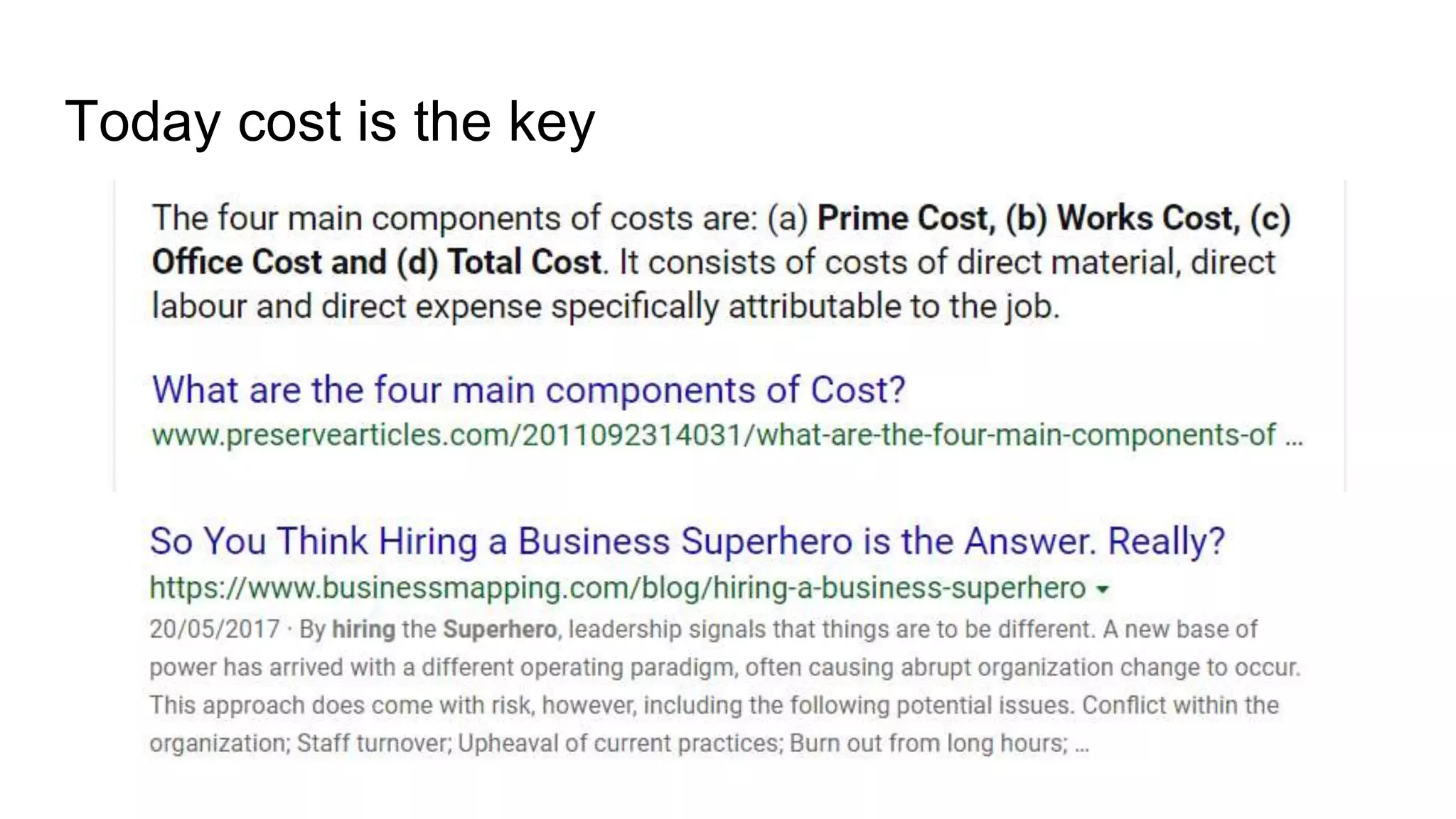
4) Addressing issues like scaling, cost, and clustering when analyzing exploratory data.