More Related Content

PDF

PPTX

PDF
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant... 
PDF
【DL輪読会】マルチエージェント強化学習における近年の 協調的方策学習アルゴリズムの発展 ![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法 
PDF
What's hot

PDF
【論文調査】XAI技術の効能を ユーザ実験で評価する研究 
PDF
深層学習の不確実性 - Uncertainty in Deep Neural Networks - 
PDF

PDF
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an... 
PDF

PDF

PDF
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem... 
PPTX
Curriculum Learning (関東CV勉強会) 
PDF

PDF

PPTX
近年のHierarchical Vision Transformer 
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ 
PPTX

PDF

PDF
![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー... 
PDF

PDF
Transformerを多層にする際の勾配消失問題と解決法について 
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演) More from Ryutaro Yamauchi

PPTX

PPTX

PPTX
![[論文解説]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/0123bayes-180123100528-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[論文解説]A Bayesian Perspective on Generalization and Stochastic Gradient Descent ![[論文解説]Unsupervised monocular depth estimation with Left-Right Consistency](https://cdn.slidesharecdn.com/ss_thumbnails/unsupervisedmonoculardepthestimation-170809092538-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[論文解説]Unsupervised monocular depth estimation with Left-Right Consistency 
PPTX
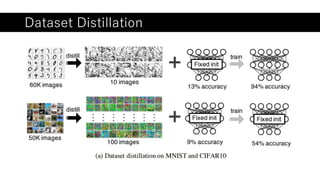
Hybrid computing using a neural network with dynamic [DeepLearning論文読み会] Dataset Distillation
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.