Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Masayoshi Kondo
491 views
深層学習(岡本孝之 著) - Deep Learning chap.3_1
深層学習(岡本孝之 著)の3章まとめ前半.これから深層学習を学びたい理系B4, M1向けの入門資料.実用目的よりも用語説明含めた基礎知識重視.
Data & Analytics
◦
Related topics:
Deep Learning
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 14 times
1
/ 23
2
/ 23
3
/ 23
4
/ 23
5
/ 23
6
/ 23
7
/ 23
8
/ 23
9
/ 23
10
/ 23
11
/ 23
12
/ 23
13
/ 23
14
/ 23
15
/ 23
16
/ 23
17
/ 23
18
/ 23
19
/ 23
20
/ 23
21
/ 23
22
/ 23
23
/ 23
More Related Content
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PDF
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
PDF
深層学習(岡本孝之 著)Deep learning Chap.4_2
by
Masayoshi Kondo
PDF
深層学習(岡本孝之著) Deep learning chap.5_2
by
Masayoshi Kondo
PDF
深層学習(岡本孝之 著) - Deep Learning chap.3_2
by
Masayoshi Kondo
PDF
深層学習(岡本 孝之 著)Deep learning chap.5_1
by
Masayoshi Kondo
PDF
attention_is_all_you_need_nips17_論文紹介
by
Masayoshi Kondo
PDF
Linguistic Knowledge as Memory for Recurrent Neural Networks_論文紹介
by
Masayoshi Kondo
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
深層学習(岡本孝之 著)Deep learning Chap.4_2
by
Masayoshi Kondo
深層学習(岡本孝之著) Deep learning chap.5_2
by
Masayoshi Kondo
深層学習(岡本孝之 著) - Deep Learning chap.3_2
by
Masayoshi Kondo
深層学習(岡本 孝之 著)Deep learning chap.5_1
by
Masayoshi Kondo
attention_is_all_you_need_nips17_論文紹介
by
Masayoshi Kondo
Linguistic Knowledge as Memory for Recurrent Neural Networks_論文紹介
by
Masayoshi Kondo
What's hot
PDF
質問応答システム入門
by
Hiroyoshi Komatsu
PPTX
深層学習を用いた文生成モデルの歴史と研究動向
by
Shunta Ito
PDF
Active Learning 入門
by
Shuyo Nakatani
PDF
トピックモデルの話
by
kogecoo
PDF
Visualizing and understanding neural models in NLP
by
Naoaki Okazaki
PPTX
ニューラル機械翻訳の動向@IBIS2017
by
Toshiaki Nakazawa
PDF
LDA入門
by
正志 坪坂
PDF
Active Learning from Imperfect Labelers @ NIPS読み会・関西
by
Taku Tsuzuki
PDF
予測型戦略を知るための機械学習チュートリアル
by
Yuya Unno
PDF
4thNLPDL
by
Sho Takase
PPTX
Natural Language Processing (Almost) from Scratch(第 6 回 Deep Learning 勉強会資料; 榊)
by
Ohsawa Goodfellow
PPTX
Dilated rnn
by
naoto moriyama
PDF
Qaシステム解説
by
yayamamo @ DBCLS Kashiwanoha
PDF
Chainer with natural language processing hands on
by
Ogushi Masaya
PDF
Confidence Weightedで ランク学習を実装してみた
by
tkng
PDF
PostgreSQLの範囲型と排他制約
by
Akio Ishida
PPTX
Paper introduction "SCDV : Sparse Composite Document Vectors using soft clust...
by
TatsuroMiyamoto
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PDF
LDA等のトピックモデル
by
Mathieu Bertin
質問応答システム入門
by
Hiroyoshi Komatsu
深層学習を用いた文生成モデルの歴史と研究動向
by
Shunta Ito
Active Learning 入門
by
Shuyo Nakatani
トピックモデルの話
by
kogecoo
Visualizing and understanding neural models in NLP
by
Naoaki Okazaki
ニューラル機械翻訳の動向@IBIS2017
by
Toshiaki Nakazawa
LDA入門
by
正志 坪坂
Active Learning from Imperfect Labelers @ NIPS読み会・関西
by
Taku Tsuzuki
予測型戦略を知るための機械学習チュートリアル
by
Yuya Unno
4thNLPDL
by
Sho Takase
Natural Language Processing (Almost) from Scratch(第 6 回 Deep Learning 勉強会資料; 榊)
by
Ohsawa Goodfellow
Dilated rnn
by
naoto moriyama
Qaシステム解説
by
yayamamo @ DBCLS Kashiwanoha
Chainer with natural language processing hands on
by
Ogushi Masaya
Confidence Weightedで ランク学習を実装してみた
by
tkng
PostgreSQLの範囲型と排他制約
by
Akio Ishida
Paper introduction "SCDV : Sparse Composite Document Vectors using soft clust...
by
TatsuroMiyamoto
ノンパラベイズ入門の入門
by
Shuyo Nakatani
LDA等のトピックモデル
by
Mathieu Bertin
Similar to 深層学習(岡本孝之 著) - Deep Learning chap.3_1
PPTX
Deep learning chapter4 ,5
by
ShoKumada
PDF
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
PDF
Deep learning実装の基礎と実践
by
Seiya Tokui
PDF
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
PDF
20160329.dnn講演
by
Hayaru SHOUNO
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
PDF
ディープニューラルネット入門
by
TanUkkii
PDF
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
PPT
Deep Learningの技術と未来
by
Seiya Tokui
PDF
20150803.山口大学集中講義
by
Hayaru SHOUNO
PPTX
深層学習とTensorFlow入門
by
tak9029
PDF
03_深層学習
by
CHIHIROGO
PPTX
深層学習①
by
ssuser60e2a31
DOCX
レポート深層学習Day4
by
ssuser9d95b3
PDF
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化
by
RCCSRENKEI
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
強化学習とは (MIJS 分科会資料 2016/10/11)
by
Akihiro HATANAKA
PPTX
Positive-Unlabeled Learning with Non-Negative Risk Estimator
by
Kiryo Ryuichi
PPTX
深層学習の基礎と導入
by
Kazuki Motohashi
Deep learning chapter4 ,5
by
ShoKumada
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
Deep learning実装の基礎と実践
by
Seiya Tokui
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
20160329.dnn講演
by
Hayaru SHOUNO
数学で解き明かす深層学習の原理
by
Taiji Suzuki
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
ディープニューラルネット入門
by
TanUkkii
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
Deep Learningの技術と未来
by
Seiya Tokui
20150803.山口大学集中講義
by
Hayaru SHOUNO
深層学習とTensorFlow入門
by
tak9029
03_深層学習
by
CHIHIROGO
深層学習①
by
ssuser60e2a31
レポート深層学習Day4
by
ssuser9d95b3
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化
by
RCCSRENKEI
深層学習の数理
by
Taiji Suzuki
強化学習とは (MIJS 分科会資料 2016/10/11)
by
Akihiro HATANAKA
Positive-Unlabeled Learning with Non-Negative Risk Estimator
by
Kiryo Ryuichi
深層学習の基礎と導入
by
Kazuki Motohashi
More from Masayoshi Kondo
PDF
Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介
by
Masayoshi Kondo
PDF
GeneratingWikipedia_ICLR18_論文紹介
by
Masayoshi Kondo
PDF
Deep Learning
by
Masayoshi Kondo
PDF
Semantic_Matching_AAAI16_論文紹介
by
Masayoshi Kondo
PDF
最先端NLP勉強会2017_ACL17
by
Masayoshi Kondo
PDF
Get To The Point: Summarization with Pointer-Generator Networks_acl17_論文紹介
by
Masayoshi Kondo
Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介
by
Masayoshi Kondo
GeneratingWikipedia_ICLR18_論文紹介
by
Masayoshi Kondo
Deep Learning
by
Masayoshi Kondo
Semantic_Matching_AAAI16_論文紹介
by
Masayoshi Kondo
最先端NLP勉強会2017_ACL17
by
Masayoshi Kondo
Get To The Point: Summarization with Pointer-Generator Networks_acl17_論文紹介
by
Masayoshi Kondo
深層学習(岡本孝之 著) - Deep Learning chap.3_1
1.
深層学習 著:岡本 孝之 NAIST Computational Linguistic
Lab D1 Masayoshi Kondo 3章 -‐‑‒前半-‐‑‒
2.
00: はじめに 【⽬目的と狙い】 • Deep
Learningに興味があるけど詳しくは分からない理理系修⼠士学⽣生向け • 実⽤用的なことよりも基礎的知識識を重視 • 今後論論⽂文を読んで⾏行行く上での基礎体⼒力力を滋養し、各学⽣生の理理解速度度の向上が狙い 【ガイドライン】 • 「深層学習(講談社 : 岡本 貴之 著)」の本をまとめる形で発表 • 全8章の165ページから構成 • 本の内容に準拠(本に記載されていない内容・表現を知っている場合でも原則的 には記載を控える。あくまでも本の内容に忠実。) • ただし、適宜、参考⽂文献や関連論論⽂文等はあれば記載していくつもり • 理理系(情報⼯工学系)の⼤大学学部4年年⽣生が理理解できるくらいをイメージしてまとめる 今回 : 第3章
3.
XX: 緑のスライドとは? 書籍(本書)には記載されていないが、必要箇所の説明に際し 補助・追記として個⼈人的に記載が必要と思われた場合には、 緑⾊色のページに適宜載せることとする. •
本には載っていないけど、あえて追加説明したい場合は、 緑スライドに書くことにする. • 緑スライドに書かれる内容は本には記載されていない.
4.
00: はじめに 全8章 • 【第1章】はじめに •
【第2章】順伝搬型ネットワーク • 【第3章】確率率率的勾配降降下法 • 【第4章】誤差逆伝搬法 • 【第5章】⾃自⼰己符号化器 • 【第6章】畳込みニューラルネット(CNN) • 【第7章】再帰型ニューラルネット(RNN) • 【第8章】ボルツマンマシン
5.
00: はじめに 全8章 • 【第1章】はじめに •
【第2章】順伝搬型ネットワーク • 【第3章】確率率率的勾配降降下法 • 【第4章】誤差逆伝搬法 • 【第5章】⾃自⼰己符号化器 • 【第6章】畳込みニューラルネット(CNN) • 【第7章】再帰型ニューラルネット(RNN) • 【第8章】ボルツマンマシン
6.
00: はじめに –
これまでのまとめ (1・2章) -‐‑‒ 深層学習(Deep Learning) / ニューラルネット を使って分析するとは • ネットワークの構造 を決める • 活性化関数 を決める • 学習⽅方法(誤差関数と最適化法) を決める の3つを⾏行行うことである
7.
00: はじめに(今回まとめ) 深層学習・ニューラルネットワークを使⽤用することは、 • 学習時の過適合(overfitting) •
学習にかかる膨⼤大な計算時間 との戦い. 過適合を緩和する⽅方法と計算時間を縮⼩小する⼿手法を組み合わせて 現実的に解決可能な問題へ落落とし込む
8.
第3章 確率率率的勾配降降下法 3.1
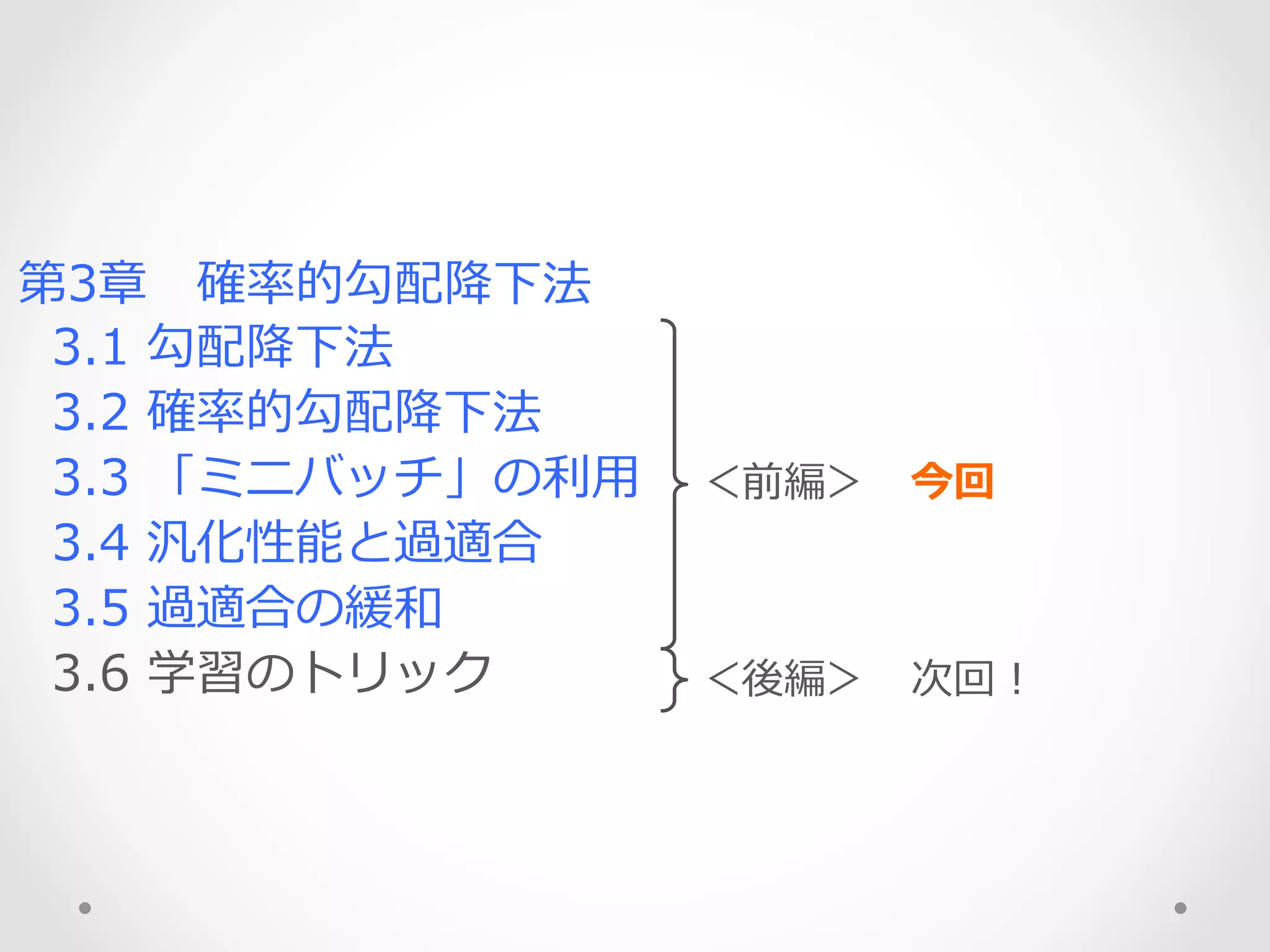
勾配降降下法 3.2 確率率率的勾配降降下法 3.3 「ミニバッチ」の利利⽤用 3.4 汎化性能と過適合 3.5 過適合の緩和 3.6 学習のトリック <前編> 今回 <後編> 次回!
9.
第3章 確率率率的勾配降降下法 3.1
勾配降降下法 3.2 確率率率的勾配降降下法 3.3 「ミニバッチ」の利利⽤用 3.4 汎化性能と過適合 3.5 過適合の緩和 3.6 学習のトリック
10.
代わりに、誤差関数の局所的な極⼩小点を求めることを考える 順伝搬型ネットワークにおける学習とは? 与えられた訓練データを元に計算される誤差関数をネットワークの パラメータ(重みとバイアス)について最⼩小化すること 01: 3.1 勾配降降下法
<学習のゴール> 選択した誤差関数に対し最⼩小値を与える重みとバイアスを求めること ⼀一般的に、誤差関数は凸関数ではないため ⼤大域的な最⼩小解を直接得られない 何らかの初期値を出発点にパラメータ(重みとバイアス)を繰り返し 更更新する反復復計算によって求める 最も簡単な⽅方法: → 勾配降降下法(Gradient Descent Method) <⽅方針・戦略略>
11.
02: 3.1 勾配降降下法
【勾配降降下法(Gradient Descent Method)】 勾配降降下法の勾配(gradient)は、 ∇E ≡ ∂E ∂w = ∂E ∂w1 !! ∂E ∂wM " # $ % & ' t というベクトルで表現される. 勾配降降下法は現在のwを負の勾配⽅方向( )に少し動かし、これを何度度も繰り返す ことでwを更更新. すなわち、 −∇E w(t+1) = w(t) −ε∇E としてwを更更新する. また、εはwの更更新量量の⼤大きさを決める学習係数. E w M ! " # $ # : 誤差関数 : 重みパラメータ : wの成分数 ⼀一覧:⾮非線形関数の最適化⼿手法 • 勾配降降下法 • ニュートン法 (⽬目的関数の⼆二次微分を利利⽤用) • 準ニュートン法
12.
第3章 確率率率的勾配降降下法 3.1
勾配降降下法 3.2 確率率率的勾配降降下法 3.3 「ミニバッチ」の利利⽤用 3.4 汎化性能と過適合 3.5 過適合の緩和 3.6 学習のトリック
13.
<確率率率的勾配降降下法の⻑⾧長所> 03: 3.2 確率率率的勾配降降下法
【確率率率的勾配降降下法(Stochastic Gradient Descent Method)】 誤差関数E(w)は、各サンプル1つだけについて計算される誤差En(w)の和として E(w) = En (w) n=1 N ∑ また、次のw(n+1)の更更新の時は、別のサンプルnʼ’を取り出して再度度上記の計算 を⾏行行い、繰り返し更更新を⾏行行うことで⽬目的のパラメータを最適化. 確率率率的勾配降降下法とは、サンプルの⼀一部(最も極端な場合はサンプル1つのみ) を使ってパラメータ更更新を⾏行行う⽅方法. この場合、wの更更新は1つのサンプルnにつ いて計算される誤差関数En(w)の勾配 を計算し、∇En w(t+1) = w(t) −ε∇En としてwを更更新. として表現され、E(w)を⽤用いて勾配計算し学習することをバッチ学習という. • 訓練データに冗⻑⾧長性がある場合、計算効率率率が向上し学習が早い • 反復復計算が “望まない局所的な極⼩小解”にトラップされてしまうリスクを低減できる • パラメータの更更新が⼩小刻みに⾏行行われるので学習の途中経過より細かく監視できる • 訓練データの収集と最適化の計算を同時並⾏行行で⾏行行えること(オンライン学習への対応)
14.
第3章 確率率率的勾配降降下法 3.1
勾配降降下法 3.2 確率率率的勾配降降下法 3.3 「ミニバッチ」の利利⽤用 3.4 汎化性能と過適合 3.5 過適合の緩和 3.6 学習のトリック
15.
誤差関数を各サンプルで計算 → 最後に合算 サンプル⼩小集合D1 サンプル全体 サンプル⼩小集合D2 サンプル⼩小集合Dn ・ ・ ・ サンプル⼩小集合DN ・ ・ ・ E2(w) E1(w) EN(w) ・ ・ ・ ・ ・ ・ ランダムに選択 En (t) (w) = 1 Dn Ei
(w) i∈Dn ∑ (t : t回⽬目の更更新を⽰示すパラメータ) 分割 • 通常、ミニバッチは学習開始前に事前に作成し、固定 • ミニバッチのサイズを決める系統的な⽅方法は無いが、概ね10~∼100サンプル前後 (確率率率的勾配降降下法のメリットと並列列計算資源の有効利利⽤用のバランスの観点から) サンプル⼩小集合Dnに含まれる各サンプル について並列列計算 En(w) 重みの更更新をサンプル1つ単位で⾏行行うのではなく、少数のサンプルの 集合をひとまとめにした単位(ミニバッチ)で重みの更更新を⾏行行う 規模の⼤大きなニューラルネットの学習は計算コストが⼤大きい 04: 3.3 「ミニバッチ」の利利⽤用 数値計算を効率率率化するために並列列計算の利利⽤用が必要不不可⽋欠
16.
第3章 確率率率的勾配降降下法 3.1
勾配降降下法 3.2 確率率率的勾配降降下法 3.3 「ミニバッチ」の利利⽤用 3.4 汎化性能と過適合 3.5 過適合の緩和 3.6 学習のトリック
17.
【訓練時の理理想】テスト誤差が汎化誤差をよく近似できている 場合、テスト誤差が最⼩小となるような状態 パラメータの更更新に伴ってテスト誤差が増加 = 学習の阻害 -‐‑‒
汎化誤差は統計的な期待値であり訓練誤差のように計算できない -‐‑‒ このため、訓練データとは別のサンプル集合を⽤用意し、訓練誤差と同じ⽅方法で 計算される誤差を汎化誤差の⽬目安とする -‐‑‒ この⽬目的で⽤用意するデータをテストデータと呼び、テストデータに関する誤差 をテスト誤差(test error)と呼ぶ 【過適合(overfitting) or 過剰適合・過学習(overlearning)】: 訓練誤差 と 汎化誤差 が乖離離した状態のこと 05: 3.4 汎化性能と過適合 解決策 >>【早期終了了(early stopping)】 : パラメータの更更新に伴いテスト誤差が増加する場合、その時点で学習を終了了すること ・訓練誤差(training error) : 訓練データ に対する誤差 ・汎化誤差(generalization error) : まだ⾒見見ぬ サンプルx に対する誤差
18.
【正規化(regularization)】 : 学習時の重みの⾃自由度度を制約すること 06:
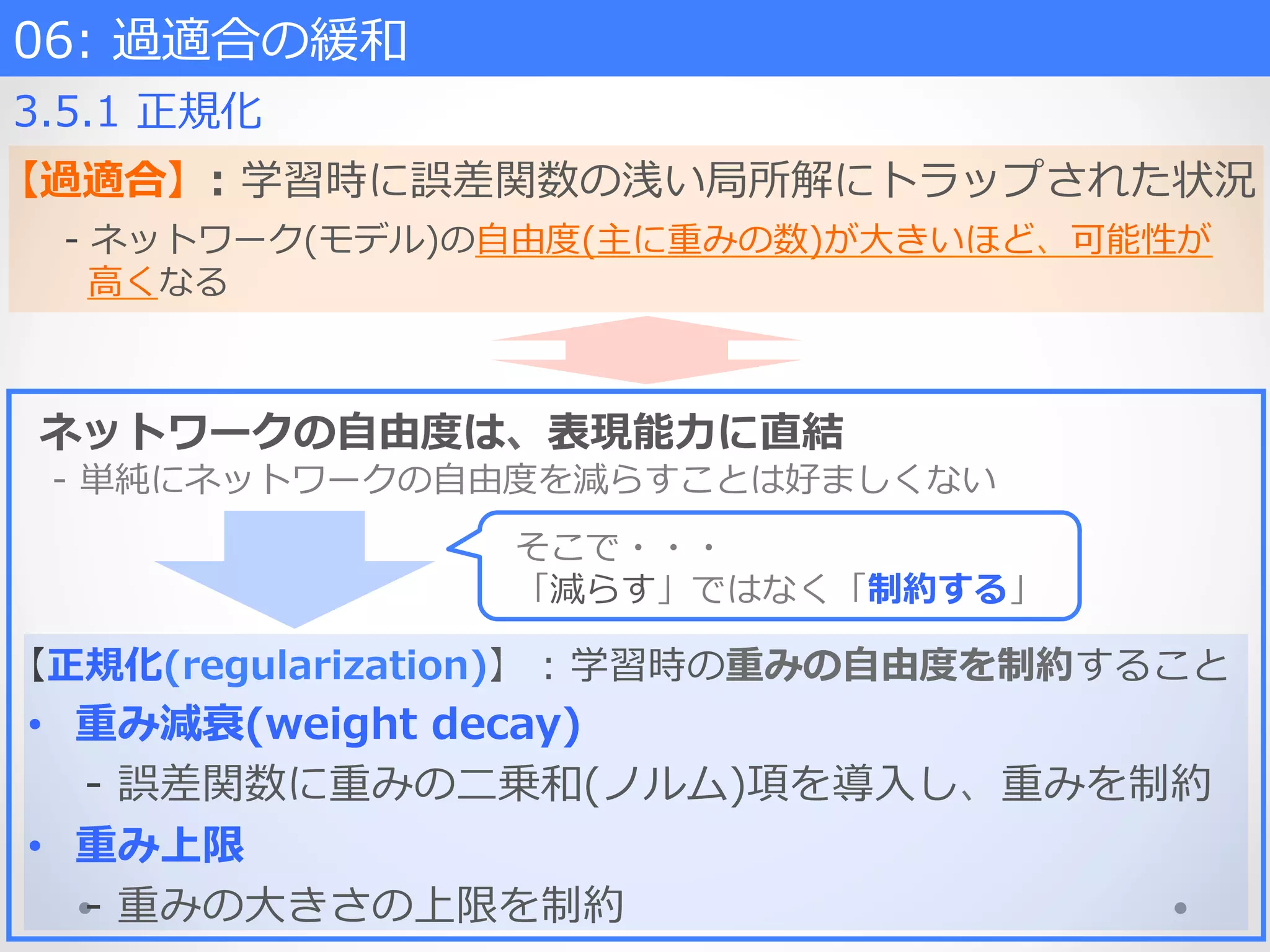
過適合の緩和 3.5.1 正規化 【過適合】: 学習時に誤差関数の浅い局所解にトラップされた状況 -‐‑‒ ネットワーク(モデル)の⾃自由度度(主に重みの数)が⼤大きいほど、可能性が ⾼高くなる ネットワークの⾃自由度度は、表現能⼒力力に直結 -‐‑‒ 単純にネットワークの⾃自由度度を減らすことは好ましくない そこで・・・ 「減らす」ではなく「制約する」 • 重み減衰(weight decay) -‐‑‒ 誤差関数に重みの⼆二乗和(ノルム)項を導⼊入し、重みを制約 • 重み上限 -‐‑‒ 重みの⼤大きさの上限を制約
19.
07: 過適合の緩和
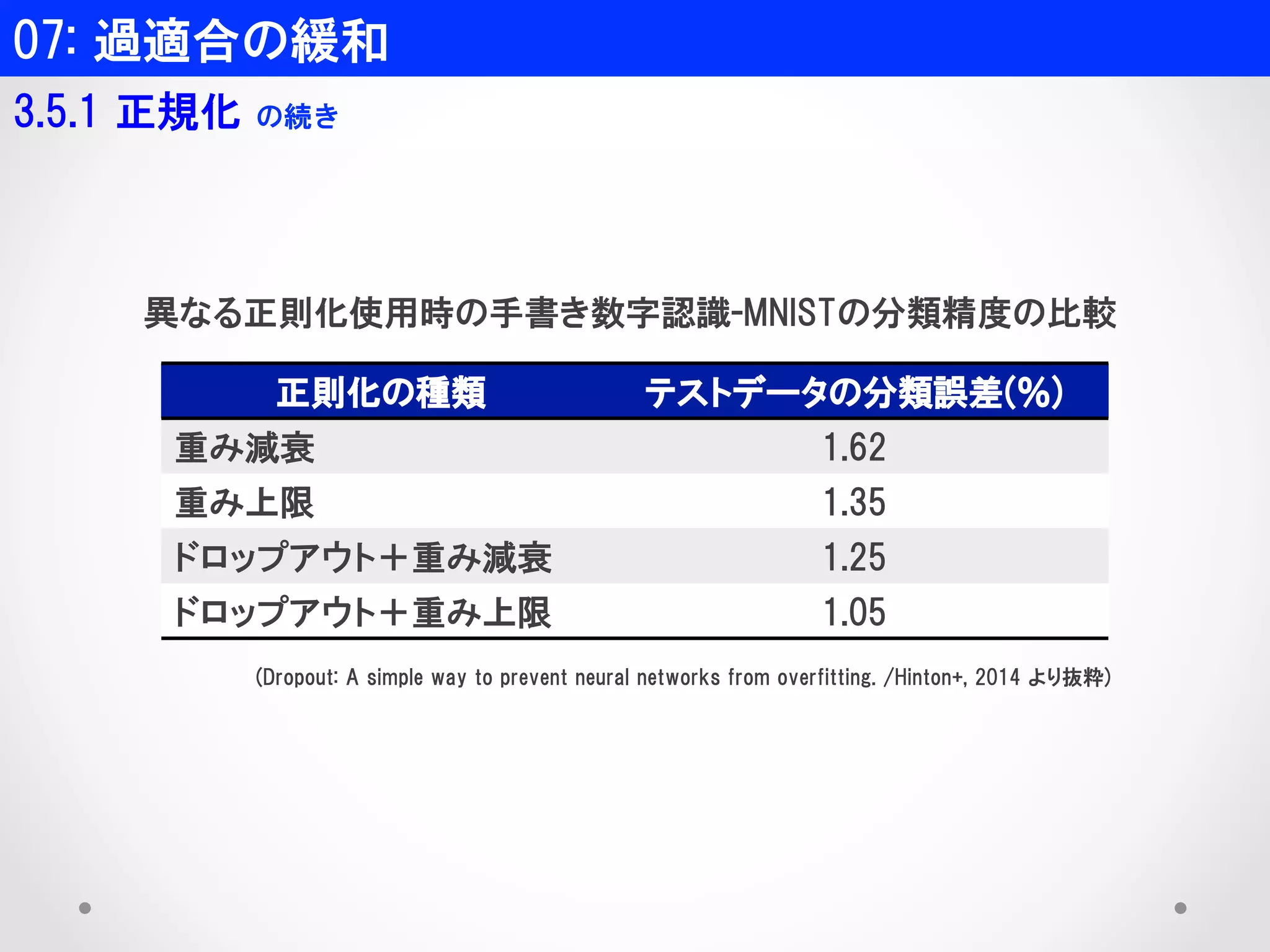
3.5.1 正規化 の続き 正則化の種類 テストデータの分類誤差(%) 重み減衰 1.62 重み上限 1.35 ドロップアウト+重み減衰 1.25 ドロップアウト+重み上限 1.05 異なる正則化使用時の手書き数字認識-MNISTの分類精度の比較 (Dropout: A simple way to prevent neural networks from overfitting. /Hinton+, 2014 より抜粋)
20.
08: 過適合の緩和
3.5.2 重みの制約 <重み上限>:重みの⼤大きさの上限を制約 -‐‑‒ 各ユニットの⼊入⼒力力側結合の重みの⼆二乗和の上限を制約 l層のユニットjが、(l−1)層のユニットi=1,2,…,I からの出⼒力力を受け取るとすると その間の結合重みwjiが wji 2 < c i ∑ を満たすように重みを制約. 不不等式が満たされていない場合は、1以下の定数を 掛けて、満たされるように修正. (cは定数) • 重み減衰 を上回る効果 • ドロップアウト を併⽤用すると⾼高い効果が発揮 <重み減衰>:誤差関数に重みの⼆二乗和(ノルム)項を導⼊入し、重みを制約 En (t) (w) ≡ 1 Dn Ei (w)+ λ 2 w 2 i∈Dn N ∑ w(t+1) = w(t) −ε 1 Dn ∇Ei (w) i∈Dn ∑ + λw(t) % & ' ' ( ) * * 重み⾃自体の⼤大きさに⽐比例例した早さで 常に減衰するように修正 • λは正則化の強さを制御するパラメータで、⼀一般的には 10-‐‑‒5 ≦λ≦ 10-‐‑‒2 • 重み減衰はネットワークの重みwだけに適⽤用し、バイアスbには適⽤用しない
21.
3.5.3 ドロップアウト -‐‑‒ 多層ネットワークのユニットを確率率率的に選別して学習する⽅方法 -‐‑‒
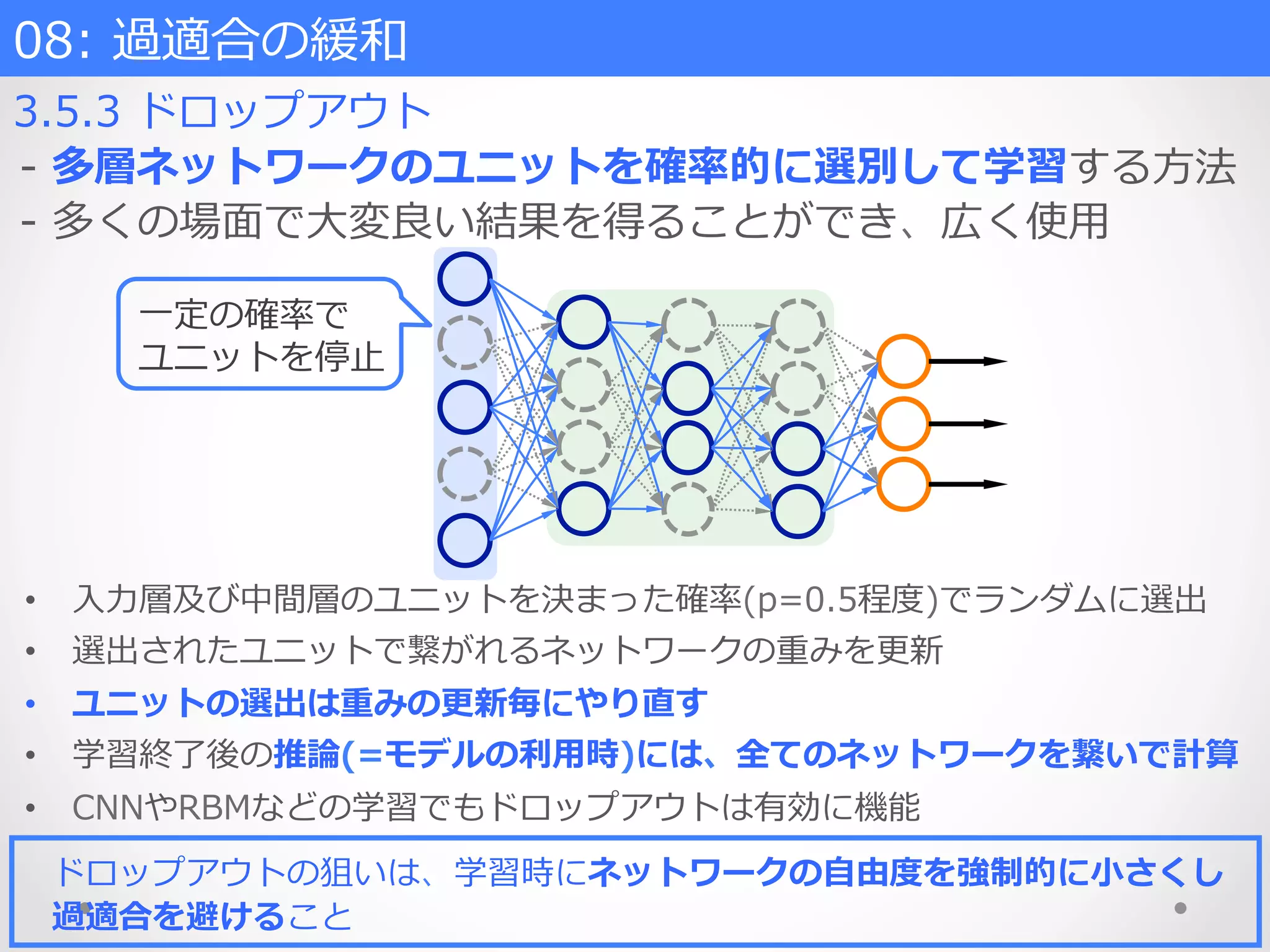
多くの場⾯面で⼤大変良良い結果を得ることができ、広く使⽤用 • ⼊入⼒力力層及び中間層のユニットを決まった確率率率(p=0.5程度度)でランダムに選出 • 選出されたユニットで繋がれるネットワークの重みを更更新 • ユニットの選出は重みの更更新毎にやり直す • 学習終了了後の推論論(=モデルの利利⽤用時)には、全てのネットワークを繋いで計算 • CNNやRBMなどの学習でもドロップアウトは有効に機能 ⼀一定の確率率率で ユニットを停⽌止 08: 過適合の緩和 ドロップアウトの狙いは、学習時にネットワークの⾃自由度度を強制的に⼩小さくし 過適合を避けること
22.
第3章 確率率率的勾配降降下法 3.1
勾配降降下法 3.2 確率率率的勾配降降下法 3.3 「ミニバッチ」の利利⽤用 3.4 汎化性能と過適合 3.5 過適合の緩和 3.6 学習のトリック →<後編>へ
23.
終わり
Download



































































![Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介](https://cdn.slidesharecdn.com/ss_thumbnails/graph2sequencelearningusinggatedgraphneuralnetworkacl18-190507010338-thumbnail.jpg?width=640&height=640&fit=bounds)




