Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
609 views
【DL輪読会】Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers
2022/8/5 Deep Learning JP http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 17
2
/ 17
3
/ 17
4
/ 17
5
/ 17
6
/ 17
7
/ 17
8
/ 17
9
/ 17
10
/ 17
11
/ 17
12
/ 17
13
/ 17
14
/ 17
15
/ 17
16
/ 17
17
/ 17
More Related Content
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PPTX
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
PDF
[DL輪読会]Temporal Abstraction in NeurIPS2019
by
Deep Learning JP
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
分散学習のあれこれ~データパラレルからモデルパラレルまで~
by
Hideki Tsunashima
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
[DL輪読会]Temporal Abstraction in NeurIPS2019
by
Deep Learning JP
機械学習モデルの判断根拠の説明
by
Satoshi Hara
分散学習のあれこれ~データパラレルからモデルパラレルまで~
by
Hideki Tsunashima
What's hot
PPTX
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
by
Deep Learning JP
PDF
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
by
Preferred Networks
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
PDF
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PPTX
backbone としての timm 入門
by
Takuji Tahara
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PDF
全力解説!Transformer
by
Arithmer Inc.
PDF
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
[DL輪読会]画像を使ったSim2Realの現況
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
[DL輪読会]World Models
by
Deep Learning JP
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PDF
Statistical Semantic入門 ~分布仮説からword2vecまで~
by
Yuya Unno
PDF
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
by
nlab_utokyo
PPTX
SHAP値の考え方を理解する(木構造編)
by
Kazuyuki Wakasugi
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
変分推論と Normalizing Flow
by
Akihiro Nitta
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
by
Deep Learning JP
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
by
Preferred Networks
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
backbone としての timm 入門
by
Takuji Tahara
近年のHierarchical Vision Transformer
by
Yusuke Uchida
全力解説!Transformer
by
Arithmer Inc.
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
[DL輪読会]画像を使ったSim2Realの現況
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
[DL輪読会]World Models
by
Deep Learning JP
GAN(と強化学習との関係)
by
Masahiro Suzuki
Statistical Semantic入門 ~分布仮説からword2vecまで~
by
Yuya Unno
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
by
nlab_utokyo
SHAP値の考え方を理解する(木構造編)
by
Kazuyuki Wakasugi
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
変分推論と Normalizing Flow
by
Akihiro Nitta
Similar to 【DL輪読会】Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PDF
【DL輪読会】Scaling laws for single-agent reinforcement learning
by
Deep Learning JP
PPTX
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
PDF
東北大学 先端技術の基礎と実践_深層学習による画像認識とデータの話_菊池悠太
by
Preferred Networks
PDF
効率的学習 / Efficient Training(メタサーベイ)
by
cvpaper. challenge
PDF
[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...
by
Deep Learning JP
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PDF
20150930
by
nlab_utokyo
PPTX
「解説資料」MetaFormer is Actually What You Need for Vision
by
Takumi Ohkuma
PDF
【DeepLearning研修】Transfomerの基礎と応用 --第4回 マルチモーダルへの展開
by
Sony - Neural Network Libraries
PPT
Deep Learningの技術と未来
by
Seiya Tokui
PDF
【DL輪読会】Learning Instance-Specific Adaptation for Cross-Domain Segmentation (E...
by
Deep Learning JP
PDF
Deeplearning lt.pdf
by
Deep Learning JP
PDF
[DL輪読会]Beyond Shared Hierarchies: Deep Multitask Learning through Soft Layer ...
by
Deep Learning JP
PDF
dl-with-python01_handout
by
Shin Asakawa
PDF
[DL輪読会]One Model To Learn Them All
by
Deep Learning JP
PDF
Deep Learning技術の今
by
Seiya Tokui
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
Transformer メタサーベイ
by
cvpaper. challenge
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
【DL輪読会】Scaling laws for single-agent reinforcement learning
by
Deep Learning JP
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
東北大学 先端技術の基礎と実践_深層学習による画像認識とデータの話_菊池悠太
by
Preferred Networks
効率的学習 / Efficient Training(メタサーベイ)
by
cvpaper. challenge
[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...
by
Deep Learning JP
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
20150930
by
nlab_utokyo
「解説資料」MetaFormer is Actually What You Need for Vision
by
Takumi Ohkuma
【DeepLearning研修】Transfomerの基礎と応用 --第4回 マルチモーダルへの展開
by
Sony - Neural Network Libraries
Deep Learningの技術と未来
by
Seiya Tokui
【DL輪読会】Learning Instance-Specific Adaptation for Cross-Domain Segmentation (E...
by
Deep Learning JP
Deeplearning lt.pdf
by
Deep Learning JP
[DL輪読会]Beyond Shared Hierarchies: Deep Multitask Learning through Soft Layer ...
by
Deep Learning JP
dl-with-python01_handout
by
Shin Asakawa
[DL輪読会]One Model To Learn Them All
by
Deep Learning JP
Deep Learning技術の今
by
Seiya Tokui
Deep Learningの基礎と応用
by
Seiya Tokui
More from Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
【DL輪読会】Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers
1.
1 DEEP LEARNING JP [DL
Papers] http://deeplearning.jp/ “Scale Efficiently: Insights from Pre-training and Fine- tuningTransformers” (ICLR2022) Okimura Itsuki, Matsuo Lab, M1
2.
アジェンダ 1. 書誌情報 2. 概要 3.
背景 4. 問題意識 5. 実験 6. 追加実験 2
3.
1 書誌情報 タイトル: Scale
Efficiently: Insights from Pre-training and Fine-tuning Transformers 出典: ICLR2022 https://openreview.net/pdf?id=f2OYVDyfIB 著者: Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler (Google Research & Deepmind) 選んだ理由:べき乗則の再検討みたいなもので気になった 3
4.
2 概要 • Transformer言語モデルでの上流で観察されるべき乗則が 下流のタスクにどのように影響するのかは不明であった. •
そこで多様な形状のT5ベースのモデルについて上流の言語モデリングと 下流でのタスクの性能を検証し, 上流タスクでの性能は下流タスクでの性能を保証しないことを示した. • また,下流タスクの性能はモデルの形状に影響を受け,層が深く幅が狭い DeepNarrowなモデルの学習効率が優れていることも示した. • DeepNarrowなモデルの優位性は他のNLPタスクで学習した場合や ViTでFew-shot学習を行った場合においても観察された. 4
5.
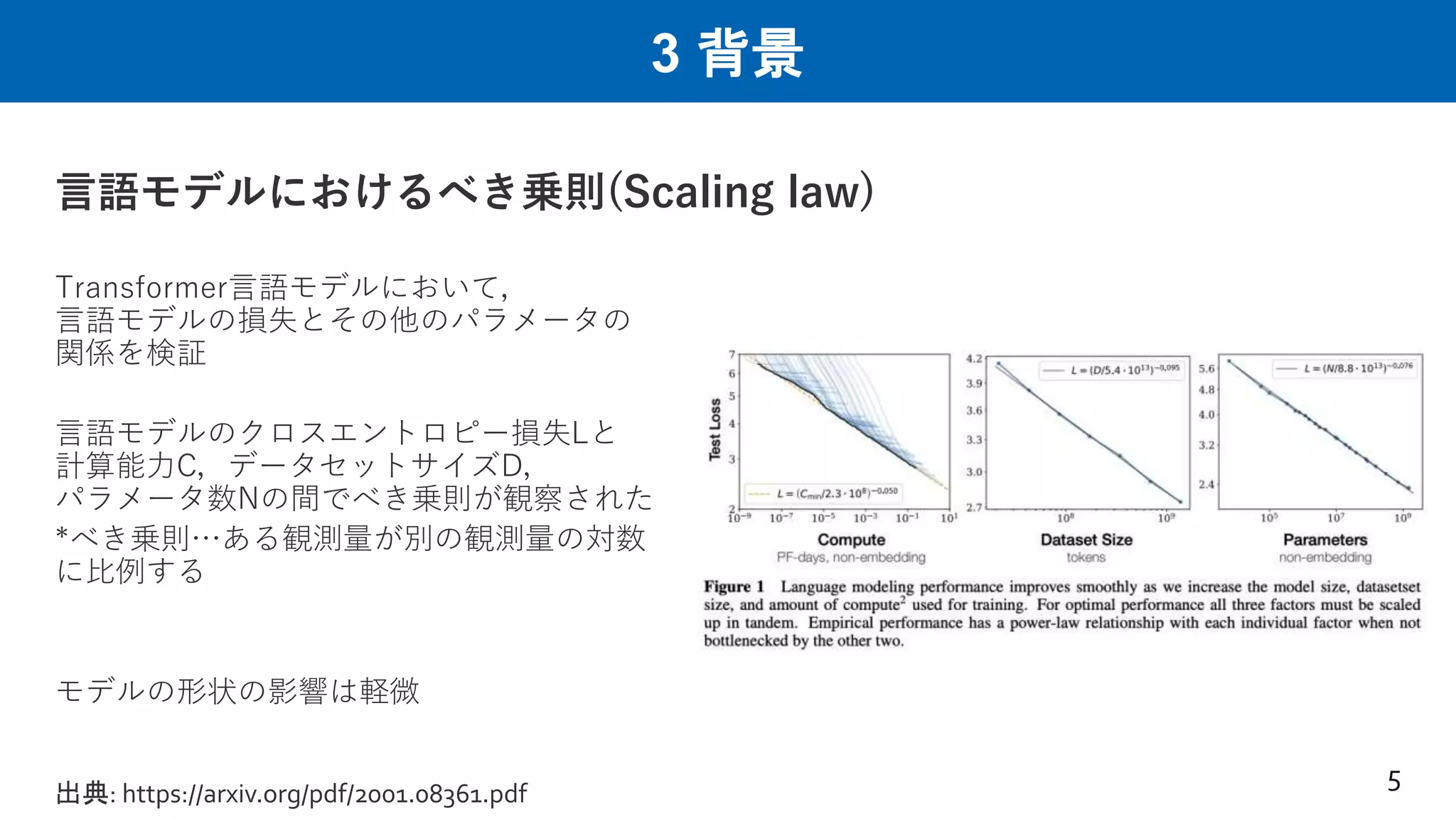
3 背景 言語モデルにおけるべき乗則(Scaling law) Transformer言語モデルにおいて, 言語モデルの損失とその他のパラメータの 関係を検証 言語モデルのクロスエントロピー損失Lと 計算能力C,データセットサイズD, パラメータ数Nの間でべき乗則が観察された *べき乗則…ある観測量が別の観測量の対数 に比例する モデルの形状の影響は軽微 5 出典:
https://arxiv.org/pdf/2001.08361.pdf
6.
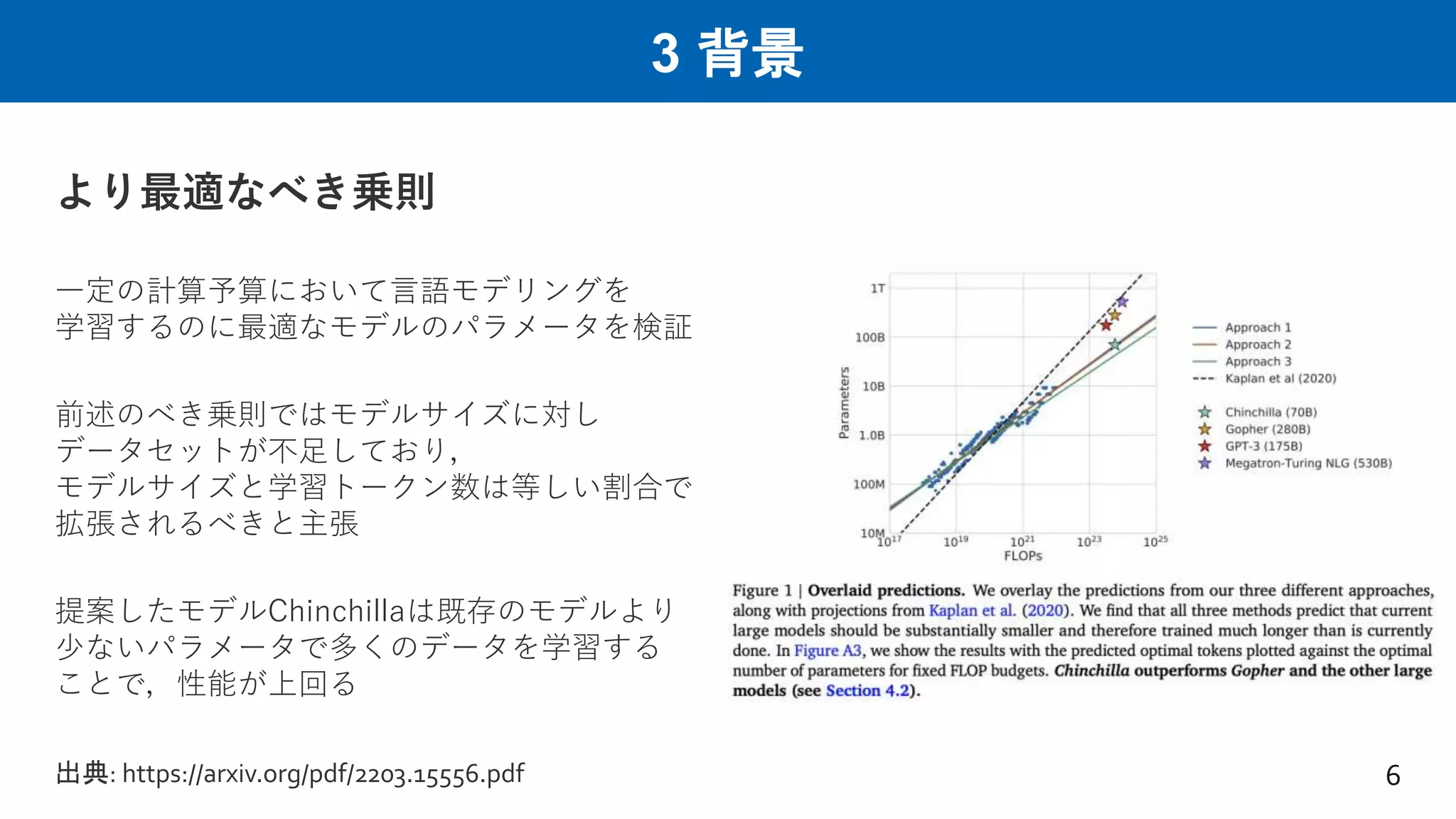
3 背景 より最適なべき乗則 一定の計算予算において言語モデリングを 学習するのに最適なモデルのパラメータを検証 前述のべき乗則ではモデルサイズに対し データセットが不足しており, モデルサイズと学習トークン数は等しい割合で 拡張されるべきと主張 提案したモデルChinchillaは既存のモデルより 少ないパラメータで多くのデータを学習する ことで,性能が上回る 6 出典: https://arxiv.org/pdf/2203.15556.pdf
7.
4 問題意識 7 べき乗則においていまだ不明な点は存在する 性能はモデルサイズによってスケールする →固定された比率でスケールさせるべきなのか? 上流の性能がべき乗則に従う →下流タスクでの性能は上流のべき乗則に従うのか?
8.
5 実験 8 多様な形状のモデルについて、上流と下流でのタスクの性能を検証 T5ベースアーキテクチャの様々なモデルサイズで 層の深さなどモデルの形状を変化させたモデルでの 性能を検証する. Ex. NL16-Base 上流 C4で学習した言語モデリングタスクでの損失 下流 GLUE
/ SuperGLUE / SQuADでの正解率
9.
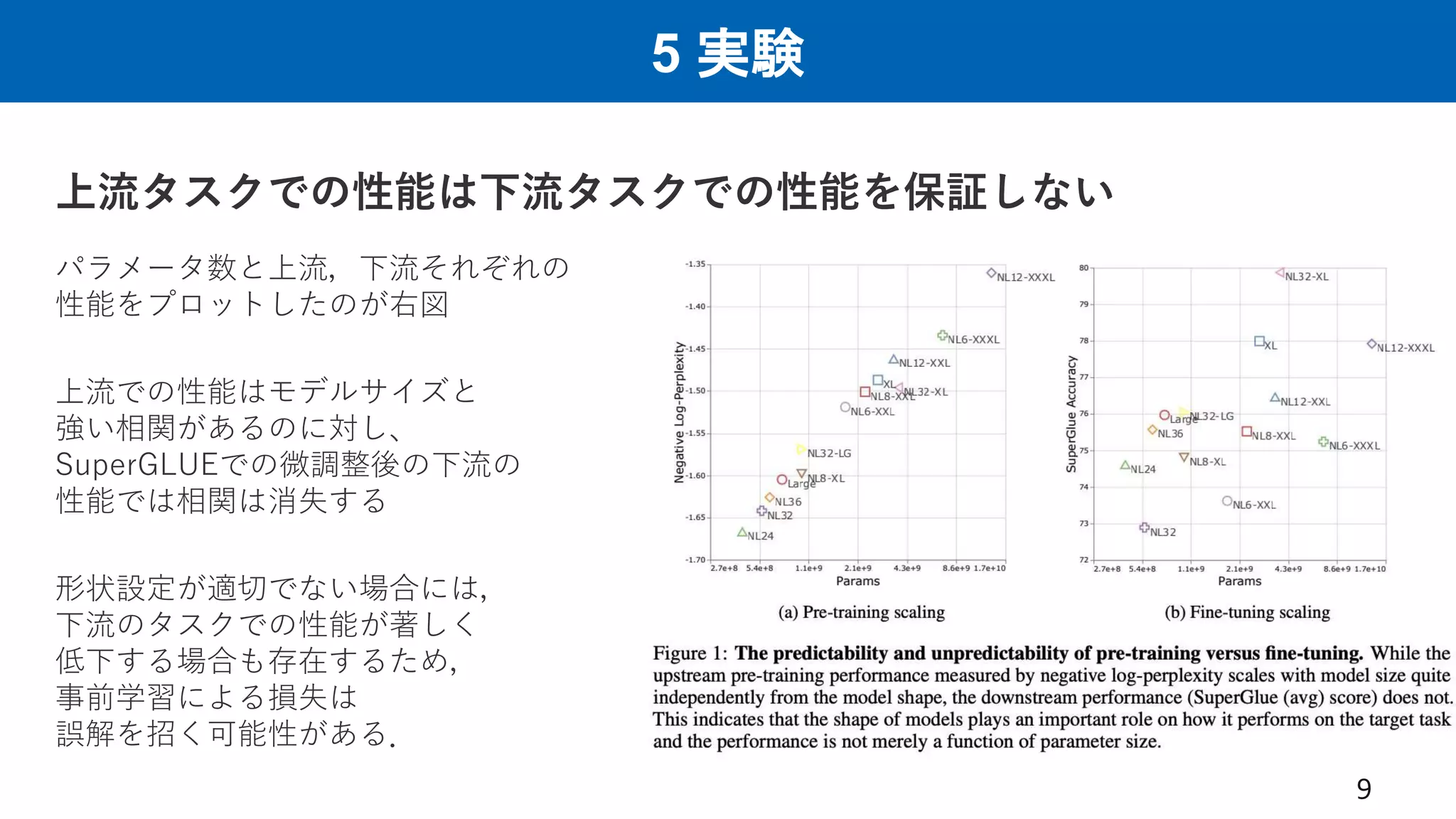
5 実験 上流タスクでの性能は下流タスクでの性能を保証しない 9 パラメータ数と上流,下流それぞれの 性能をプロットしたのが右図 上流での性能はモデルサイズと 強い相関があるのに対し、 SuperGLUEでの微調整後の下流の 性能では相関は消失する 形状設定が適切でない場合には, 下流のタスクでの性能が著しく 低下する場合も存在するため, 事前学習による損失は 誤解を招く可能性がある.
10.
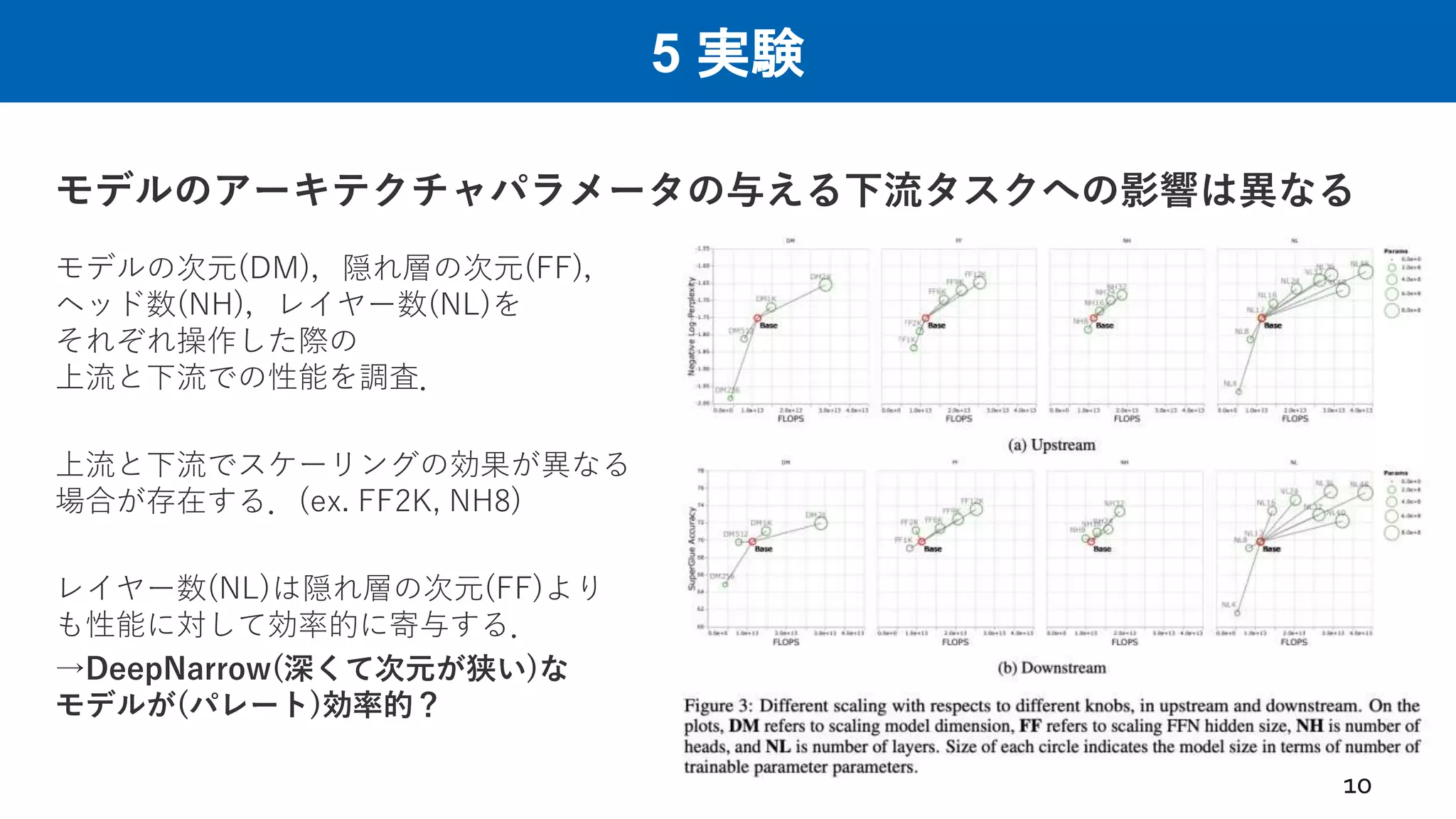
5 実験 モデルのアーキテクチャパラメータの与える下流タスクへの影響は異なる 10 モデルの次元(DM),隠れ層の次元(FF), ヘッド数(NH),レイヤー数(NL)を それぞれ操作した際の 上流と下流での性能を調査. 上流と下流でスケーリングの効果が異なる 場合が存在する.(ex. FF2K,
NH8) レイヤー数(NL)は隠れ層の次元(FF)より も性能に対して効率的に寄与する. →DeepNarrow(深くて次元が狭い)な モデルが(パレート)効率的?
11.
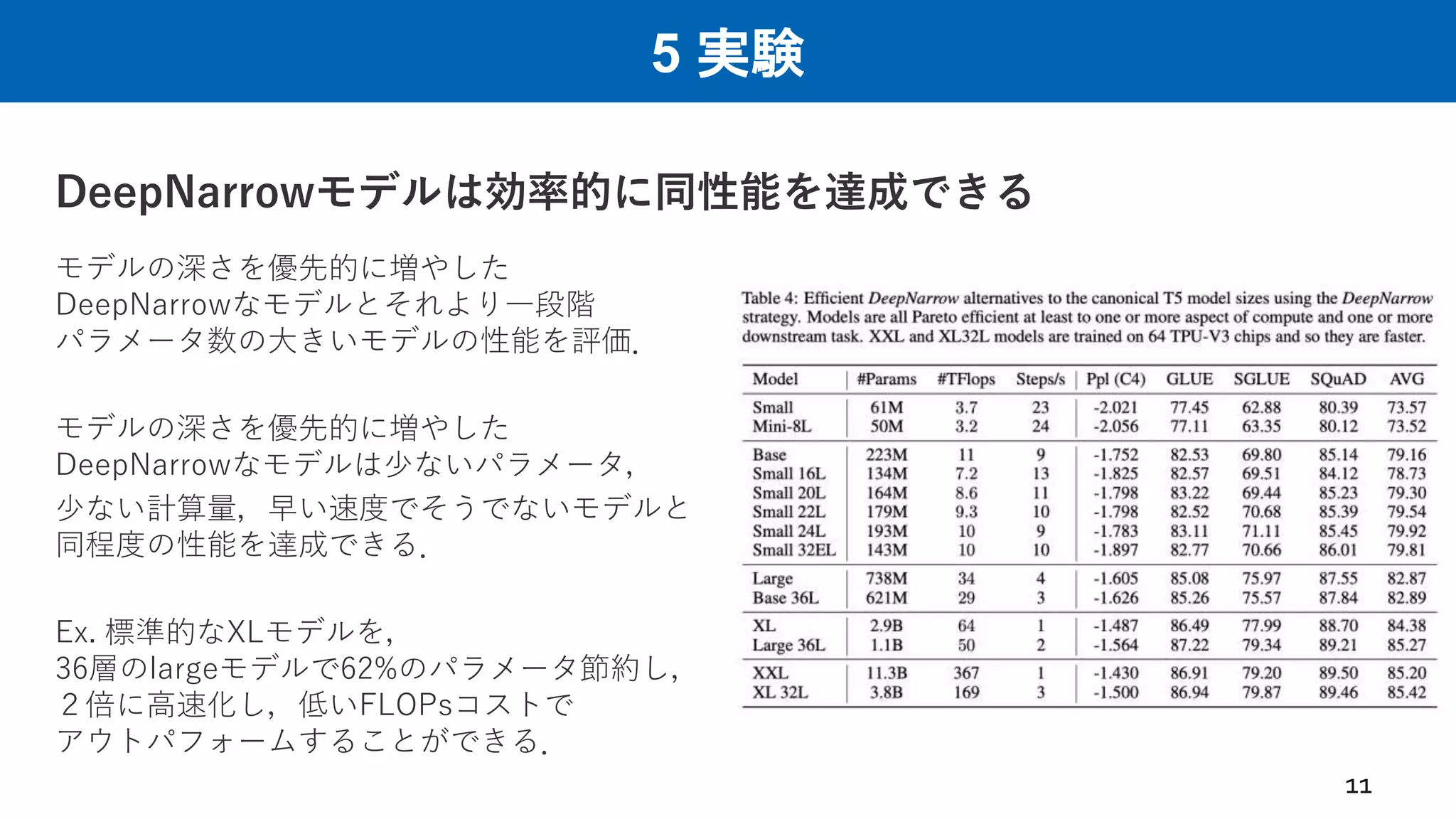
5 実験 DeepNarrowモデルは効率的に同性能を達成できる 11 モデルの深さを優先的に増やした DeepNarrowなモデルとそれより一段階 パラメータ数の大きいモデルの性能を評価. モデルの深さを優先的に増やした DeepNarrowなモデルは少ないパラメータ, 少ない計算量,早い速度でそうでないモデルと 同程度の性能を達成できる. Ex. 標準的なXLモデルを, 36層のlargeモデルで62%のパラメータ節約し, 2倍に高速化し,低いFLOPsコストで アウトパフォームすることができる.
12.
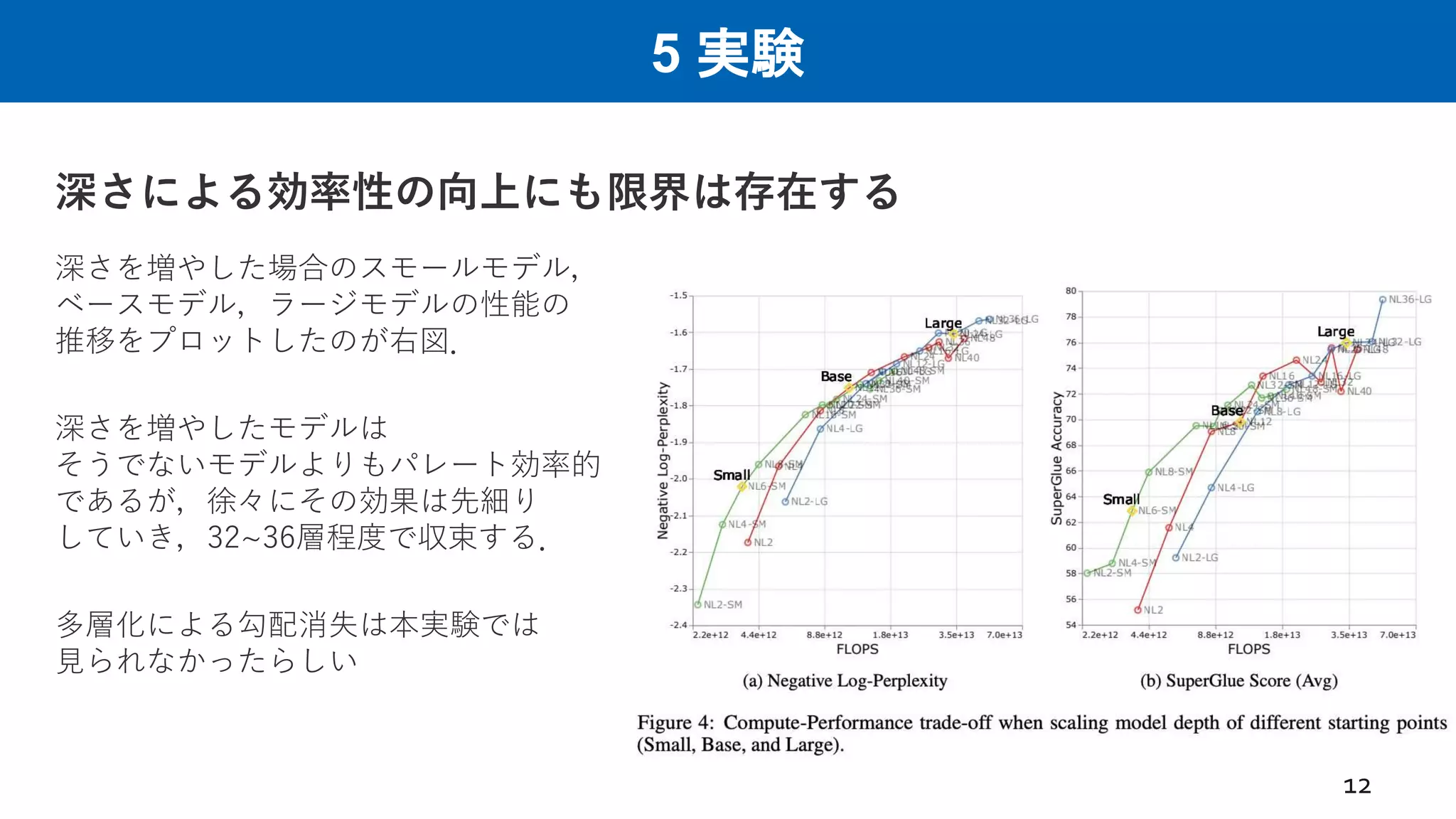
5 実験 深さによる効率性の向上にも限界は存在する 12 深さを増やした場合のスモールモデル, ベースモデル,ラージモデルの性能の 推移をプロットしたのが右図. 深さを増やしたモデルは そうでないモデルよりもパレート効率的 であるが,徐々にその効果は先細り していき,32~36層程度で収束する. 多層化による勾配消失は本実験では 見られなかったらしい
13.
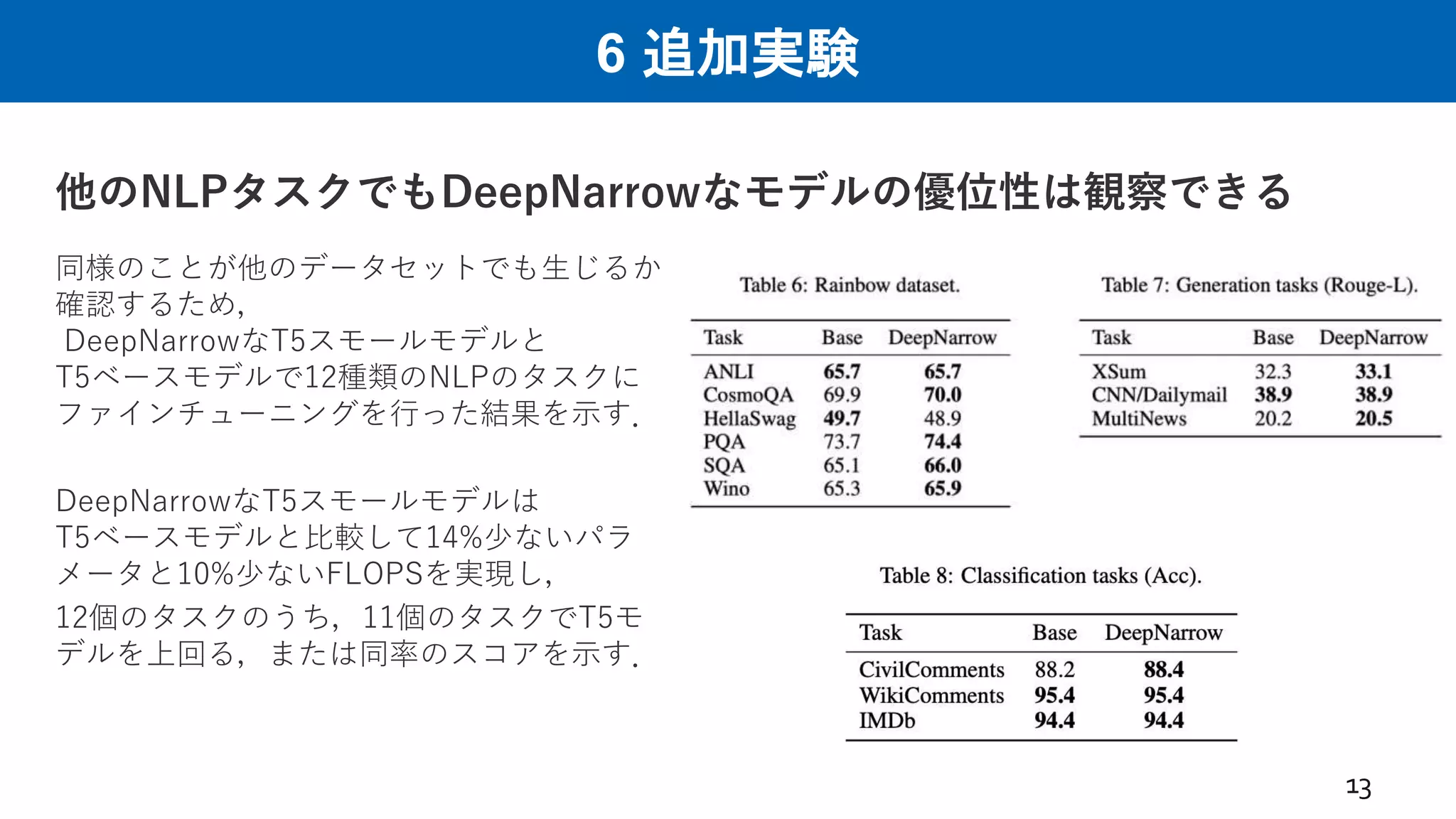
6 追加実験 他のNLPタスクでもDeepNarrowなモデルの優位性は観察できる 13 同様のことが他のデータセットでも生じるか 確認するため, DeepNarrowなT5スモールモデルと T5ベースモデルで12種類のNLPのタスクに ファインチューニングを行った結果を示す. DeepNarrowなT5スモールモデルは T5ベースモデルと比較して14%少ないパラ メータと10%少ないFLOPSを実現し, 12個のタスクのうち,11個のタスクでT5モ デルを上回る,または同率のスコアを示す.
14.
6 追加実験 ViTでもDeepNarrowなモデルの優位性は観察できる 14 同様のことが他のモダリティでも起こるかを 検証するため,ViTでの事前学習後の Few-shot性能を比較. DeepNarrowなViT-Sモデルは, ViT-Bモデルと比較してより 良いパレート効率を示す. 特に、L =
24の場合,15%少ないパラメータ、 11%少ないFLOPsでより良いFew-shot精度 を達成した.
15.
まとめ 15 • Transformer言語モデルでの上流で観察されるべき乗則が 下流のタスクにどのように影響するのかは不明であった. • そこで多様な形状のT5ベースのモデルについて上流の言語モデリングと 下流でのタスクの性能を検証し, 上流タスクでの性能は下流タスクでの性能を保証しないことを示した •
また,下流タスクの性能はモデルの形状に影響を受け,層が深く幅が狭い DeepNarrowなモデルの学習効率が優れていることも示した. • DeepNarrowなモデルの優位性は他のNLPタスクで学習した場合や ViTでFew-shot学習を行った場合においても観察された.
16.
感想 16 確かにpplがそのまま下流タスクに反映されるとか, モデル形状が下流に全く影響与えないとは考えにくい 評価の難しい対話モデルなどはpplを性能の指標とする場合もあったので, 良い言語モデルとはなんなのか考えさせられる Decoderモデルだけでなく, Encoder-Decoderモデルでも上流ではべき乗則が見られたのは 少し面白い 上流と下流を対比したグラフとして、縦軸に性質の異なるメトリクスを使っているのは少しズルい?
17.
DEEP LEARNING JP [DL
Papers] “Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets” (ICLR 2021 workshop) Okimura Itsuki, Matsuo Lab, B4 http://deeplearning.jp/
Download
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
“Scale Efficiently: Insights from Pre-training and Fine-
tuningTransformers” (ICLR2022)
Okimura Itsuki, Matsuo Lab, M1](https://image.slidesharecdn.com/20220805okimura-220824025553-43ff2ac2/75/DL-Scale-Efficiently-Insights-from-Pre-training-and-Fine-tuning-Transformers-1-2048.jpg)








![DEEP LEARNING JP
[DL Papers]
“Grokking: Generalization Beyond Overfitting on Small
Algorithmic Datasets” (ICLR 2021 workshop)
Okimura Itsuki, Matsuo Lab, B4
http://deeplearning.jp/](https://image.slidesharecdn.com/20220805okimura-220824025553-43ff2ac2/75/DL-Scale-Efficiently-Insights-from-Pre-training-and-Fine-tuning-Transformers-17-2048.jpg)





![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Beyond Shared Hierarchies: Deep Multitask Learning through Soft Layer ...](https://cdn.slidesharecdn.com/ss_thumbnails/180302nonaka-180309041654-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]One Model To Learn Them All](https://cdn.slidesharecdn.com/ss_thumbnails/dljp20170714ono-170714005853-thumbnail.jpg?width=640&height=640&fit=bounds)



























