Download as PDF, PPTX



![4
マルチモーダルモデルとは?
*1 “Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action”, in CVPR 2024 https://arxiv.org/pdf/2312.17172
マルチモーダル情報を必要とするタスクの例 ([J. Lu et al 2024]*1 より)
言語を用いた画像編集 (Vision + Language)
画像中の音源位置推定 (Vision + Audio)
画像に対する質問への回答 (Vision + Language)
画像と言語を用いたロボットへのタスク指示 (Vision + Language + Robot)
• 画像や言語など複数のモーダル情報を統合して、タスクを実行するモデル
• 実世界では、視覚 (画像) や聴覚 (音) など、様々な知覚情報が存在
• 実世界のタスクの多くは、複数のモーダル間の関係性を考慮する必要
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-4-2048.jpg)
![5
A Generalist Agent (Gato) [DeepMind 2022]*1
• 画像や言語などのマルチモーダル情報を使った様々なタスクを実行可能な
Transformer ベースのニューラルネットワークモデル
• 画像や言語に関するタスクに加えて、ロボットやゲームなど行動決定に関
するタスクなども行うことが可能
*1 “A Generalist Agent”, in Transactions on Machine Learning Research 2022. https://arxiv.org/pdf/2205.06175
Image Captioning
Robot Manipulation
Chitchat
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-5-2048.jpg)
![8
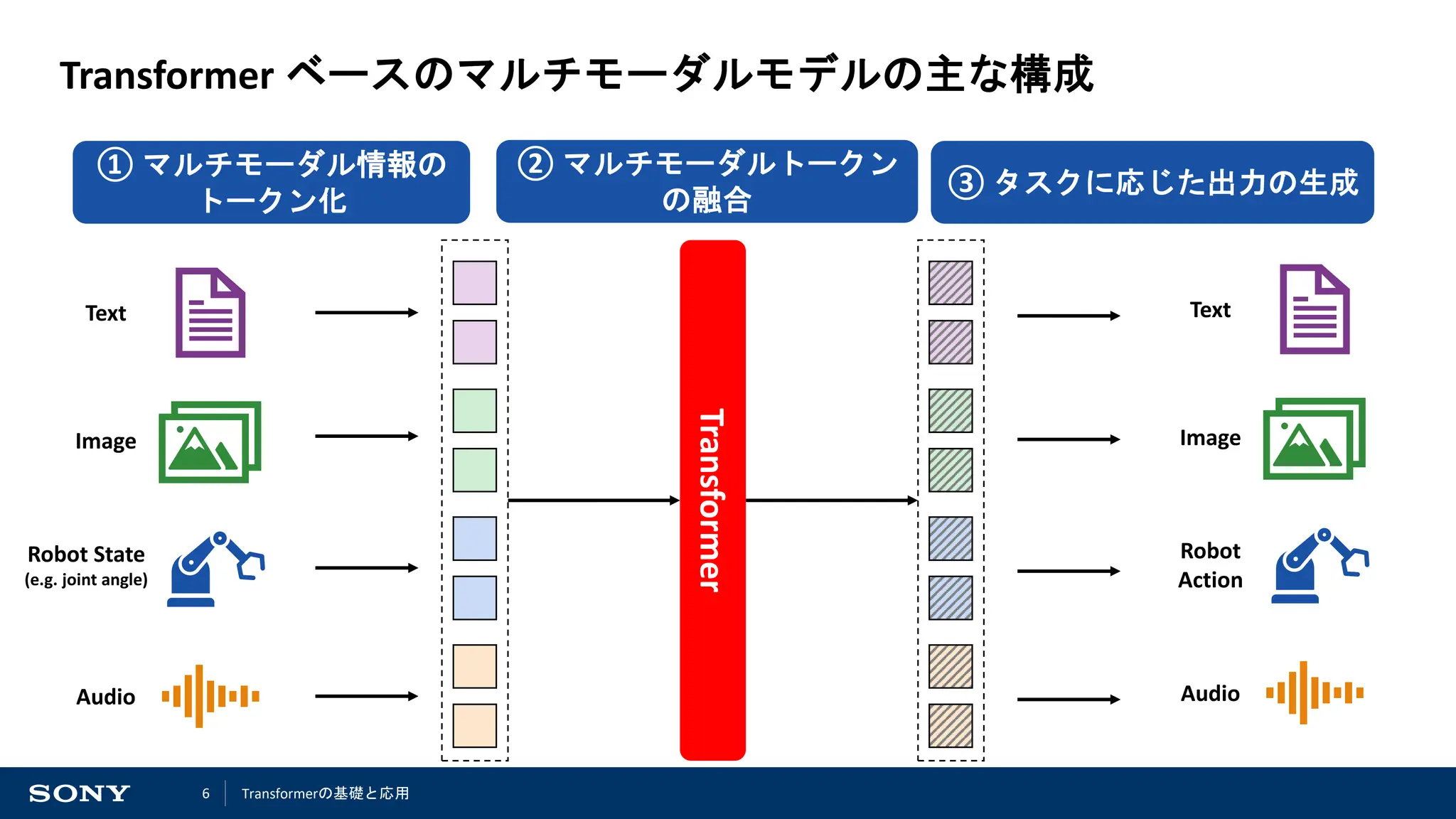
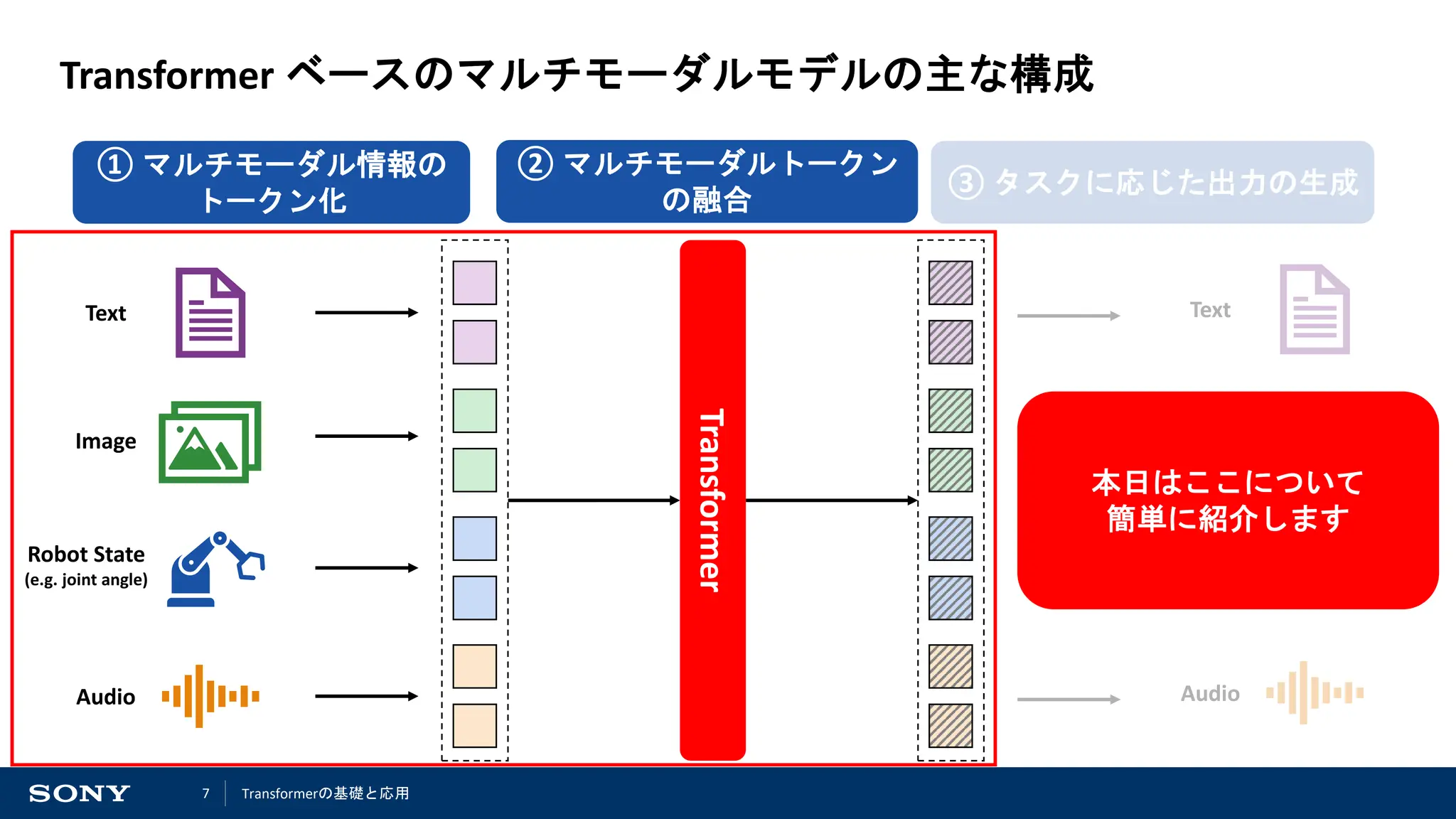
マルチモーダル情報のトークン化
主に二つの操作によって、トークン化が行われている
1. 各モーダルの入力データの分割
2. 分割されたデータを特徴量ベクトルへと変換
Gato [DeepMind 2022]*1 でのトークン化の例
*1 “A Generalist Agent”, in Transactions on Machine Learning Research 2022. https://arxiv.org/pdf/2205.06175
画像
1. パッチに分割
2. 各パッチを特徴ベクトル
に変換
3. パッチ内での Position
Encoding を加える
ゲームアクション (離散値)
1. 各整数に対応する特徴ベクトル
を参照
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-8-2048.jpg)
![9
マルチモーダルトークンの融合 (1/2)
• 各モーダルのトークンを集約し、より表現力の高い特徴量へと変換する
• Self-Attention をベースとして様々な方法が提案されている
Gato [DeepMind 2022]*1 でのトークンの融合の例
*1 “A Generalist Agent”, in Transactions on Machine Learning Research 2022. https://arxiv.org/pdf/2205.06175
• 画像のトークンと離散アクション
のトークンを連結
• シーケンス内のどの位置にあるトークン
なのかを表す Position Encodings を加える
• シーケンス全体に対して、
Self-Attention で処理を行う
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-9-2048.jpg)
![10
マルチモーダルトークンの融合 (2/2)
• 各モーダルのトークンを集約し、より表現力の高い特徴量へと変換する
• Self-Attention をベースとして様々な方法が提案されている
Flamingo [DeepMind 2022]*1
• 画像特徴と言語特徴の融合に Cross-Attention を使用
• その後、言語特徴に対して Self-Attention を行う
*1 “Flamingo: a Visual Language Model for Few-Shot Learning”, in NeurIPS 2022. https://arxiv.org/pdf/2204.14198
*2 “NExT-GPT: Any-to-Any Multimodal LLM,” in ICML, 2024. https://arxiv.org/pdf/2309.05519
NExT-GPT [S. Wu et al., 2024]*2
• 各モーダルの特徴を学習済みの LLM で扱えるような特徴
に変換するような Projector を学習
• モーダル特徴の融合には学習済みの LLM をそのまま使用
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-10-2048.jpg)
![11
基盤モデルへの発展
• 使用できるモーダル数も増加し、1つのモデルでより多くのタスクが解ける
ように ⇒ 基盤モデル の発展?
*1 “Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action”, in CVPR 2024 https://arxiv.org/pdf/2312.17172
*2 “MUTEX: Learning Unified Policies from Multimodal Task Specifications”, in CoRL 2023. https://arxiv.org/pdf/2309.14320
*3 “On the Opportunities and Risks of Foundation Models”, in arXiv 2021. https://arxiv.org/pdf/2108.07258
MUTEX [R. Shah et al., 2023]*2
Unified-IO [J. Lu et al 2024]*1
基盤モデル ([R. Bommasani et al., 2021]*3 より)
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-11-2048.jpg)


![14
ロボティクスへの応用
• 言語や画像での発展に伴い、ロボティクス分野にも Transformer が普及
• ロボットの行動計画には、様々なモーダルの観測データ (画像、LIDAR、触覚、…) を扱う必要
• タスクによって、時系列情報も考慮する必要
⇒ Transformer を使うことで、両方の要素に対処可能
Manipulation
言語によるタスク指示に従って物体を操作
RT-1 [Google 2023]*1
*1 “RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE”, in RSS 2023. https://arxiv.org/pdf/2205.06175
*2 “ViNT: A Foundation Model for Visual Navigation”, in CoRL 2023. https://arxiv.org/pdf/2306.14846
Navigation
画像や座標で指定された場所へ移動する
ViNT [D. Shar et al., 2023]*2
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-14-2048.jpg)
![15
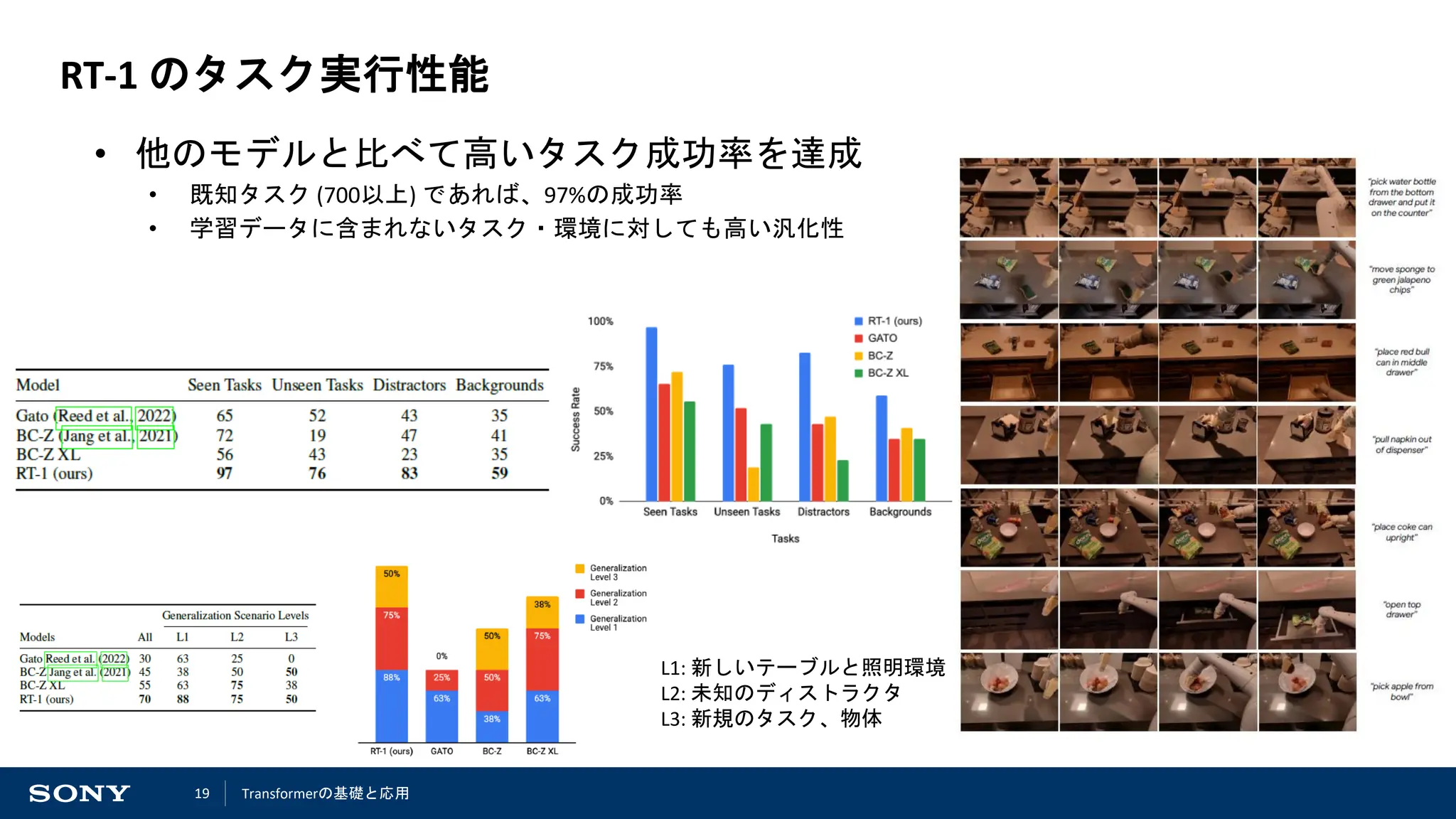
RT-1 (Robotics Transformer) [Google 2023]*1
• ロボット13台で17ヶ月かけて大量の収
集したデータを用いた学習によって、
様々なタスクに対応可能なモデルを獲
得
• データ数: 13万エピソード, 700以上のタスク
• 700以上のタスクに対して、タスク成功
率97%を実現
*1 “RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE”, in RSS 2023. https://arxiv.org/pdf/2205.06175
タスクの内訳
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-15-2048.jpg)
![16
RT-1のモデル構造 (1/3)
画像とタスク指示のトークン化
• 入力:過去の 6 step 分のRGB画像 + タスク指示
• タスク指示は、Universal Sentence Encoder [D. Cer et al., 2018]*1 によっ
て、512次元のベクトルにエンコードされる
• 各RGB画像の特徴抽出には、 ImageNet を用いて事前学習した
EfficientNet-B3 [M. Tan and Q. Le, 2019]*2 を使用
• その際、 FiLM [E. Perez et al., 2018]*3 を用いて、画像特徴とテキスト特徴を融合
• 最終的に、各画像当たり 9 x 9 x 512 の特徴マップが抽出される
*1 “Universal sentence encoder”, in arXiv 2018. https://arxiv.org/pdf/1803.11175
*2 “EfficientNet: Rethinking model scaling for convolutional neural networks”, in ICML 2019. https://arxiv.org/pdf/1905.11946
*3 “Film: Visual reasoning with a general conditioning layer”, in AAAI 2018. https://arxiv.org/pdf/1709.07871
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-16-2048.jpg)
![17
RT-1のモデル構造 (2/3)
TokenLearner [M. S. Ryoo et al., 2021]*1 による情報の圧縮
• ロボットで動作させるためには、なるべくモデル容量を小さくしておき
たい
• 計算量の削減、推論速度の高速化
• Attention ベースの機構を用いることで、重要な特徴のみを抽出
• 81個 ⇒ 8個のトークンへと圧縮
*1 “TokenLearner: Adaptive Space-Time Tokenization for Videos”, in NeurIPS 2021. https://openreview.net/pdf?id=z-l1kpDXs88
TokenLearner の処理の詳細
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-17-2048.jpg)

![20
RT-1 と SayCan [Google 2022]*1 の統合
• SayCan と組み合わせることで、Long-Horizon な
タスクも実行可能
※ SayCan: LLM による Long-Horizon なタスクの分割と、観測情報に基づ
く各サブタスクの価値の推定を行うことで、適切なサブタスクの選択
を行う手法
Instruction: "Bring me the rice chips from the drawer.”
Instruction: "Roses are red, violets are blue, bring me
the rice chips from the drawer, and a napkin too.”
Instruction: "Bring me all the graspable objects from the
counter.”
*1 “Do As I Can and Not As I Say: Grounding Language in Robotic Affordances”, in CoRL 2022 https://arxiv.org/pdf/2204.01691
SayCan [Google 2022]*1
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-20-2048.jpg)
![21
RT-2 [DeepMind 2023]*1
• 学習済みの Vision-Language Model (VLM) を直接行動推定に利用
⇒ Vision-Language-Action Model (VLA)
• アクションは各軸ごとに離散化する (= 整数値でアクションを表現) ことで、
VLM でも生成を行うことができるように
• 学習済みの VLM には、PaLI-X [X. Chen et al., 2024]*2 や PaLM-E [D. Driess et al., 2023]*3 を使用
VLM によって生成
された整数列
*1 “RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control”, in CoRL 2023. https://arxiv.org/pdf/2307.15818
*2 “PaLI-X: On Scaling up a Multilingual Vision and Language Model”, in CVPR 2024. https://arxiv.org/pdf/2305.18565
*3 “PaLM-E: An Embodied Multimodal Language Model”, in ICML 2023. https://arxiv.org/pdf/2303.03378
学習時には、Vision-
Language 用のデータも
使用 (もともと持ってい
る表現力が落ちないよ
うに)
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-21-2048.jpg)
![22
RT-2 [DeepMind 2023]*1
• 大量のデータで学習された VLM を利用
⇒ ロボットコントロール用のデータに含まれない知識も活用したマニピュ
レーションが可能に!
※ 国旗や人の顔写真に関するデータは
ロボットコントロール用のデータには含まれていない
*1: “RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control”, in CoRL 2023 https://arxiv.org/pdf/2307.15818
出典: https://robotics-transformer2.github.io/
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-22-2048.jpg)

![24
ALOHA [T. Z. Zhao et al., 2023]*1
目的: データ収集をより簡単に
• 安価 (約20kドル) で構築できる双腕ロボットシステム
• 人間による遠隔教示が簡単に行うことができる
• 教示したデータを用いて学習するモデルに Transformer
を利用
人間が教示をしている様子 学習した方策によるタスク実行
*1 “Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware”, in RSS 2023. https://arxiv.org/pdf/2304.13705
ACT (Action Chunking with Transformer)
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-24-2048.jpg)
![25
RT-X [Open X-Embodiment Collaboration 2024]*1
目的: ロボットタスク向けの事前学習用データセットの構築
• 様々な環境で収集された様々なタスクのデータを集約したデータセット
• このデータセットで事前学習 + 解きたいタスクの少量のデータでファインチューン
⇒ 少量のデータのみで学習するよりも性能が向上
*1 “Open X-Embodiment: Robotic Learning Datasets and RT-X Models”, in ICRA 2024. https://arxiv.org/pdf/2310.08864
• 34 robotic research labs (21 institutions)
• 22 robot embodiments
• 1M+ robot trajectories
• 300+ scenes
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-25-2048.jpg)


![29
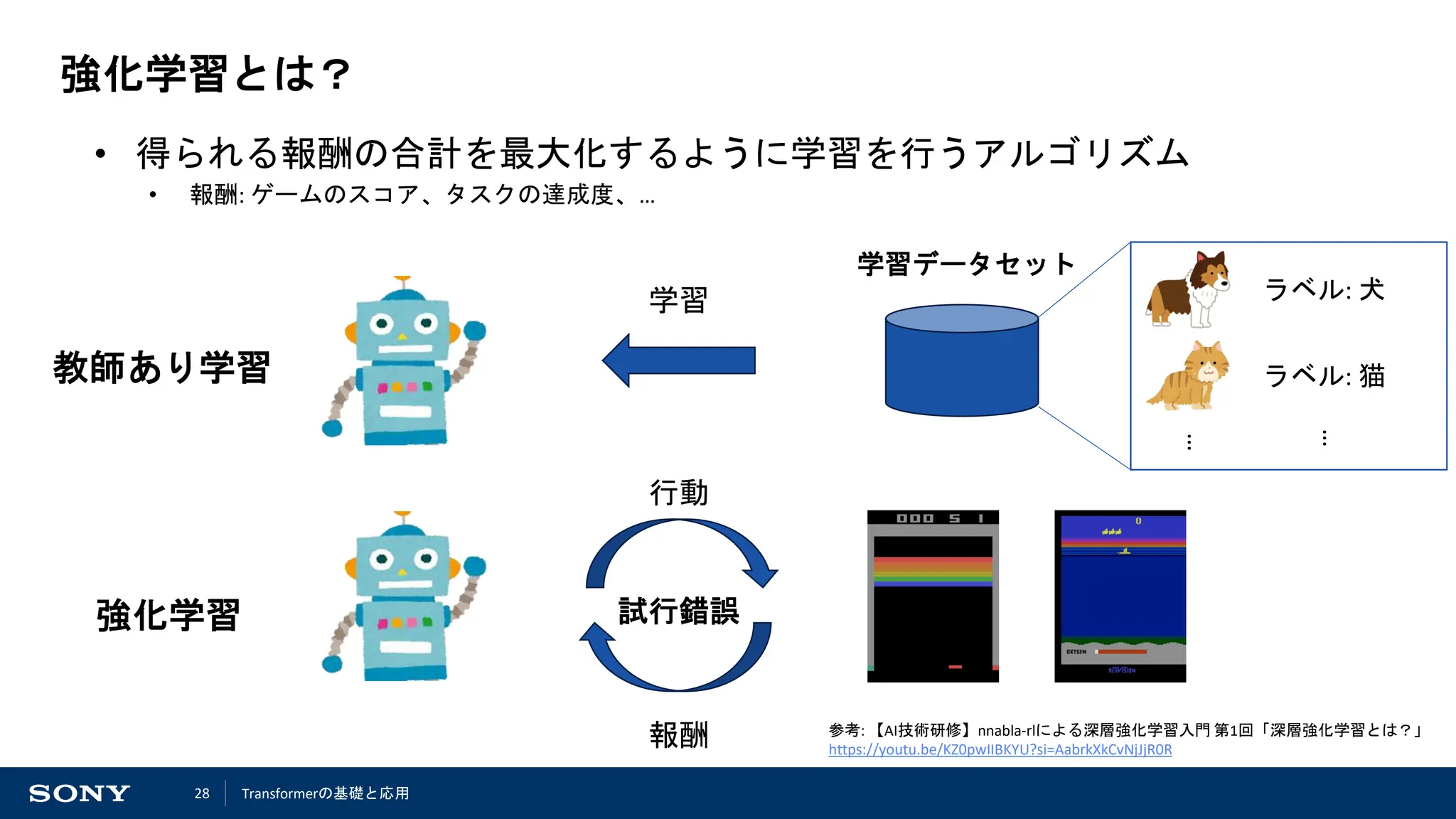
強化学習の応用例
(出典: https://www.bbc.com/news/technology-35785875) (出典: https://www.gran-turismo.com/jp/gran-turismo-sophy/technology/)
AlphaGo [DeepMind 2016]*1 GTSophy [Sony AI 2022]*2
*1: “Mastering the game of Go with deep neural networks and tree search”, in Nature 529, 484–489 (2016). https://doi.org/10.1038/nature16961
*2: “Outracing champion Gran Turismo drivers with deep reinforcement learning”, in Nature 602, 223–228 (2022). https://doi.org/10.1038/s41586-021-04357-7
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-29-2048.jpg)
![30
強化学習における Transformer の役割
観測データのエンコード
• 各時刻の観測データに関す
る特徴を抽出
• 時刻間のデータの関係性も
抽出可能
世界モデル
• 行動によって状
態がどう変化す
るかを予測する
行動推定
• 現在の観測や過去の履歴をもとに、
目標達成に適した行動を推定
*1: “A Survey on Transformers in Reinforcement Learning”, in Transactions on Machine Learning Research 2023. https://arxiv.org/pdf/2301.03044
[W. Li et al., 2023]*1 より
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-30-2048.jpg)
![31
Decision Transformer [L. Chen et al., 2021]*1
• 与えられた報酬和を実現するような行動を推定するように方策を学習
• GPT 構造のモデルを使用し、過去の観測や行動から、自己回帰的に行動を推定
• 学習には事前に収集したデータセットを使用する (オフライン強化学習)
return-to-go
• 現在の時刻以降に取るべき報酬和
過去の観測や行動から今の時刻で取
るべき行動を推定
*1: “Decision Transformer: Reinforcement Learning via Sequence Modeling”, in NeurIPS 2021 https://arxiv.org/pdf/2106.01345
行動推定
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-31-2048.jpg)
![32
Transformer-based World Model (TWM) [V. Micheli et al., 2023]*1
• Model-based RL における状態予測モデルに Transformer を使用
※ Model-based RL
• 自分がとった行動によって状態がどう変わるかを予測する状態予測モデル (世界モデル) を、
収集したデータを用いて学習する。
• 方策の学習時には状態予測モデルでサンプルしたデータを用いて学習を行う。
*1: “TRANSFORMER-BASED WORLD MODELS ARE HAPPY WITH 100K INTERACTIONS”, in ICLR 2023 https://arxiv.org/pdf/2303.07109
• 𝑜𝑡: 時刻𝑡で得られる観測データ
• 𝑧𝑡, ℎ𝑡: 時刻𝑡での潜在特徴
• 𝑎𝑡: 時刻𝑡取った行動
• 𝑟𝑡: 時刻𝑡で得られる報酬
• 𝛾𝑡: 時刻𝑡での割引率
世界モデル
Transformerの基礎と応用](https://image.slidesharecdn.com/4multimodal-241128034807-ea15e734/75/DeepLearning-Transfomer-4-32-2048.jpg)




YouTube nnabla channelの次の動画で利用したスライドです。 【DeepLearning研修】Transfomerの基礎と応用 --第4回 マルチモーダルへの展開 https://youtu.be/av1IAx0nzvc 【参考文献】 ・Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action https://arxiv.org/pdf/2312.17172 ・A Generalist Agent https://arxiv.org/pdf/2205.06175 ・Flamingo: a Visual Language Model for Few-Shot Learning https://arxiv.org/pdf/2204.14198 ・NExT-GPT: Any-to-Any Multimodal LLM https://arxiv.org/pdf/2309.05519 ・MUTEX: Learning Unified Policies from Multimodal Task Specifications https://arxiv.org/pdf/2309.14320 ・On the Opportunities and Risks of Foundation Models https://arxiv.org/pdf/2108.07258 ・RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE https://arxiv.org/pdf/2205.06175 ・ViNT: A Foundation Model for Visual Navigation https://arxiv.org/pdf/2306.14846 ・Do As I Can and Not As I Say: Grounding Language in Robotic Affordances https://arxiv.org/pdf/2204.01691 ・RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control https://arxiv.org/pdf/2307.15818 ・Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware https://arxiv.org/pdf/2304.13705 ・Open X-Embodiment: Robotic Learning Datasets and RT-X Models https://arxiv.org/pdf/2310.08864 ・【AI技術研修】nnabla-rlによる深層強化学習入門 第1回「深層強化学習とは?」 https://youtu.be/KZ0pwIIBKYU?si=AabrkXkCvNjJjR0R ・Mastering the game of Go with deep neural networks and tree search https://doi.org/10.1038/nature16961 ・Outracing champion Gran Turismo drivers with deep reinforcement learning https://doi.org/10.1038/s41586-021-04357-7 ・A Survey on Transformers in Reinforcement Learning https://arxiv.org/pdf/2301.03044 ・Decision Transformer: Reinforcement Learning via Sequence Modeling https://arxiv.org/pdf/2106.01345 ・TRANSFORMER-BASED WORLD MODELS ARE HAPPY WITH 100K INTERACTIONS https://arxiv.org/pdf/2303.07109






![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]One Model To Learn Them All](https://cdn.slidesharecdn.com/ss_thumbnails/dljp20170714ono-170714005853-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)

![[CVPR2020読み会@CV勉強会] 3D Packing for Self-Supervised Monocular Depth Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/202007043dpackingforself-supervisedmonoculardepthestimation-200704035538-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Making Sense of Vision and Touch: Self-Supervised Learning of Multimod...](https://cdn.slidesharecdn.com/ss_thumbnails/20190802dl-190808102241-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)














