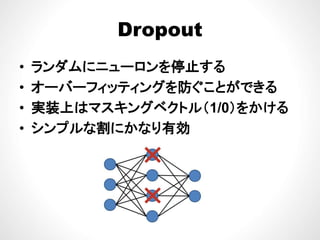
Exercise: nnで遊ぶExercise: nnで遊ぶ
•Tanhの代わりにSigmoid
– nn.Sigmoidを利用するS g o dを利用する
– learningrateは0.1に変更
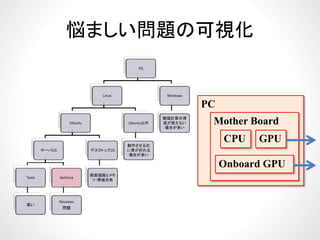
多層にしてみる• 多層にしてみる
– mlp:add()を追加,精度を比較してみる
56.
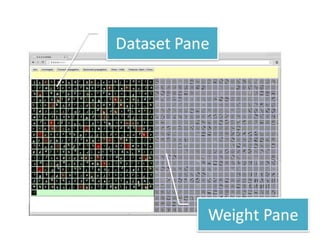
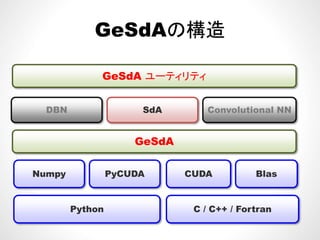
Torch7のSequence
直感的な理解
• Sequenceで入れ物を作る
• nnModuleの組み合わせnn.Moduleの組み合わせ
– Tanh, Linear
S ti lC l ti MM– SpatialConvolutionMM
– ReLU
• nn.Moduleの持つ関数
Forward backward– Forward, backward































![GPUGPU
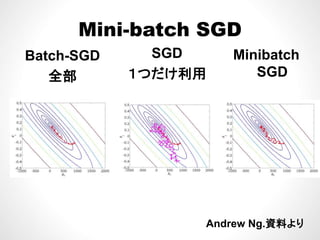
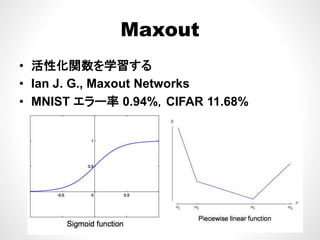
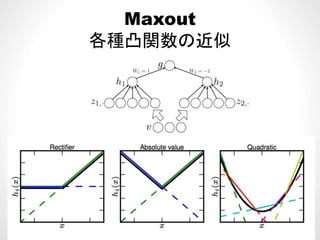
M tの計算時間• Maxoutの計算時間
– on AWS
904m23.683s (15h)
– with GeForce GTX 780 Ti
1482.33s (24m, 36x faster)
• 利用方法
– ~/.theanorc に以下を記述
[global][g ]
device=gpu
floatX = float32](https://image.slidesharecdn.com/jnnslecture2slideshare-150829162511-lva1-app6892/85/Deep-Learning-Implementations-pylearn2-and-torch7-JNNS-2015-36-320.jpg)











![luarocksluarocks
ジ• パッケージ管理ツール
– pip, cpan, pearみたいなものp p, cpa , pea みた なもの
• 各種のパッケージが公開されている
i i– image, csvigo
• Deep Learning系パッケージp g
– nn, unsup, dp
• Usage• Usage
$ luarocks install [package]](https://image.slidesharecdn.com/jnnslecture2slideshare-150829162511-lva1-app6892/85/Deep-Learning-Implementations-pylearn2-and-torch7-JNNS-2015-49-320.jpg)


















































![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)











![[ML15]Class Cat佐々木さん「いち早く人工知能テクノロジーを取り入れた製品・サービスを市場に展開するには?」](https://cdn.slidesharecdn.com/ss_thumbnails/classcatml15-20170226-170306025120-thumbnail.jpg?width=640&height=640&fit=bounds)











