Recommended
PDF
PDF
PDF
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
PPTX
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
PDF
Tech-Circle #18 Pythonではじめる強化学習 OpenAI Gym 体験ハンズオン
PDF
PDF
カスタムSIで使ってみよう ~ OpenAI Gym を使った強化学習
PPTX
最新の多様な深層強化学習モデルとその応用(第40回強化学習アーキテクチャ講演資料)
PDF
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
PDF
PDF
PPTX
PPTX
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
PDF
PDF
PDF
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
PDF
PDF
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
PDF
最近のディープラーニングのトレンド紹介_20200925
PPTX
PPTX
PDF
PDF
More Related Content
PDF
PDF
PDF
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
PPTX
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
PDF
Tech-Circle #18 Pythonではじめる強化学習 OpenAI Gym 体験ハンズオン
PDF
PDF
カスタムSIで使ってみよう ~ OpenAI Gym を使った強化学習
PPTX
最新の多様な深層強化学習モデルとその応用(第40回強化学習アーキテクチャ講演資料)
What's hot
PDF
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
PDF
PDF
PPTX
PPTX
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
PDF
PDF
PDF
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
PDF
PDF
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
PDF
最近のディープラーニングのトレンド紹介_20200925
PPTX
PPTX
Viewers also liked
PDF
PDF
PPTX
PDF
PPTX
PDF
CVPR2016読み会 Sparsifying Neural Network Connections for Face Recognition
PDF
Stochastic Variational Inference
PDF
On the Dynamics of Machine Learning Algorithms and Behavioral Game Theory
PDF
PDF
PPTX
Greed is Good: 劣モジュラ関数最大化とその発展
PDF
sublabel accurate convex relaxation of vectorial multilabel energies
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~
PDF
PDF
PDF
PPTX
Fractality of Massive Graphs: Scalable Analysis with Sketch-Based Box-Coverin...
PDF
Practical recommendations for gradient-based training of deep architectures
PDF
PPTX
多項式あてはめで眺めるベイズ推定�~今日からきみもベイジアン~�
Similar to 強化学習その2
PDF
PDF
PDF
PDF
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
PPTX
PDF
[Dl輪読会]introduction of reinforcement learning
PDF
PDF
Gunosyデータマイニング研究会 #118 これからの強化学習
DOCX
PDF
Computational Motor Control: Reinforcement Learning (JAIST summer course)
PDF
PDF
PPTX
【輪読会】Braxlines: Fast and Interactive Toolkit for RL-driven Behavior Engineeri...
PDF
Top-K Off-Policy Correction for a REINFORCE Recommender System
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
PDF
分散型強化学習手法の最近の動向と分散計算フレームワークRayによる実装の試み
PPTX
Batch Reinforcement Learning
PDF
PPTX
データサイエンス勉強会~機械学習_強化学習による最適戦略の学習
PPTX
More from nishio
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
首都大学東京「情報通信特別講義」2016年西尾担当分
PPTX
PDF
PDF
PDF
PDF
Wifiにつながるデバイス(ESP8266EX, ESP-WROOM-02, ESPr Developerなど)
PDF
PDF
「ネットワークを作ることで�イノベーションを加速」�ってどういうこと?
PDF
PDF
強化学習その2 1. 強化学習 その2
2017-01-26 @ 機械学習勉強会
サイボウズ・ラボ 西尾泰和
関連スライド一覧 https://github.com/nishio/reinforcement_learning
2017-02-24 加筆
2. 3. 4. Sutton & Barto の新作
draftが読める。目次を一部紹介:
第1部: Tabular Solution Methods
6 Temporal-Difference Learning
8 Planning and Learning with Tabular Methods
第2部: Approximate Solution Methods
12 Eligibility Traces
13 Policy Gradient Methods
第3部: Looking Deeper
16 Applications and Case Studies
16.6 Human-Level Video Game Play
16.7 Mastering the Game of Go
16.8 Personalized Web Services
4
https://webdocs.cs.ualberta.ca/~sutton/book/the-book-2nd.html
5. 6. 7. 今後の予定
第7回 2.3 逆強化学習
第8回 2.4 経験強化型学習
2.5 群強化学習(飛ばします)
第9回 2.6 リスク考慮型強化学習
2.7 複利型強化学習(飛ばします)
第10回
3 強化学習の工学応用
3.3 対話処理における強化学習
7
8. 9. 10. 11. 12. 環境をMDPで記述する
状態空間 𝒮 = 𝑠1, 𝑠2, … , 𝑠 𝑁
行動空間 𝒜(𝑠) = {𝑎1, 𝑎2, … , 𝑎 𝑀}
初期状態分布 𝑃0
状態遷移確率 𝑃(𝑠′
|𝑠, 𝑎)
報酬関数 𝑟(𝑠, 𝑎, 𝑠′)
時刻tの値 𝑆𝑡, 𝐴 𝑡, 𝑅𝑡
12
13. 14. 15. 16. 17. 18. 19. モンテカルロで状態価値を求める
状態価値
𝑉 𝑠 = 𝔼[𝐺𝑡|𝑆𝑡 = 𝑠]
をどうすれば求められるか?
適当に試行錯誤して、得られた観測データの
平均値を取ればよい。*
…だけどこの方法は計算コストが大きい。
もっといい方法があるのでそれを見よう。
19
* ゲームの思考エンジンで「各局面からランダムにプレイして各手の勝率を求める」時
これは行動価値関数をこの方法で求めることに相当する。
20. Vを変形
𝑉 𝑠 = 𝔼 𝐺𝑡 𝑆𝑡 = 𝑠
= 𝔼[𝑅𝑡+1 + 𝛾𝑅𝑡+2 + 𝛾2
𝑅𝑡+3 + ⋯ |𝑆𝑡 = 𝑠]
= 𝔼 𝑅𝑡+1 𝑆𝑡 = 𝑠 + 𝛾𝔼[𝑅𝑡+2 + 𝛾𝑅𝑡+3 + ⋯ |𝑆𝑡 = 𝑠]
𝔼 𝑅𝑡+1 𝑆𝑡 = 𝑠 =
𝑎
𝑠′
𝜋 𝑎 𝑠 𝑃 𝑠′
𝑠, 𝑎 𝑟(𝑠, 𝑎, 𝑠′
)
𝔼 𝑅𝑡+2 + 𝛾𝑅𝑡+3 + ⋯ 𝑆𝑡 = 𝑠
=
𝑎
𝑠′
𝜋 𝑎 𝑠 𝑃 𝑠′
𝑠, 𝑎 𝑉(𝑠′
)
20
21. ベルマン方程式
𝑉 𝑠 =
𝑎
𝑠′
𝜋 𝑎 𝑠 𝑃 𝑠′
𝑠, 𝑎 𝑟 𝑠, 𝑎, 𝑠′
+ 𝛾𝑉 𝑠′
同様に
𝑄 𝑠, 𝑎
=
𝑠′
𝑎′
𝑃 𝑠′
𝑠, 𝑎 𝑟 𝑠, 𝑎, 𝑠′
+ 𝛾𝜋 𝑎′
𝑠′
𝑄 𝑠′
, 𝑎′
これをベルマン方程式と呼ぶ。
21
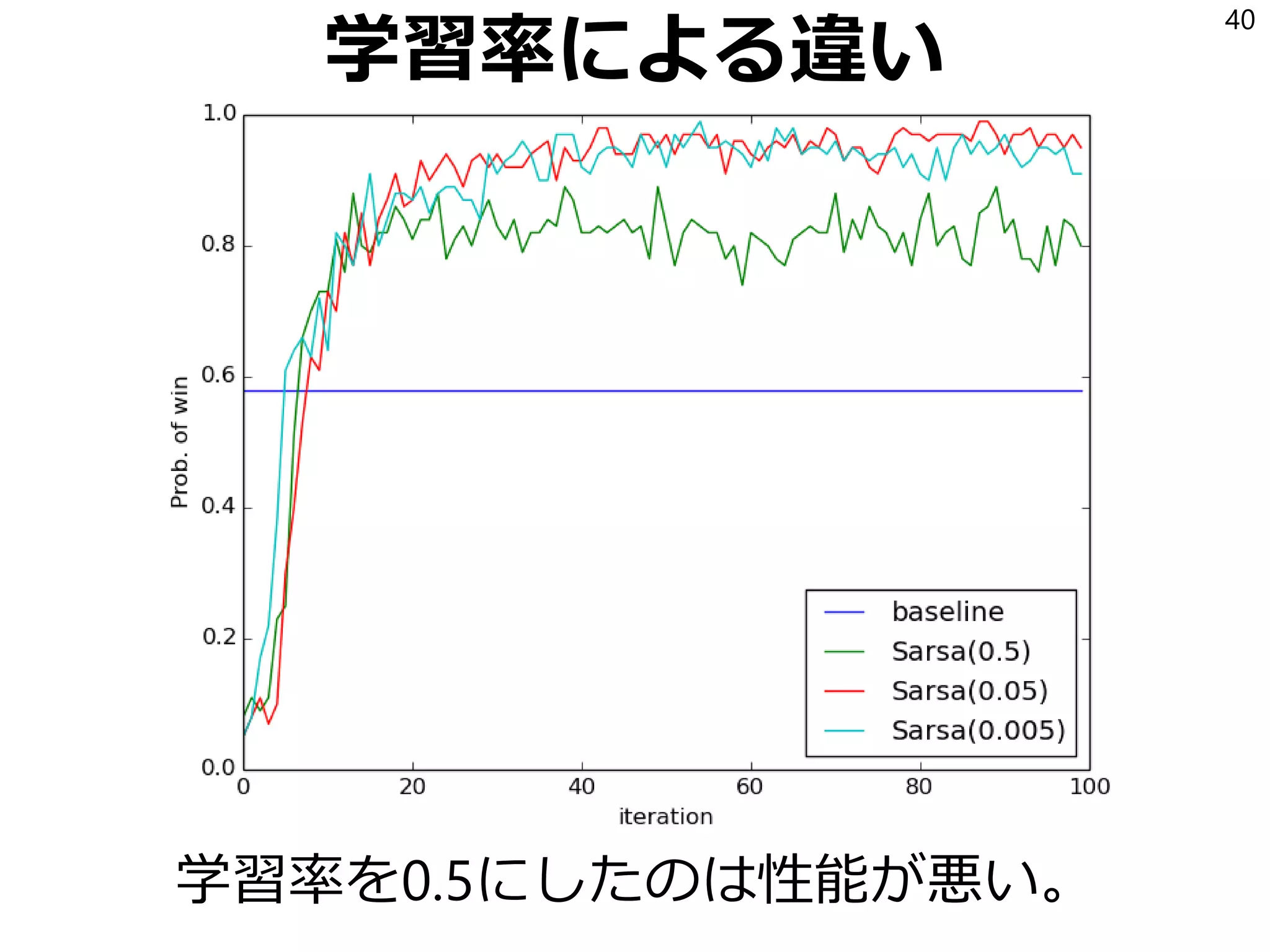
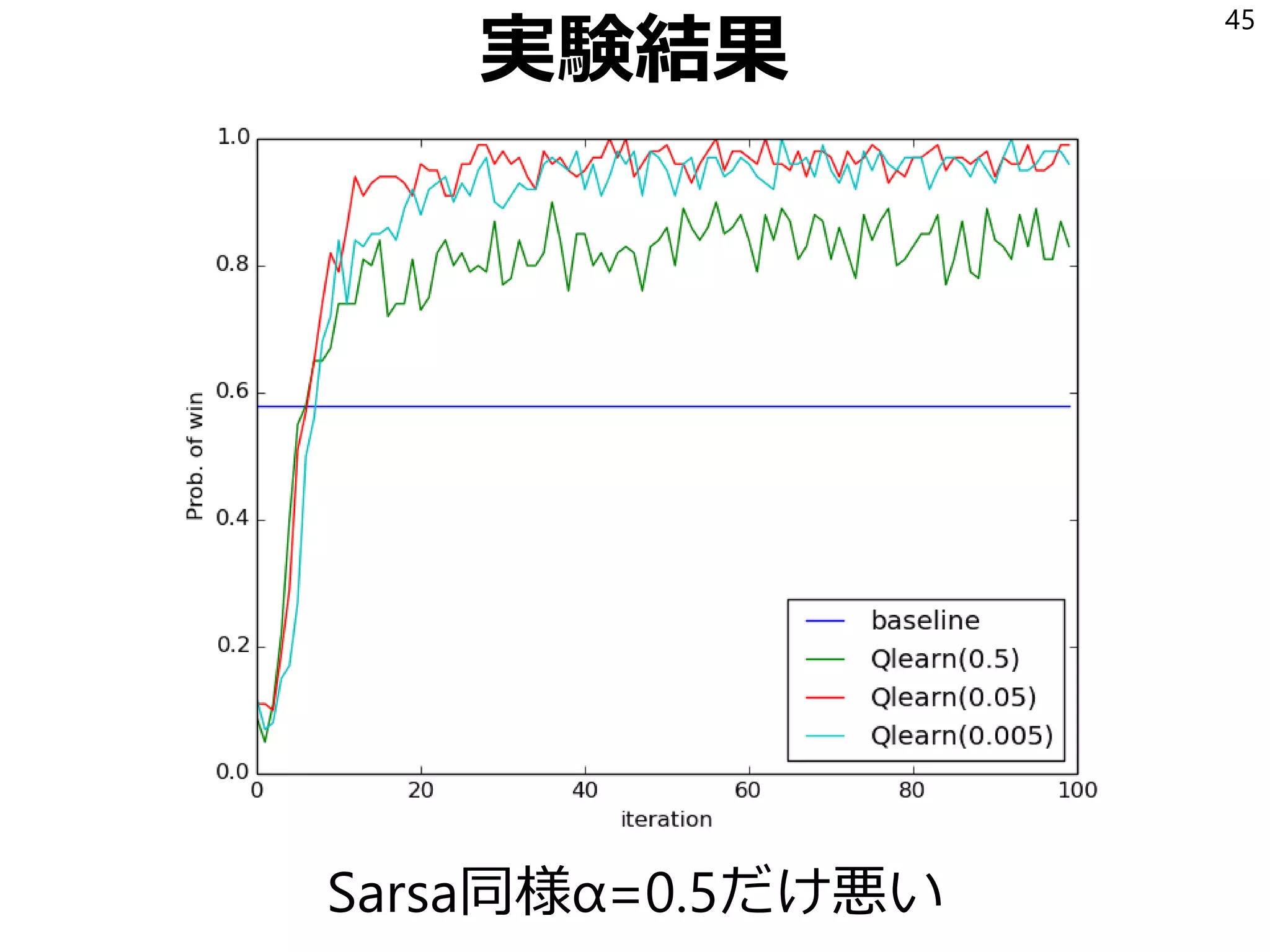
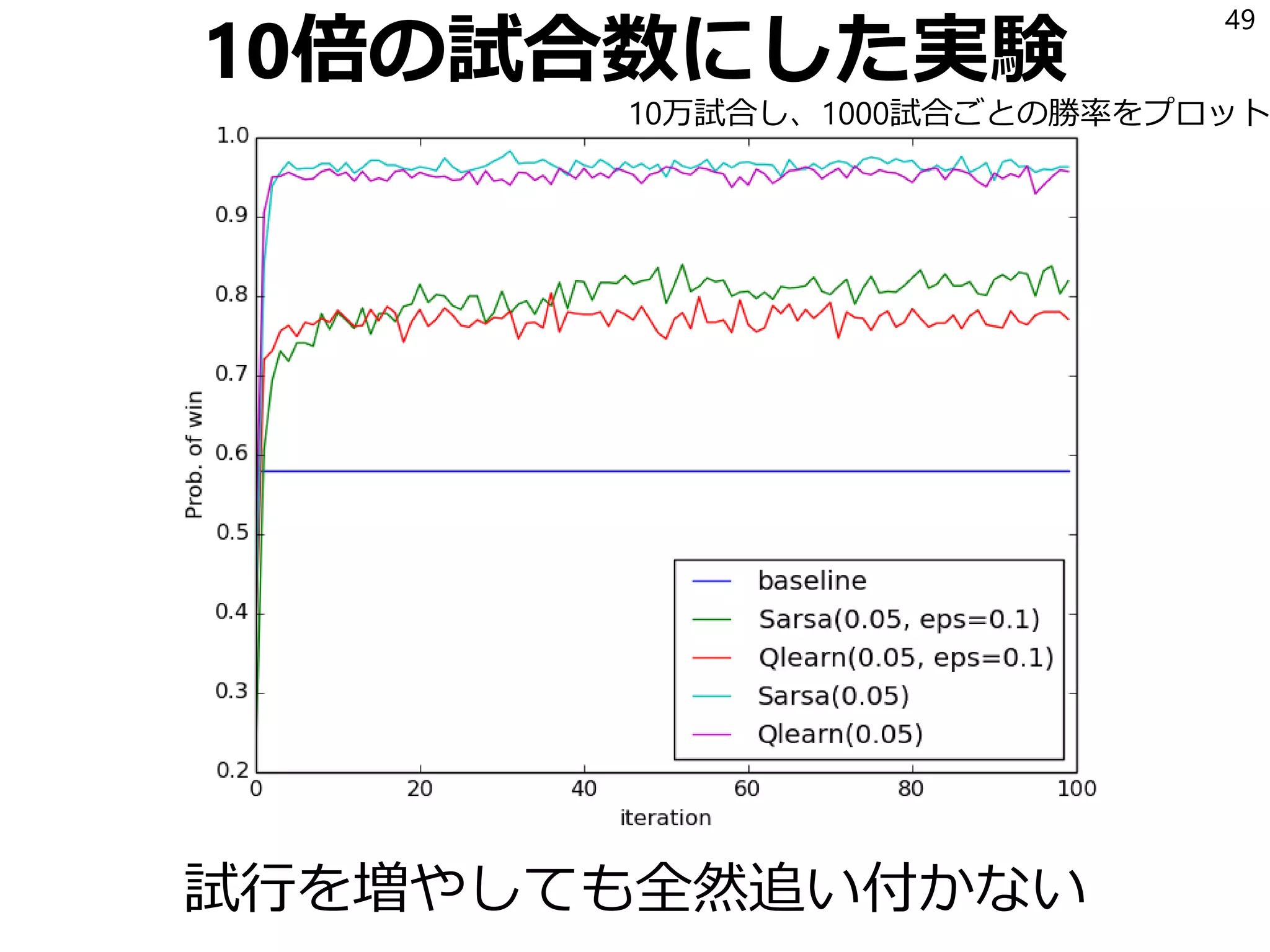
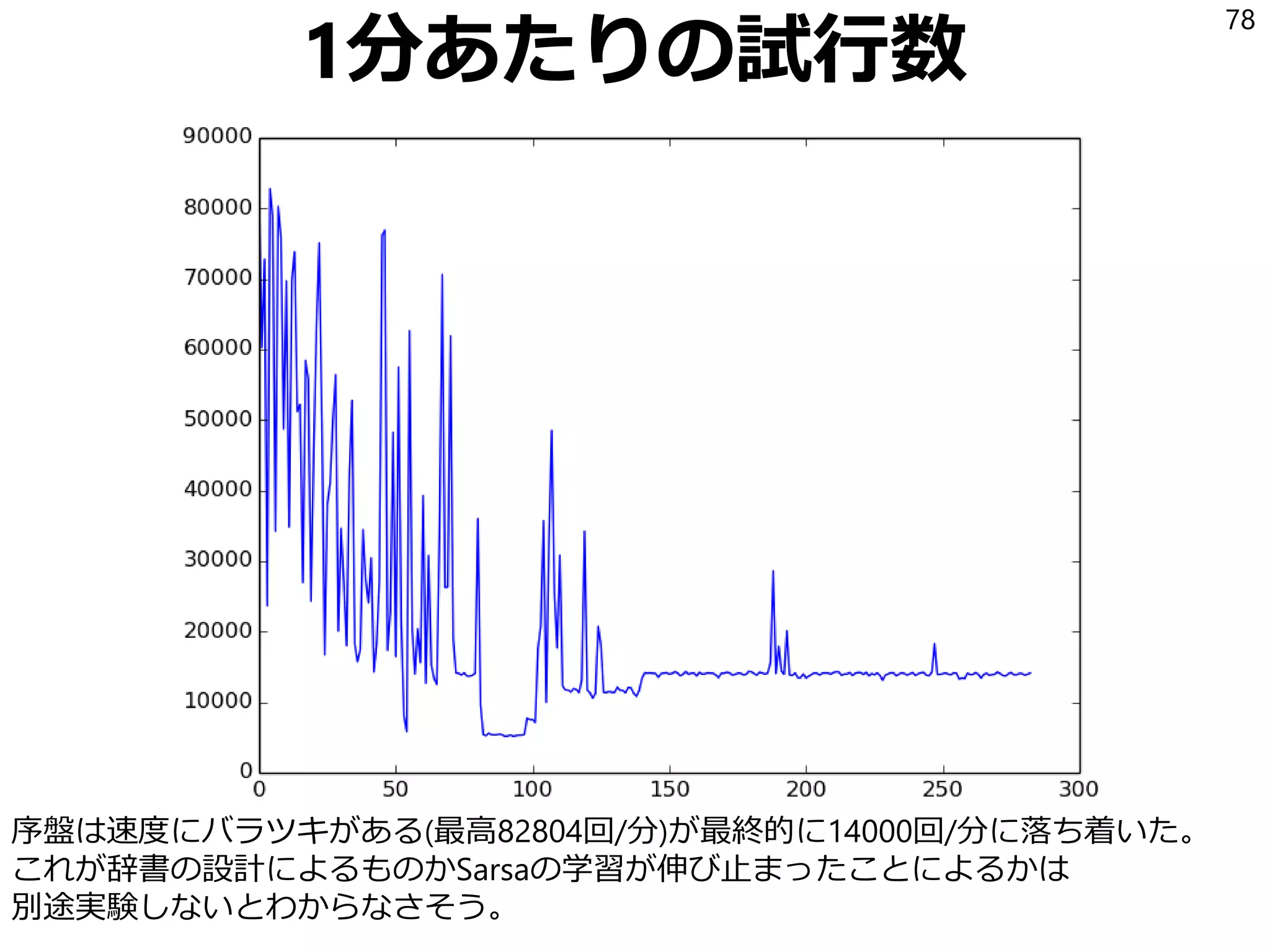
22. 23. Sarsa
SarsaはQを以下の式で更新する学習アルゴリズム:
𝑄 𝑆𝑡, 𝐴 𝑡 ← 𝑄 𝑆𝑡, 𝐴 𝑡 + 𝛼 𝑅𝑡+1 + 𝛾𝑄 𝑆𝑡+1, 𝐴 𝑡+1 − 𝑄 𝑆𝑡, 𝐴 𝑡
𝛼は学習率(0以上1以下の実数)
下記ベルマン方程式ではs’やa’についてsumを取っているが、
それを「実際に出てきたもの」で置き換えて、
「Pやπは未知だけど、実際の観測をたくさん集めれば
Pやπを掛けてsumしたのと同じところに収束するよね」
という発想。
𝑄 𝑠, 𝑎 =
𝑠′
𝑎′
𝑃 𝑠′ 𝑠, 𝑎 𝑟 𝑠, 𝑎, 𝑠′ + 𝛾𝜋 𝑎′ 𝑠′ 𝑄 𝑠′, 𝑎′
23
24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82.

















![「状態の価値」とは?
特定の状態以降の収益の期待値を
「状態価値関数」と呼ぶ。
𝑉 𝑠 = 𝔼[𝐺𝑡|𝑆𝑡 = 𝑠]
特定の状態で特定の行動をした後の
収益の期待値を「行動価値関数」と呼ぶ。
𝑄 𝑠, 𝑎 = 𝔼[𝐺𝑡|𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎]
18
このQがDQNのQ](https://image.slidesharecdn.com/2-170203040322/75/2-18-2048.jpg)
![モンテカルロで状態価値を求める
状態価値
𝑉 𝑠 = 𝔼[𝐺𝑡|𝑆𝑡 = 𝑠]
をどうすれば求められるか?
適当に試行錯誤して、得られた観測データの
平均値を取ればよい。*
…だけどこの方法は計算コストが大きい。
もっといい方法があるのでそれを見よう。
19
* ゲームの思考エンジンで「各局面からランダムにプレイして各手の勝率を求める」時
これは行動価値関数をこの方法で求めることに相当する。](https://image.slidesharecdn.com/2-170203040322/75/2-19-2048.jpg)
![Vを変形
𝑉 𝑠 = 𝔼 𝐺𝑡 𝑆𝑡 = 𝑠
= 𝔼[𝑅𝑡+1 + 𝛾𝑅𝑡+2 + 𝛾2
𝑅𝑡+3 + ⋯ |𝑆𝑡 = 𝑠]
= 𝔼 𝑅𝑡+1 𝑆𝑡 = 𝑠 + 𝛾𝔼[𝑅𝑡+2 + 𝛾𝑅𝑡+3 + ⋯ |𝑆𝑡 = 𝑠]
𝔼 𝑅𝑡+1 𝑆𝑡 = 𝑠 =
𝑎
𝑠′
𝜋 𝑎 𝑠 𝑃 𝑠′
𝑠, 𝑎 𝑟(𝑠, 𝑎, 𝑠′
)
𝔼 𝑅𝑡+2 + 𝛾𝑅𝑡+3 + ⋯ 𝑆𝑡 = 𝑠
=
𝑎
𝑠′
𝜋 𝑎 𝑠 𝑃 𝑠′
𝑠, 𝑎 𝑉(𝑠′
)
20](https://image.slidesharecdn.com/2-170203040322/75/2-20-2048.jpg)




























































![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)






























![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)

































