More Related Content

PDF

PDF
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会 ![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent 
PDF
Sparse estimation tutorial 2014 
PDF

PPTX

PDF

PDF
Similar to [論文解説]A Bayesian Perspective on Generalization and Stochastic Gradient Descent

PPTX

PDF
修士論文発表:「非負値行列分解における漸近的Bayes汎化誤差」 
PPTX

PPTX

PPTX

PPTX

PDF

PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ 
PDF

PDF

PDF
![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Deep Learning 第5章 機械学習の基礎 ![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[PRML] パターン認識と機械学習(第3章:線形回帰モデル) 
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4 
PDF
クラシックな機械学習の入門 4. 学習データと予測性能 ![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models 
PDF
20191006 bayesian dl_1_pub 
PDF

PDF

PDF
Casual learning machine learning with_excel_no3 More from Ryutaro Yamauchi

PPTX
![[DeepLearning論文読み会] Dataset Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/datasetdistillation-181114165952-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DeepLearning論文読み会] Dataset Distillation ![[論文解説]Unsupervised monocular depth estimation with Left-Right Consistency](https://cdn.slidesharecdn.com/ss_thumbnails/unsupervisedmonoculardepthestimation-170809092538-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[論文解説]Unsupervised monocular depth estimation with Left-Right Consistency 
PPTX

PPTX

PPTX
Hybrid computing using a neural network with dynamic [論文解説]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
- 1.
- 2.
本日紹介する論文
• A BayesianPerspective on Generalization and Stochastic
Gradient Descent
• Samuel L. Smith, Quoc V. Le
• https://arxiv.org/abs/1710.06451
- 3.
- 4.
背景
• Zhang etal. (2016)
• DNNはランダムにラベル付けされたデータを丸暗記できる
• ランダムデータを過学習可能なモデルが正しいデータでは汎化すると
いう事実は、モデルの複雑さを評価する従来の汎化理論では説明でき
ない
• 正しいデータにはランダムデータにはない“自然さ”がある?
- 5.
汎化についての経験則
• broad minima> sharp minima
• 曲率の小さいminima(broad minima)は大きいminima(sharp minima)
より汎化する。[Chaudhari et al. (2016)]
• ランダムデータから得られた解はヘッセ行列の最大固有値が大きい。
[Krueger et al. (2017)]
• しかしパラメタの取り方を変えれば汎化性能の高いsharp minimaも作
れる。[Dinh et al. (2017)]
- 6.
- 7.
論文の流れ
1. ベイズ証拠の紹介
• モデルパラメタで周辺化したデータの尤度
𝑃𝑦 𝑥 ; 𝑀 = ∫ 𝑑𝑤 𝑃 𝑦 𝑤, 𝑥 ; 𝑀) 𝑃(𝑤; 𝑀)
• 学習データが事前分布をどれだけ更新しなくてはならないかを意味す
る(ベイズ証拠が大きいほど少ない更新で済む)
2. 線形モデルでベイズ証拠を観察し、汎化性能と関係している
ことを示す。
• 学習セットだけで汎化性能を予測できる!
3. SGDとノイズスケーリング則
- 8.
- 9.
ベイズモデル比較(2)
𝑃 𝑤 𝑦, 𝑥 ; 𝑀) ∝ 𝑃 𝑦 𝑤, 𝑥 ; 𝑀 𝑃 𝑤; 𝑀
=
𝜆
2𝜋
𝑒
− 𝐻 𝑤;𝑀 +𝜆
𝑤2
2
𝐶 𝑤; 𝑀 = 𝐻 𝑤; 𝑀 + 𝜆
𝑤2
2
はL2正則化付き交差エントロピー最小化のコ
スト関数
よって𝐶 𝑤; 𝑀 を最小化する𝑤0は𝑃 𝑤 𝑦 , 𝑥 ; 𝑀)を最大化する。
ベイズ推定の場合、予測の際には
𝑃 𝑦𝑡 𝑥𝑡, 𝑥 , 𝑦 ; 𝑀 = ∫ 𝑑𝑤 𝑃 𝑦𝑡 𝑤, 𝑥𝑡; 𝑀) 𝑃(𝑤| 𝑦 , 𝑥 ; 𝑀)
を解く必要があるが、この積分は𝑤0周りが支配的だと考えられるので、
𝑃 𝑦𝑡 𝑥𝑡; 𝑀 ≈ 𝑃 𝑦𝑡 𝑤0, 𝑥𝑡; 𝑀 と近似する。
- 10.
- 11.
ベイズモデル比較(4)
𝑃 𝑦 𝑥; 𝑀 = 𝑑𝑤 𝑃 𝑦 𝑤, 𝑥 ; 𝑀) 𝑃(𝑤; 𝑀)
=
𝜆
2𝜋
∫ 𝑑𝑤 𝑒−𝐶(𝑤;𝑀)
この積分も𝑤0が支配的だと考えられるので、
𝐶 𝑤; 𝑀 ≈ 𝐶 𝑤0 +
1
2
𝐶′′
𝑤0 𝑤 − 𝑤0
2
とテーラー展開すると(𝐶’ 𝑤0 ≈ 0に注意)
𝑃 𝑦 𝑥 ; 𝑀 ≈ exp − 𝐶 𝑤0 +
1
2
ln
𝐶′′
𝑤0
𝜆
と近似できる。
これは𝐶(𝑤0)および𝑤0における𝐶(𝑤)の曲率が小さい(broad minima)ときベ
イズ証拠が大きくなることを意味する。
- 12.
- 13.
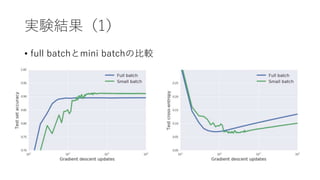
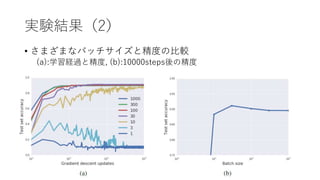
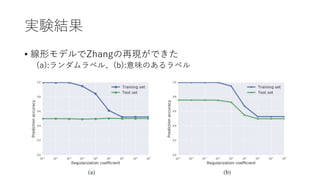
実験
• 線形モデルでベイズ証拠を計算する
モデル:200weights and1 bias
Regularization Coefficient(λ)を変化させながらベイズ証拠と精度の
関係を見る
• データセット
𝑥 :正規分布からサンプリングされた200次元のベクトル
𝑦 : 𝑦𝑖 =
1 𝑥𝑖 > 0
0 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
学習セット:200 examples
評価セット:10000 examples
- 14.
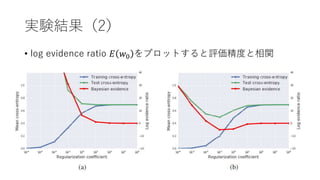
実験(2)
• ランダム出力を返すモデル𝑃 𝑦𝑥 ; 𝑁𝑈𝐿𝐿 =
1
𝑛
𝑁
= 𝑒−𝑁𝑙𝑛(𝑛)
とベイズ証拠を比較
𝑃 𝑦 𝑥 ; 𝑀
𝑃 𝑦 𝑥 ; 𝑁𝑈𝐿𝐿
= 𝑒−𝐸(𝑤0)
ただし𝐸 𝑤0 = 𝐶 𝑤0 +
1
2
𝑖=1
𝑃
ln(
𝜆𝑖
𝜆
) − 𝑁𝑙𝑛(𝑛)
• 𝐸 𝑤0 <0のときランダムよりマシ
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.




![汎化についての経験則
• broad minima > sharp minima
• 曲率の小さいminima(broad minima)は大きいminima(sharp minima)
より汎化する。[Chaudhari et al. (2016)]
• ランダムデータから得られた解はヘッセ行列の最大固有値が大きい。
[Krueger et al. (2017)]
• しかしパラメタの取り方を変えれば汎化性能の高いsharp minimaも作
れる。[Dinh et al. (2017)]](https://image.slidesharecdn.com/0123bayes-180123100528/85/A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-5-320.jpg)










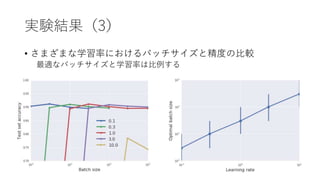
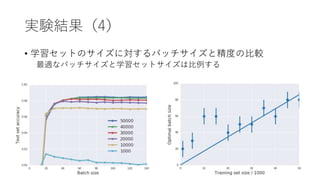
![SGDと汎化
• ベイズ証拠を最大化するためにベイズではノイズを加える
[Mandt et al., 2017; Welling & Teh, 2011]
• SGDでも同じことが起こっていると考えられる
• バッチサイズを大きくするとノイズが減るので汎化性能が下がる](https://image.slidesharecdn.com/0123bayes-180123100528/85/A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-18-320.jpg)