Downloaded 257 times




![Deep Learning: Why for NLP ?
• Beat state of the art
– Language Modeling (Mikolov et al. 2011) [WSJ AR task]
– Speech Recognition (Dahl et al. 2012, Seide et al 2011;
following Mohammed et al. 2011)
– Sentiment Classification (Socher et al. 2011)
– MNIST hand-written digit recognition (Ciresan et al.
2010)
– Image Recognition (Krizhevsky et al. 2012) [ImageNet]
5](https://image.slidesharecdn.com/deeplearningfornlp-151008043922-lva1-app6892/85/Deep-learning-for-nlp-5-320.jpg)
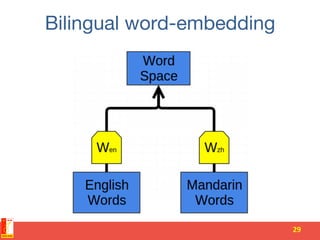
![Language semantics
• What is the meaning of a word?
(Lexical semantics)
• What is the meaning of a sentence?
([Compositional] semantics)
• What is the meaning of a longer piece of
text?
(Discourse semantics)
6](https://image.slidesharecdn.com/deeplearningfornlp-151008043922-lva1-app6892/85/Deep-learning-for-nlp-6-320.jpg)

![One-hot encoding
• The one-hot vector of an ID is a vector filled with 0s, except
for a 1at the position associated with the ID
– for vocabulary size D=10, the one-hot vector of word ID w=4 is e(w)
= [ 0 0 0 1 0 0 0 0 0 0 ]
• A one-hot encoding makes no assumption about word
similarity
• All words are equally different from each other
8](https://image.slidesharecdn.com/deeplearningfornlp-151008043922-lva1-app6892/85/Deep-learning-for-nlp-8-320.jpg)



























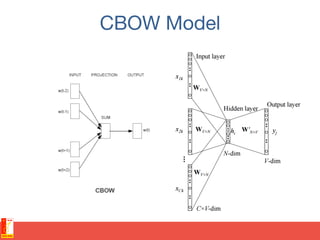

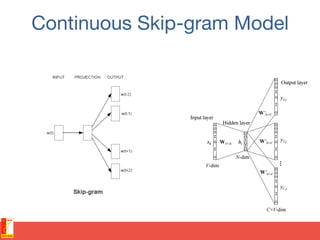









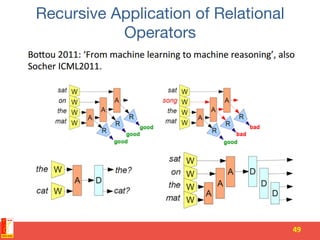

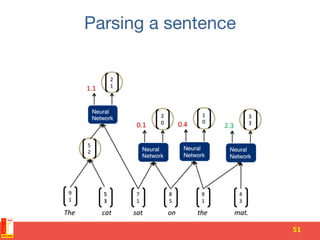











![N-gram models
• An n-gram is a sequence of n words
– unigrams(n=1):’‘is’’,‘‘a’’,‘‘sequence’’,etc.
– bigrams(n=2): [‘‘is’’,‘‘a’’], [‘’a’’,‘‘sequence’’],etc.
– trigrams(n=3): [‘’is’’,‘‘a’’,‘‘sequence’’],
[‘‘a’’,‘‘sequence’’,‘‘of’’],etc.
• n-gram models estimate the conditional from n-
grams counts
• The counts are obtained from a training corpus (a
dataset of word text)
63](https://image.slidesharecdn.com/deeplearningfornlp-151008043922-lva1-app6892/85/Deep-learning-for-nlp-63-320.jpg)

This document provides an overview of deep learning techniques for natural language processing (NLP). It discusses some of the challenges in language understanding like ambiguity and productivity. It then covers traditional ML approaches to NLP problems and how deep learning improves on these approaches. Some key deep learning techniques discussed include word embeddings, recursive neural networks, and language models. Word embeddings allow words with similar meanings to have similar vector representations, improving tasks like sentiment analysis. Recursive neural networks can model hierarchical structures like sentences. Language models assign probabilities to word sequences.












































































![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)









