Downloaded 56 times




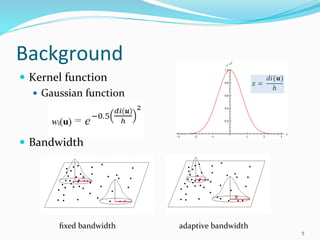
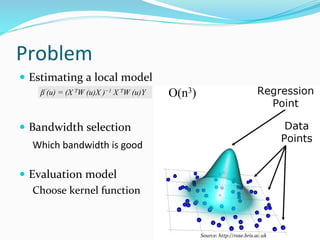
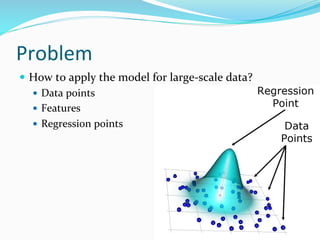






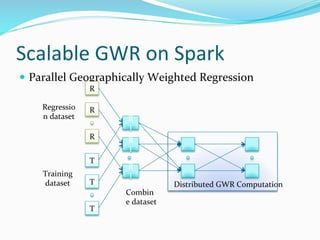



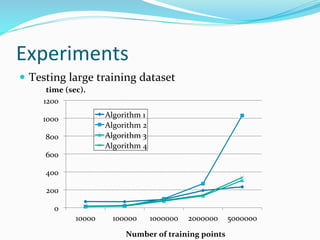
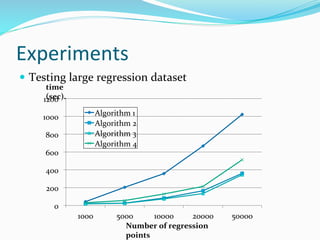
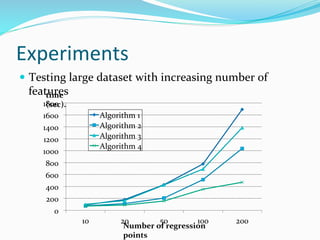
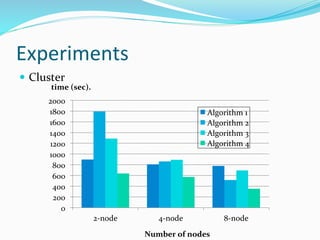




The document discusses the implementation of geographically weighted regression (GWR) using scalable methods on Apache Spark to handle large-scale spatial data. It presents an overview of GWR, challenges in bandwidth selection, and three approaches for its scaling, along with performance evaluation through experiments on a cloud cluster. The findings highlight the effectiveness of using Spark for distributed GWR, with implications for future enhancements and open-source development.














































!["Year of the Selfie" [INFOGRAPHIC]](https://cdn.slidesharecdn.com/ss_thumbnails/selfieinfographic-140212032727-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)






